一、介绍
Dropout 是深度学习中用于防止过度拟合的正则化技术。这个概念是由 Hinton 等人提出的。在 2012 年的一篇论文中,它已成为神经网络领域的主要技术,特别是在训练深度网络方面。

在追求稳健的深度学习模型的过程中,dropout 不仅作为一种技术出现,而且作为一种范式来确保泛化性和防止过度拟合的弹性。
二、了解过度拟合
要理解 dropout 的重要性,有必要了解过度拟合。当模型很好地学习训练数据而无法泛化到新的、未见过的数据时,就会发生过度拟合。由于神经网络学习复杂模式的能力很强,这是深度学习中的一个常见问题。
2.1 Dropout技术
Dropout 通过在训练期间随机“丢弃”(即设置为零)该层的多个输出特征来解决过度拟合问题。对于每个训练样本(或批次),某些节点以概率 p “关闭”,这是从业者选择的超参数。这种随机性迫使网络学习更强大的特征,这些特征与其他神经元的许多不同随机子集结合使用非常有用。
2.2 Dropout 是如何运作的
- 随机停用:在每个训练阶段,各个节点要么以一定概率保留
p,要么以概率1-p. - 网络细化:此过程会为每个训练步骤生成一个细化网络。每个细化网络都根据数据进行训练,但不同的节点被丢弃。
- 预测阶段:在测试阶段,不使用dropout。相反,节点的权重会按比例缩小
p,以考虑到比训练期间更多的节点处于活动状态。
2.3 Dropout的好处
- 减少过度拟合:通过防止单元过度共同适应,dropout 迫使模型学习更稳健的特征,这些特征单独对输出做出贡献。
- 模型平均效应:Dropout可以看作是并行训练大量不同架构的神经网络的一种方式。在测试过程中,它类似于对这些网络的预测进行平均。
- 提高模型性能:通常情况下,使用 Dropout 训练的模型在预测性能方面优于未使用 Dropout 训练的模型。
2.4 在神经网络中实现 Dropout
Dropout 实施起来很简单。在大多数深度学习框架中,它涉及添加 dropout 层或指定现有层的 dropout 率。丢失率p是一个可以调整的超参数,通常设置在 0.2 到 0.5 之间。
2.5 挑战和考虑因素
- 调整 Dropout 率:找到最佳 Dropout 率可能很棘手,通常需要交叉验证或其他超参数优化技术。
- 增加训练时间:由于 dropout 在训练的每一步都有效地训练不同的网络,因此可能会导致训练时间增加。
- 并不总是有益的:在某些情况下,尤其是对于小型数据集或在网络的最后几层,丢失可能会损害性能。
三、代码和实践
使用 Python 在深度学习模型中使用 dropout 创建完整示例涉及几个步骤。我们将创建一个综合数据集,构建一个带有 dropout 层的神经网络模型,训练模型,并绘制结果以可视化 dropout 的影响。这是分步指南:
1.导入必要的库
我们将使用 TensorFlow 和 Keras 来构建神经网络。对于数据操作和绘图,我们将使用 NumPy 和 Matplotlib。
2. 生成综合数据集
我们可以使用 中的 make_classification 创建适合二元分类任务的合成数据集。sklearn.datasets
3. 定义神经网络模型
我们将创建一个简单的神经网络模型并包含 dropout 层。丢失率是我们可以调整的超参数。
4. 编译模型
我们将使用优化器、损失函数和要监控的指标来编译模型。
5. 训练模型
我们将在合成数据集上训练模型并对其进行验证。此步骤包括在训练期间使用 dropout。
6. 评估模型
训练后,我们在测试集上评估模型的性能。
7. 绘制结果
我们将绘制训练和验证的准确性和损失以观察 dropout 的影响。
让我们用 Python 来实现这个:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
from tensorflow.keras.optimizers import Adam
# Generate synthetic dataset
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Define the model
model = Sequential([
Dense(64, activation='relu', input_shape=(20,)),
Dropout(0.5),
Dense(64, activation='relu'),
Dropout(0.5),
Dense(1, activation='sigmoid')
])
# Compile the model
model.compile(optimizer=Adam(), loss='binary_crossentropy', metrics=['accuracy'])
# Train the model
history = model.fit(X_train, y_train, epochs=20, batch_size=32, validation_split=0.2)
# Evaluate the model
loss, accuracy = model.evaluate(X_test, y_test)
print(f"Test Accuracy: {accuracy:.4f}")
# Plot training and validation accuracy and loss
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], label='Train Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.title('Model Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], label='Train Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Model Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.tight_layout()
plt.show()Epoch 1/20
20/20 [==============================] - 4s 49ms/step - loss: 0.7149 - accuracy: 0.5828 - val_loss: 0.5333 - val_accuracy: 0.7875
Epoch 2/20
20/20 [==============================] - 0s 10ms/step - loss: 0.5904 - accuracy: 0.6797 - val_loss: 0.4640 - val_accuracy: 0.8438
Epoch 3/20
20/20 [==============================] - 0s 19ms/step - loss: 0.5856 - accuracy: 0.6953 - val_loss: 0.4172 - val_accuracy: 0.8500
Epoch 4/20
20/20 [==============================] - 0s 15ms/step - loss: 0.4815 - accuracy: 0.7688 - val_loss: 0.3814 - val_accuracy: 0.8375
Epoch 5/20
20/20 [==============================] - 0s 12ms/step - loss: 0.4620 - accuracy: 0.7906 - val_loss: 0.3558 - val_accuracy: 0.8438
Epoch 6/20
20/20 [==============================] - 0s 7ms/step - loss: 0.4748 - accuracy: 0.7797 - val_loss: 0.3370 - val_accuracy: 0.8625
Epoch 7/20
20/20 [==============================] - 0s 13ms/step - loss: 0.4065 - accuracy: 0.8234 - val_loss: 0.3219 - val_accuracy: 0.8625
Epoch 8/20
20/20 [==============================] - 0s 11ms/step - loss: 0.4167 - accuracy: 0.8062 - val_loss: 0.3129 - val_accuracy: 0.8562
Epoch 9/20
20/20 [==============================] - 0s 18ms/step - loss: 0.4277 - accuracy: 0.8359 - val_loss: 0.3083 - val_accuracy: 0.8500
Epoch 10/20
20/20 [==============================] - 0s 8ms/step - loss: 0.3836 - accuracy: 0.8297 - val_loss: 0.3026 - val_accuracy: 0.8687
Epoch 11/20
20/20 [==============================] - 0s 16ms/step - loss: 0.3657 - accuracy: 0.8328 - val_loss: 0.2987 - val_accuracy: 0.8687
Epoch 12/20
20/20 [==============================] - 1s 44ms/step - loss: 0.3892 - accuracy: 0.8422 - val_loss: 0.2957 - val_accuracy: 0.8625
Epoch 13/20
20/20 [==============================] - 0s 7ms/step - loss: 0.3956 - accuracy: 0.8438 - val_loss: 0.2939 - val_accuracy: 0.8625
Epoch 14/20
20/20 [==============================] - 0s 10ms/step - loss: 0.3543 - accuracy: 0.8484 - val_loss: 0.2896 - val_accuracy: 0.8687
Epoch 15/20
20/20 [==============================] - 0s 12ms/step - loss: 0.3675 - accuracy: 0.8562 - val_loss: 0.2857 - val_accuracy: 0.8625
Epoch 16/20
20/20 [==============================] - 0s 16ms/step - loss: 0.3413 - accuracy: 0.8609 - val_loss: 0.2829 - val_accuracy: 0.8625
Epoch 17/20
20/20 [==============================] - 0s 9ms/step - loss: 0.3774 - accuracy: 0.8516 - val_loss: 0.2791 - val_accuracy: 0.8625
Epoch 18/20
20/20 [==============================] - 0s 11ms/step - loss: 0.3712 - accuracy: 0.8266 - val_loss: 0.2808 - val_accuracy: 0.8625
Epoch 19/20
20/20 [==============================] - 0s 6ms/step - loss: 0.3705 - accuracy: 0.8766 - val_loss: 0.2762 - val_accuracy: 0.8625
Epoch 20/20
20/20 [==============================] - 0s 9ms/step - loss: 0.3451 - accuracy: 0.8469 - val_loss: 0.2739 - val_accuracy: 0.8625
7/7 [==============================] - 1s 13ms/step - loss: 0.3579 - accuracy: 0.8500
Test Accuracy: 0.8500
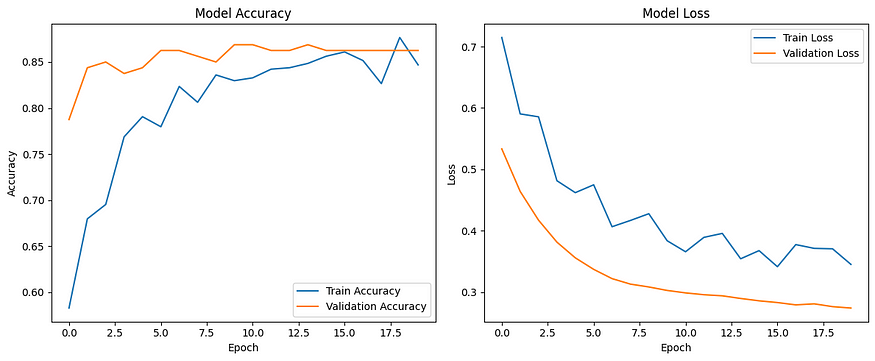
此代码将创建一个两层神经网络,中间有 dropout 层。丢失率设置为 0.5,但您可以尝试使用不同的值。这些图将帮助您了解模型的准确性和损失在训练集和验证集的历元内如何变化。
四、结论
Dropout 是深度学习中一种强大且广泛使用的技术,用于对抗过度拟合。它的简单性和有效性使其成为从业者的宝贵工具。然而,与任何技术一样,它也有其考虑因素,应该明智地使用它作为设计和训练神经网络的更广泛策略的一部分。