目录
前言
数据可视化主要旨在借助于图形化手段,清晰有效地传达与沟通信息,能够提高数据分析的效率,能够进行更好地从结果追溯原因,帮助运营决策。
一、赛题介绍
赛题以网络舆情分析为背景,要求选手根据用户的评论来对品牌的议题进行数据分析与可视化。通过这道赛题来引导常用的数据可视化图表,以及数据分析方法,对感兴趣的内容进行探索性数据分析。
二、词云图
1.读取数据
import re # 正则表达式库
import collections # 词频统计库
import numpy as np
import jieba # 结巴分词
import wordcloud # 词云展示库
from PIL import Image # 图像处理库
import matplotlib.pyplot as plt
import pandas as pd
df=pd.read_csv('/earphone_sentiment.csv')
df.head()
2.可视化
# 提取相应类别的数据
posdata = df[df['sentiment_value']==1]
neudata = df[df['sentiment_value']==0]
negdata = df[df['sentiment_value']==-1]
# 去停用词、以posdata为例
words1=''.join(posdata['content'])
pattern = re.compile(u'\t|\n|\.|-|一|:|;|\)|\(|\?|"') # 建立正则表达式匹配模式
string_data1 = re.sub(pattern, '', words1) # 将符合模式的字符串替换
seg_list_exact = jieba.cut(string_data1, cut_all=False)
stop_path =open('/stoplist.txt','r',encoding='utf-8')
remove_words= stop_path.readlines()
remove_words=[x.replace('\n','')for x in remove_words ]
remove_words.append(' ')
object_list = [i for i in seg_list_exact if i not in remove_words] # 将不在去除词列表中的词添加到列表中
word_counts = collections.Counter(object_list) # 对分词做词频统计
#词云图
plt.rcParams['font.sans-serif'] = ['SimSun'] # 修改字体为宋体
mask = np.array(Image.open('/39.jpeg')) # 定义词频背景
wc = wordcloud.WordCloud(
font_path='C:/Windows/Fonts/simhei.ttf', # 设置字体格式
mask=mask, # 设置背景图
max_words=100, # 设置最大显示的词数
max_font_size=100 # 设置字体最大值
)
wc.generate_from_frequencies(word_counts) # 从字典生成词云
image_colors = wordcloud.ImageColorGenerator(mask) # 从背景图建立颜色方案
wc.recolor(color_func=image_colors) # 将词云颜色设置为背景图方案
plt.figure(figsize=(10,8)) #显示图片大小
plt.title('正向词云',fontstyle='oblique',fontsize='30',fontweight='heavy',alpha=0.8)
plt.imshow(wc) # 显示词云
plt.axis('off') # 关闭坐标轴

三、相关性热力图
# 数据透视表
df_pivot_tabel = df.pivot_table(index='sentiment_value', columns='subject', values='sentiment_word',aggfunc=len)
df_pivot_tabel

import seaborn as sns
plt.figure(figsize=(12,10))
sns.heatmap(df_pivot_tabel.corr(),vmax=0.9,linewidths=0.05,cmap="YlGnBu_r",annot=True)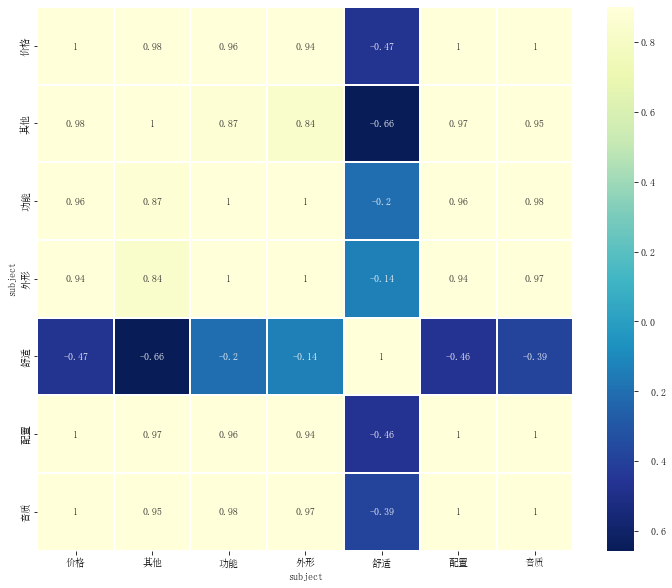
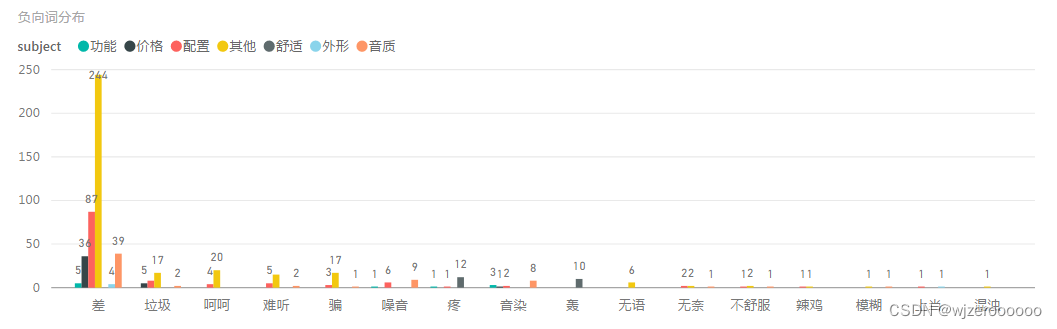
四、不同主题,不同情感,不同情感词可视化
对于需要大量可视化的数据,本人还是比较喜欢用第三方工具实现,更加方便、高效。
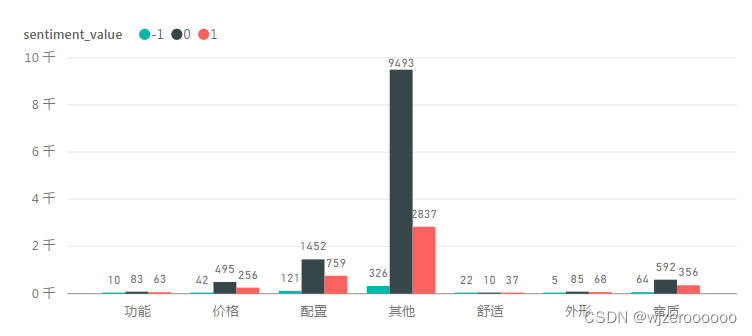
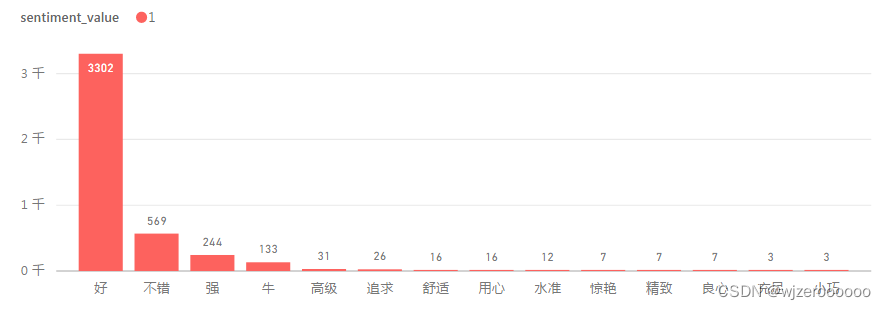
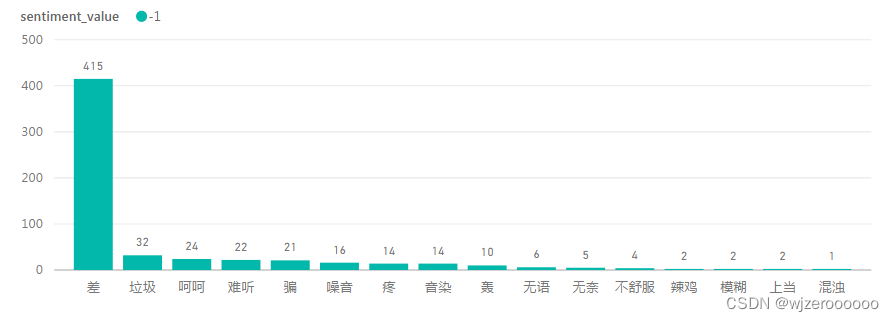

总结
1. 本次比赛是一次不错的学习处理文本的机会,文本也是数据结构的一种,有时候数据的处理不仅仅是结构化的数据,还有可能面临非结构化的数据,多学习一些处理方式只会带来好处。
2. Python可以很好的支持大数据分析、挖掘、机器学习等方面的处理,如果是在处理数据的过程中需要一些可视化来帮助判断的话,用Python实现可视化是一个比较不错的选择,毕竟python也有很多强大的第三方图库,比如matplotlib、seaborn、plotly、pyechart等,但如果是需要对处理后的数据进行批量可视化进行展示,还是建议用power bi、tableau等第三方工具更方便。