Maven依赖导入Tess4j
<!-- https://mvnrepository.com/artifact/net.sourceforge.tess4j/tess4j -->
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>4.5.4</version>
</dependency>
下载Tessdata语言库
https://gitee.com/superaskar/tessdata解压后的文件库
代码实现:
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;
public class ITesseract{
/**
*
* @param srImage 图片路径
* @param ZH_CN 是否使用中文训练库,true-是
* @return 识别结果
*/
public static String FindOCR(String srImage, boolean ZH_CN) {
try {
System.out.println("start");
double start=System.currentTimeMillis();
File imageFile = new File(srImage);
if (!imageFile.exists()) {
return "图片不存在";
}
BufferedImage textImage = ImageIO.read(imageFile);
//Tesseract instance=Tesseract.getInstance();
ITesseract instance = new Tesseract(); // JNA Interface Mapping
instance.setDatapath("D:\\Program Files\\tessdata-master");//设置训练库
if (ZH_CN)
instance.setLanguage("chi_sim");//中文识别
String result = null;
result = instance.doOCR(textImage);
double end=System.currentTimeMillis();
System.out.println("耗时"+(end-start)/1000+" s");
return result;
} catch (Exception e) {
e.printStackTrace();
return "发生未知错误";
}
}
public static void main(String[] args) throws Exception {
String result=FindOCR("C:\\Users\\mycom\\Pictures\\8d7d90385ea742b58fda9d4de1fe3241.png",true);
System.out.println(result);
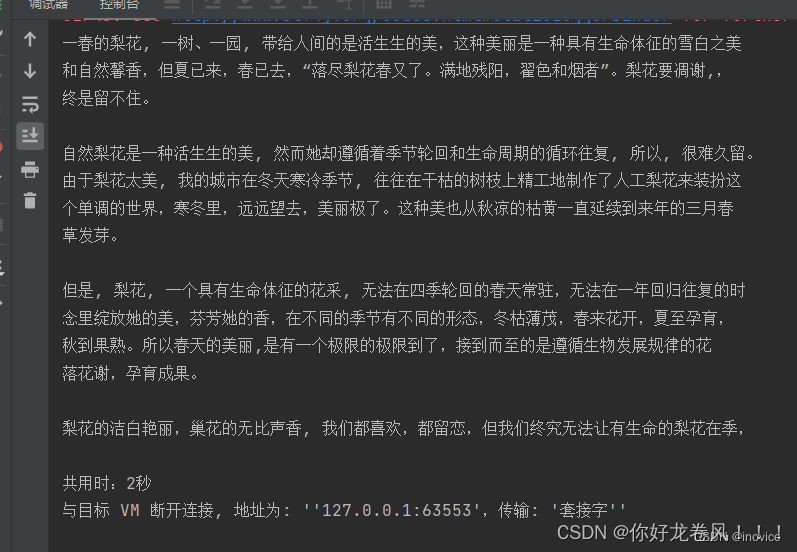
}原图:
识别结果:
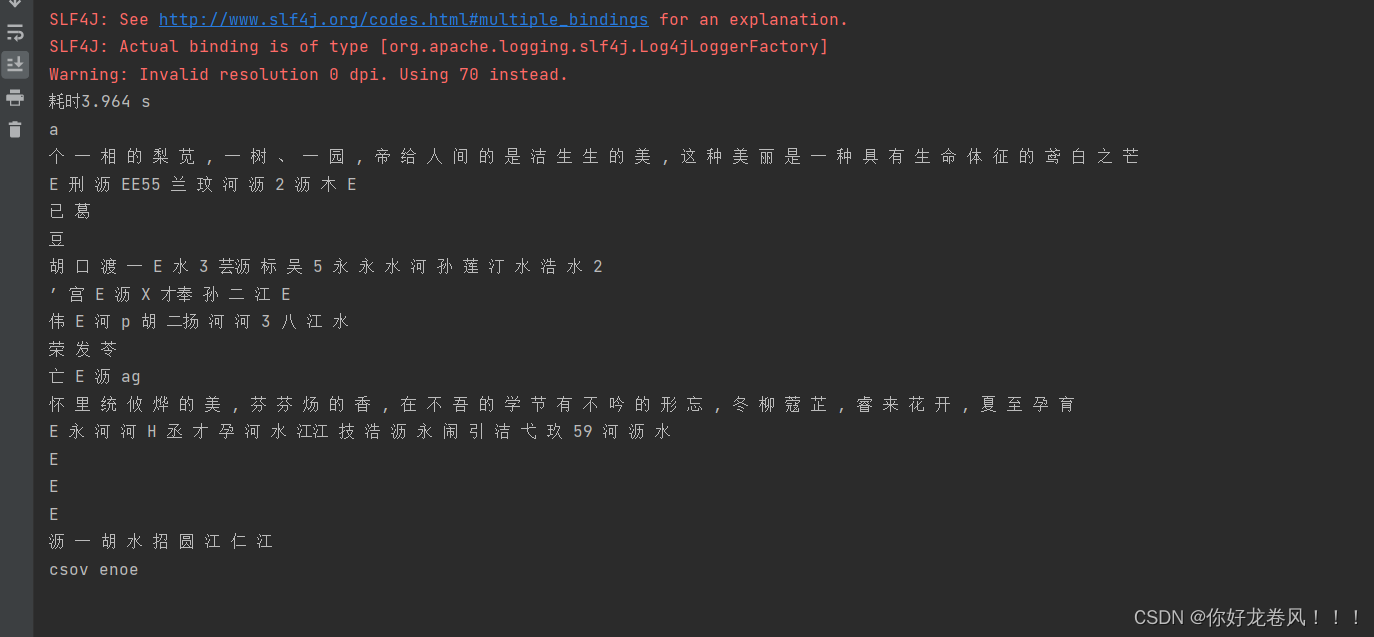
有点低啊
提高识别率: