1.DataX
DataX 是阿里云 DataWorks数据集成 的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX 实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS, databend 等各种异构数据源之间高效的数据同步功能。
2.DataX下载地址
下载地址:https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202303/datax.tar.gz
如果以上连接不可用, 可以访问以下地址DataX下载页找到如下图所示连接进行下载
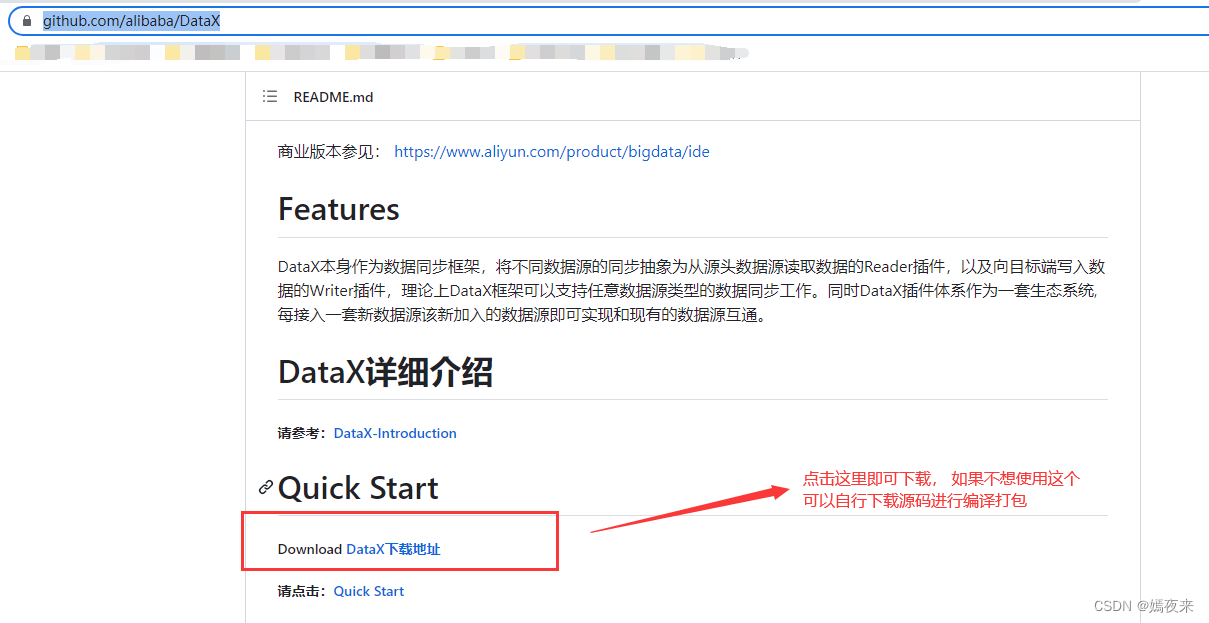
3.DataX数据源支持
DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入,目前支持数据如下图
| 类型 | 数据源 | Reader(读) | Writer(写) | 文档 |
| RDBMS 关系型数据库 | MySQL | √ | √ | 读 、写 |
| Oracle | √ | √ | 读 、写 | |
| OceanBase | √ | √ | 读 、写 | |
| SQLServer | √ | √ | 读 、写 | |
| PostgreSQL | √ | √ | 读 、写 | |
| DRDS | √ | √ | 读 、写 | |
| Kingbase | √ | √ | 读、写 | |
| 通用RDBMS(支持所有关系型数据库) | √ | √ | 读 、写 | |
| 阿里云数仓数据存储 | ODPS | √ | √ | 读 、写 |
| ADB | √ | 写 | ||
| ADS | √ | 写 | ||
| OSS | √ | √ | 读 、写 | |
| OCS | √ | 写 | ||
| Hologres | √ | 写 | ||
| AnalyticDB For PostgreSQL | √ | 写 | ||
| 阿里云中间件 | datahub | √ | √ | 读 、写 |
| SLS | √ | √ | 读 、写 | |
| 阿里云图数据库 | GDB | √ | √ | 读 、写 |
| NoSQL数据存储 | OTS | √ | √ | 读 、写 |
| Hbase0.94 | √ | √ | 读 、写 | |
| Hbase1.1 | √ | √ | 读 、写 | |
| Phoenix4.x | √ | √ | 读 、写 | |
| Phoenix5.x | √ | √ | 读 、写 | |
| MongoDB | √ | √ | 读 、写 | |
| Cassandra | √ | √ | 读 、写 | |
| 数仓数据存储 | StarRocks | √ | √ | 读 、写 |
| ApacheDoris | √ | 写 | ||
| ClickHouse | √ | 写 | ||
| Databend | √ | 写 | ||
| Hive | √ | √ | 读 、写 | |
| kudu | √ | 写 | ||
| selectdb | √ | 写 | ||
| 无结构化数据存储 | TxtFile | √ | √ | 读 、写 |
| FTP | √ | √ | 读 、写 | |
| HDFS | √ | √ | 读 、写 | |
| Elasticsearch | √ | 写 | ||
| 时间序列数据库 | OpenTSDB | √ | 读 | |
| TSDB | √ | √ | 读 、写 | |
| TDengine | √ | √ | 读 、写 |
4.DataX安装
4.1 环境准备
- Linux系统
- JDK(1.8以上,推荐1.8)
- Python(2或3都可以)
- Apache Maven 3.x (如果是源码编译DataX需要使用)
4.2 安装方式
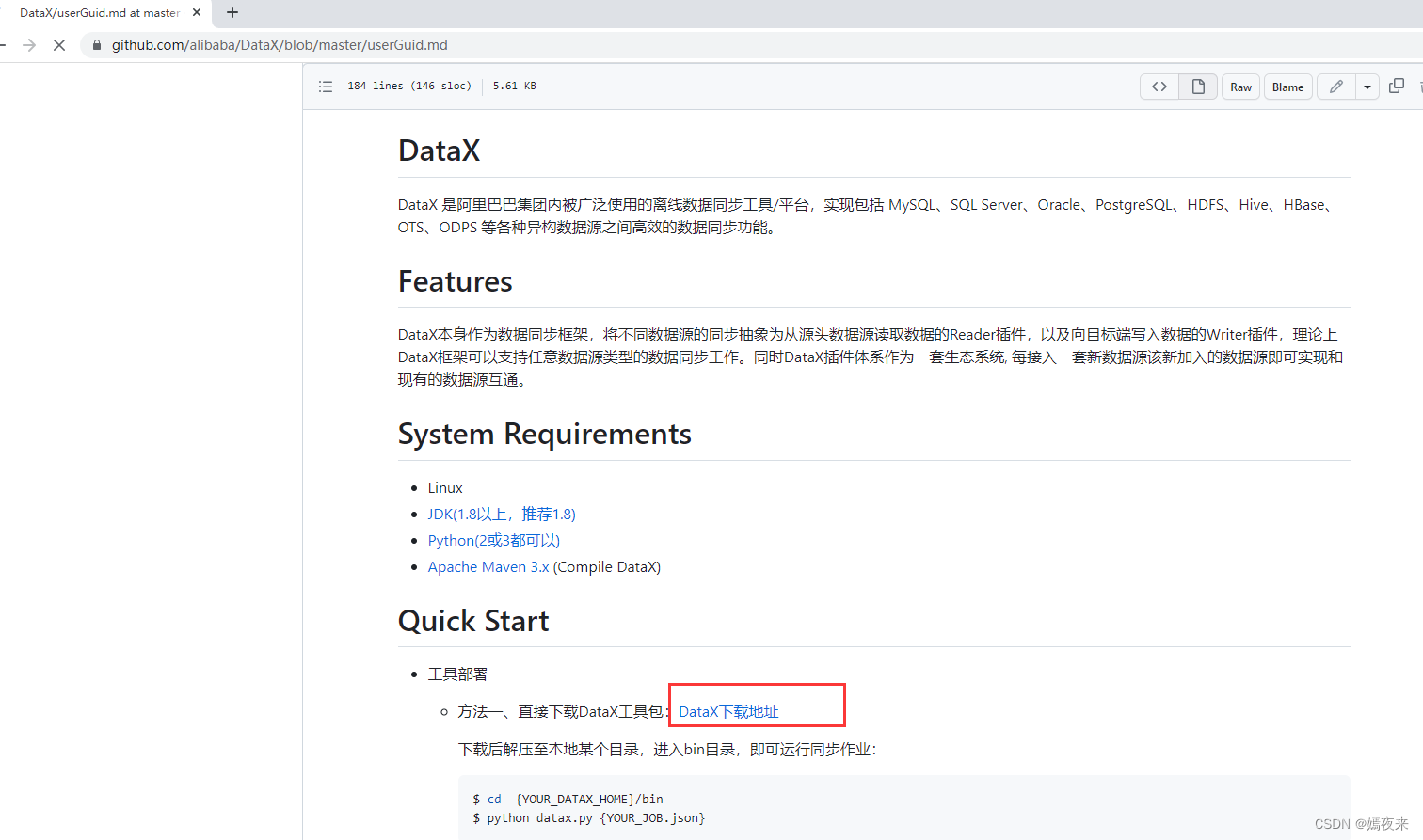
$ cd {
YOUR_DATAX_HOME}/bin
$ python datax.py {
YOUR_JOB.json}
自检脚本:
python {YOUR_DATAX_HOME}/bin/datax.py {YOUR_DATAX_HOME}/job/job.json
- 方法二、下载DataX源码,自己编译:DataX源码
(1)、下载DataX源码:
git clone [email protected]:alibaba/DataX.git
(2)、通过maven打包:
$ cd {DataX_source_code_home}
$ mvn -U clean package assembly:assembly -Dmaven.test.skip=true
打包成功,日志显示如下:
[INFO] BUILD SUCCESS
[INFO] -----------------------------------------------------------------
[INFO] Total time: 08:12 min
[INFO] Finished at: 2015-12-13T16:26:48+08:00
[INFO] Final Memory: 133M/960M
[INFO] -----------------------------------------------------------------
打包成功后的DataX包位于 {DataX_source_code_home}/target/datax/datax/ ,结构如下:
$ cd {DataX_source_code_home}
$ ls ./target/datax/datax/
bin conf job lib log log_perf plugin script tmp
5.实际案例演示
首先需要有两个数据源,一个是原始数据源, 一个是目标数据源, 我智力为了演示方便, 使用的都是MySQL数据库,演示的案列就是把mysql1中saturn-test数据库中的st_student表中的数据迁移到mysql2中saturn-test数据库中的st_student表中
主要就在于job.json文件的编写,这个官方给我们提供好了示例, 我们只要赋值过来改成我们自己的数据库连接配置其实就可以了,
首先我们是从MySQL中读取数据, 所以我们找到关于MYSQL读、写的job的配置应该怎么写,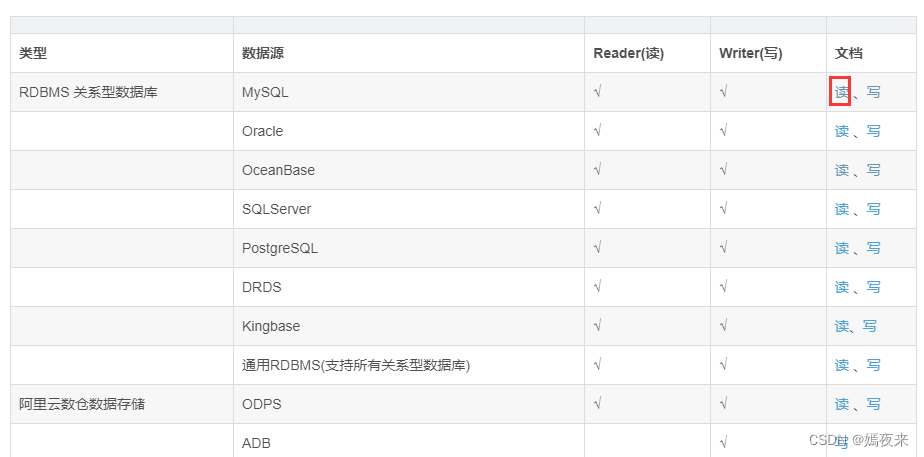
点击MySQL的读、写链接
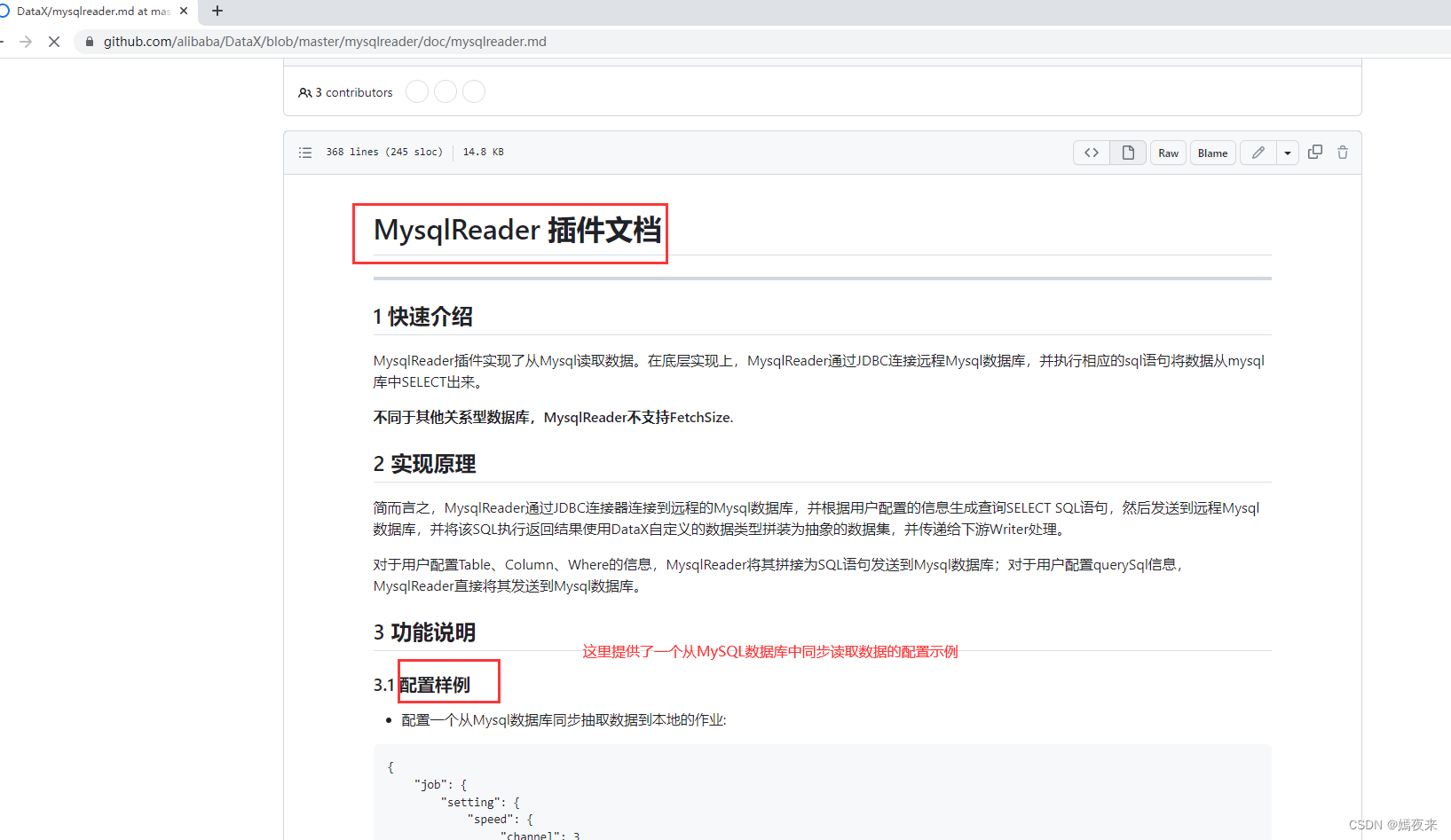
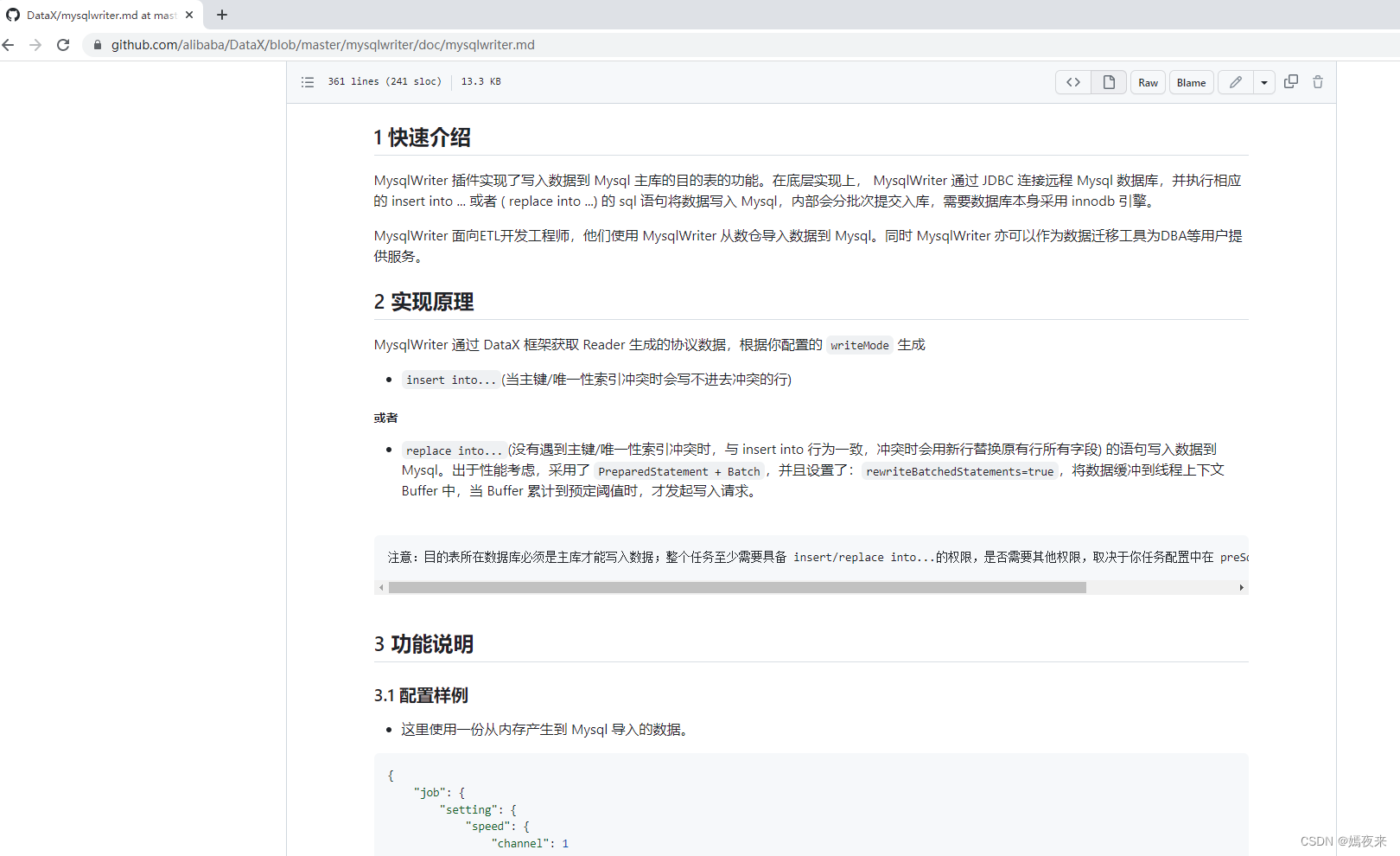
更多关于MysqlReader插件文档请自行阅读查看
更多关于MysqlWriter插件文档请自行阅读查看
示例myjob.json
{
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "数据库用户",
"password": "数据库密码",
"column": [
"stu_id",
"stu_name"
],
"splitPk": "stu_id",
"connection": [
{
"table": [
"st_student"
],
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:3306/test?useUnicode=true&characterEncoding=UTF8"
]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "数据库用户",
"password": "数据库密码",
"column": [
"stu_id",
"stu_name"
],
"session": [
"set session sql_mode='ANSI'"
],
"preSql": [
"delete from st_student"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/test?useUnicode=true&characterEncoding=UTF8",
"table": [
"st_student"
]
}
]
}
}
}
]
}
}
调用datax.py,执行我们刚才定义的myjob.json即可
python /datax安装路径/bin/datax.py /myjob.json所在目录的绝对路径/myjob.json
示例:
python /opt/soft/datax/bin/myjob.json /opt/scripts/datax/myjob.json
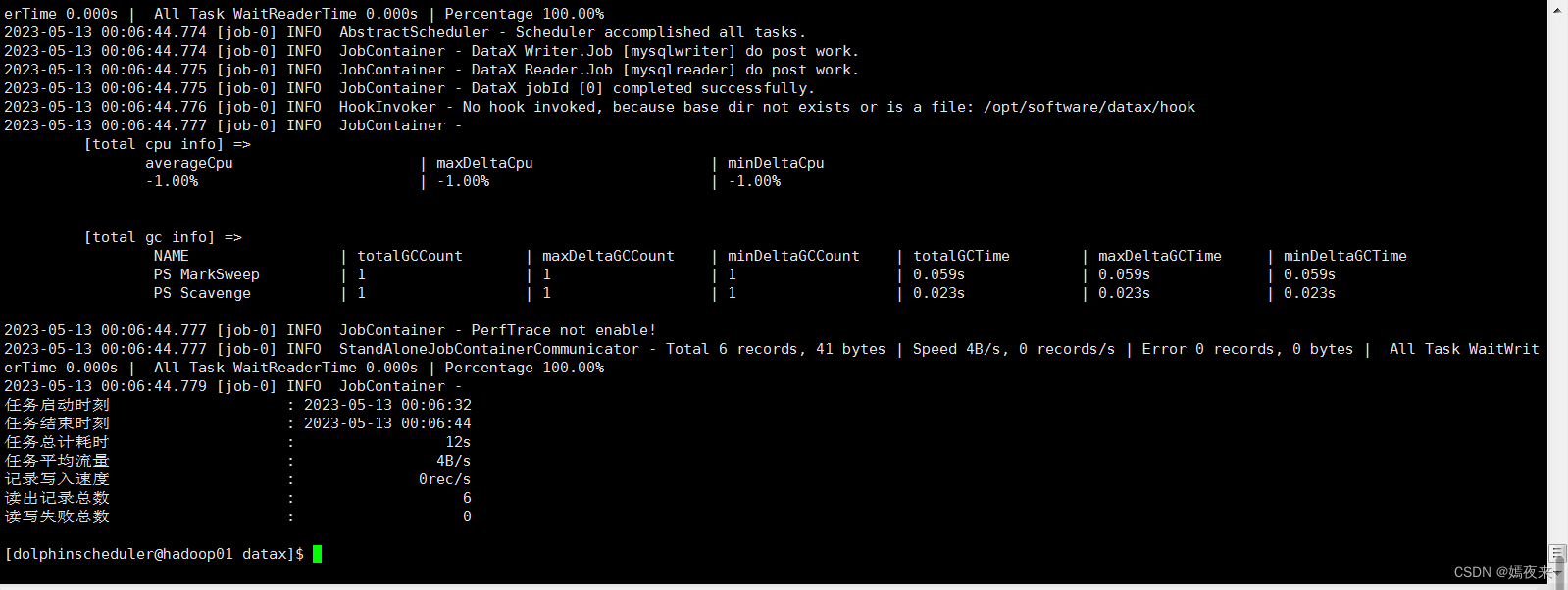
执行成功之后控制台打印如上信息, 如果出现错误,根据错误日志进行错误排查解决重新跑执行就行了。
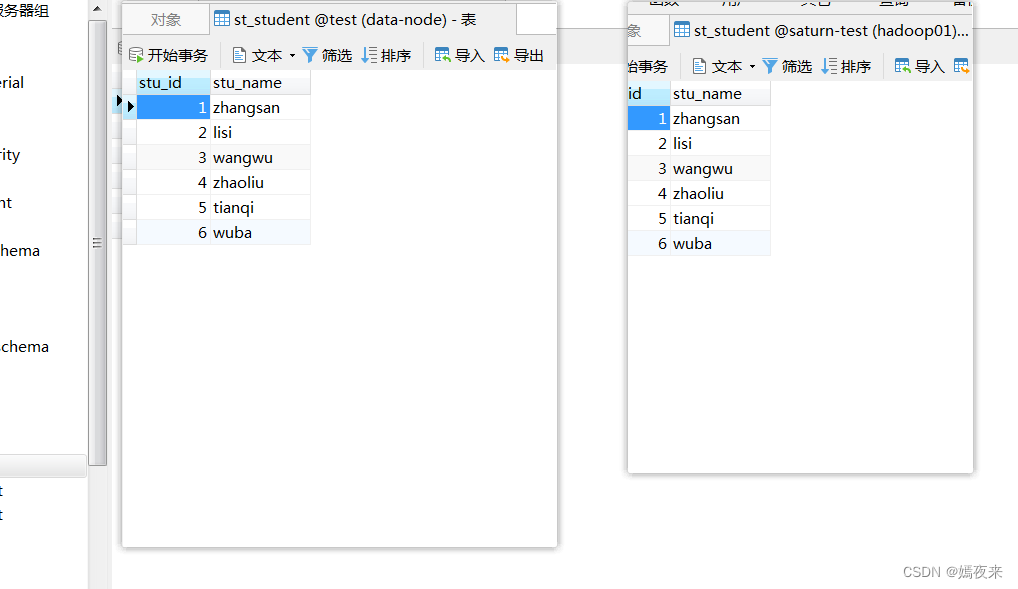
查询两个数据库,发现数据已经迁移同步成功了。datax的使用是不是还挺简单的呢~,多动手,掌握的就会越来越多。