GNN
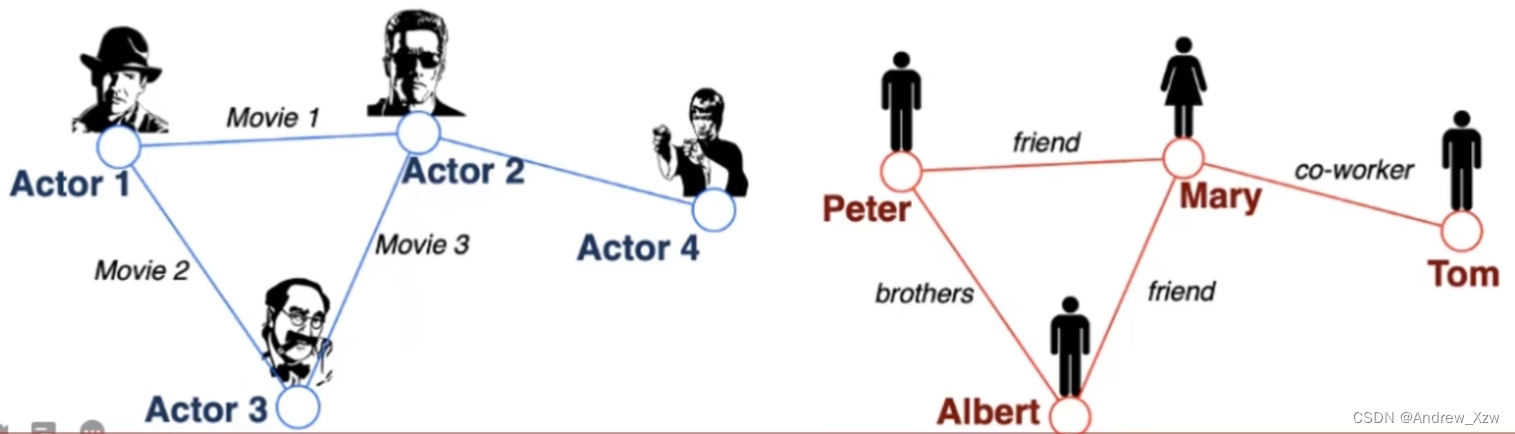
1、什么是图?
图就是表示一些实体(Node点)之间的关系(边Edge)。
V:点,E:边,U:图的整体。

图一般分为两种:有方向的和没方向的图。

神经网络中,最重要的就是如何“重构特征”?图当中也是如此,点有自己的特征,在图当中预测这个人喜欢什么,不仅要考虑他自己,还要考虑他的朋友,和哪些人连接在一起,所以“点”要做一个重构,“边”的特征也需要重构。
最终,预测什么?就是对“点”做分类/回归,对“边”/“图”做分类/回归。
2、邻接矩阵?
2.1图像?
数据是怎么表示为一个图的?
图片怎么表示为一个图?
比如这里:224x224的RGB图像,在输入CNN之前,会表示为1个3通道的Tensor。
从另外一个角度来看,就可以当作一个“图”,每一个像素点就是一个“点”,相邻像素之间的关系就可以表示为两个点之间连着一个边。应该强调,每个像素点和周围的哪些像素点之间是有连接关系的?
下面的示意图,就是把图片中的每一个像素点映射到了“图结构”中的每一个点。
中间的是邻接矩阵(很大的稀疏矩阵,表示点之间的关系,谁和谁连,谁和谁没有关系),比如:0-0这个像素点,就和:1-0,0-1,1-1有连接关系,而计算机是不知道的,就使用“邻接矩阵”,邻接矩阵中对应的位置就标蓝。一共25个像素点,邻接矩阵就表示为25x25(nxn)。
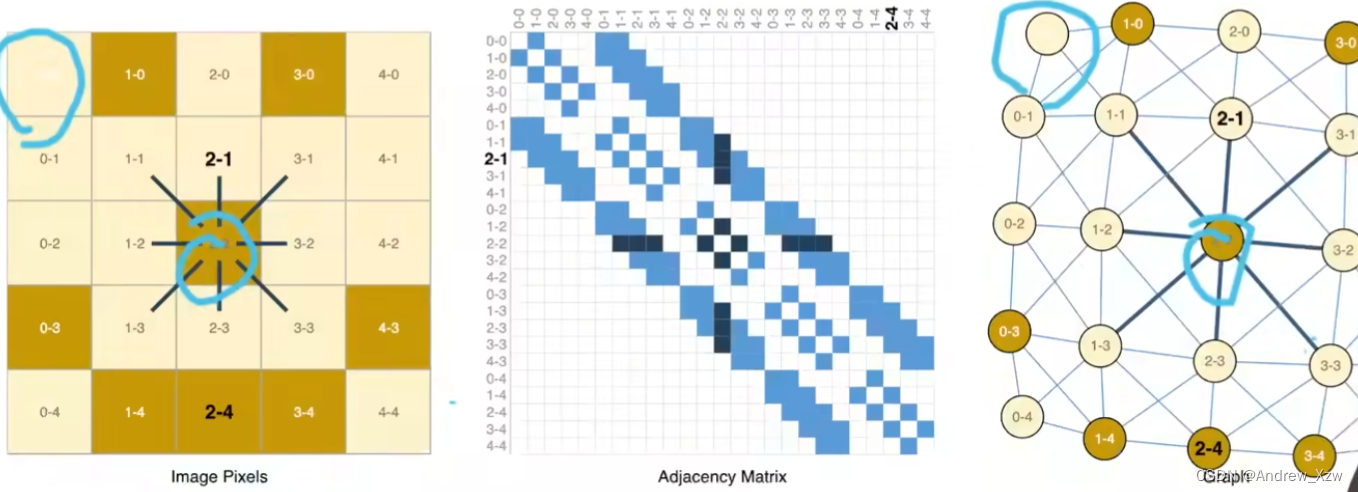
通常使用A表示图的邻接矩阵,构建GNN后,邻接矩阵A也会同每个点的特征X一起作为网络的输入,GNN(A,X)。
2.2文本
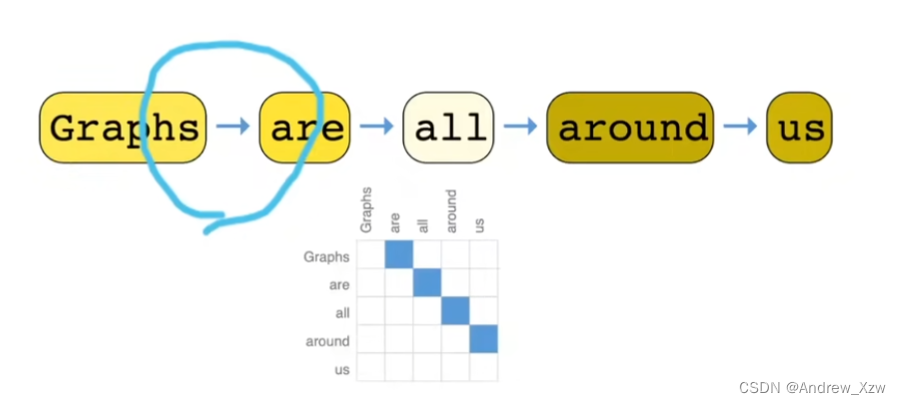
文本怎么表示为一个图?
文本是一个序列,可以将每一次词作为一个顶点,一个词和他的下一个词有1条有向边。
2.3其它
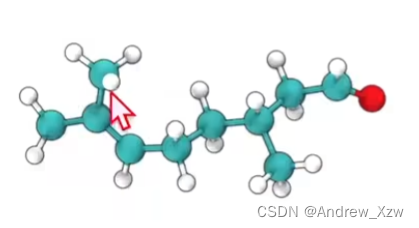
又如这个香料分子图,它的原子通过一些作用力连接在一起,这其中的每一个原子就可以看做成1个”图"顶点。接着连在一起,就形成了边。

空手道俱俱乐部里,这里面的两个老师,每个老师都会跟一些同学做过别赛,全部放在一起,做成一个社交的图。

在我们写科研论文的时候,引用参考文献,这里的关系其实也就是一个有向边了。
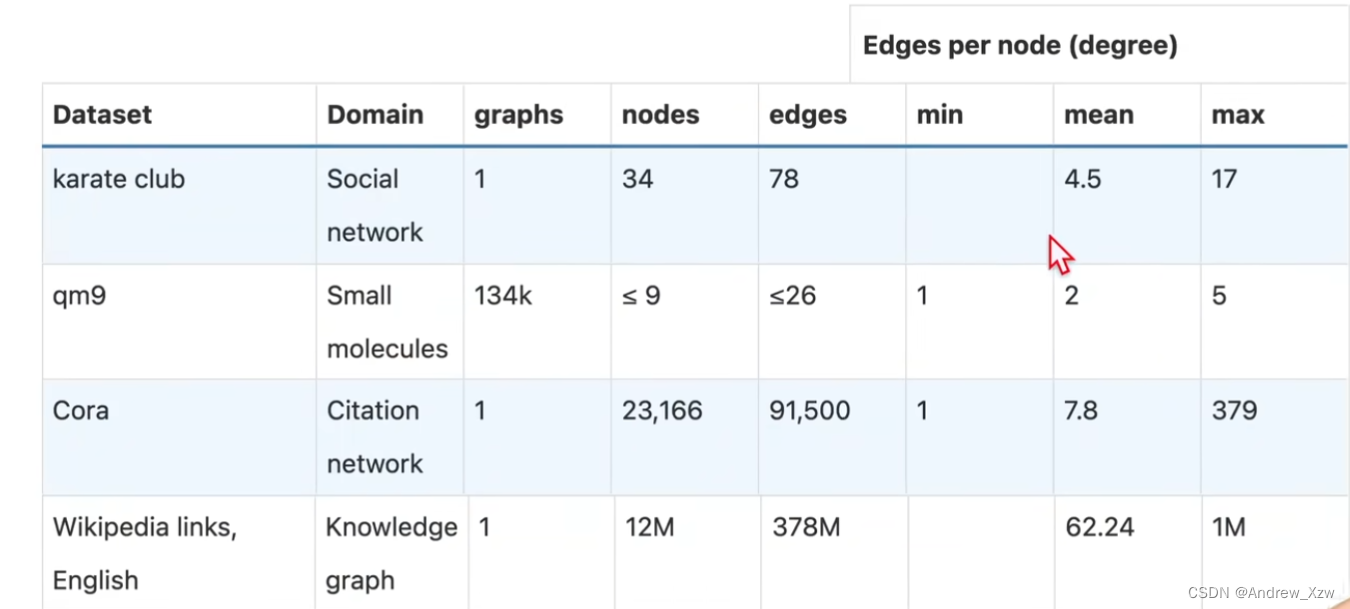
常用的图数据集:
3、常见应用
视觉和NLP领域中,比如图像处理任务,将数据集划分成每一个batch送进网络时,每个图像的尺寸维度是不是都是一样的?不存在就是说第一张图片是200x200,到了第三张就变成了224x224,是不是resize成统一尺寸。相同格式,直接使用“卷积”就可以实现很好的效果。NLP中前一个词,后一个词的输入同样是固定。
但:
像化学领域中,分子结构,万能的“卷积”还能行吗?有的分子中包含个100个氧原子, 有的是300个碳原子组成。
像交通流预测,每个十字路口看作为一个顶点,每个路口的交通流情况都不同,每个城市形成的“图”都不同,这个时候使用“图”就很合适了。
传统的神经网络:CNN等只适用于输入的数据是结构是固定的。而“图”适用于那些比较“随意”的数据。
把数据表示成图之后,可以在图上面定义3种问题:
(1)图层面
给一个图,进行分类,比如识别哪一个是闭环。

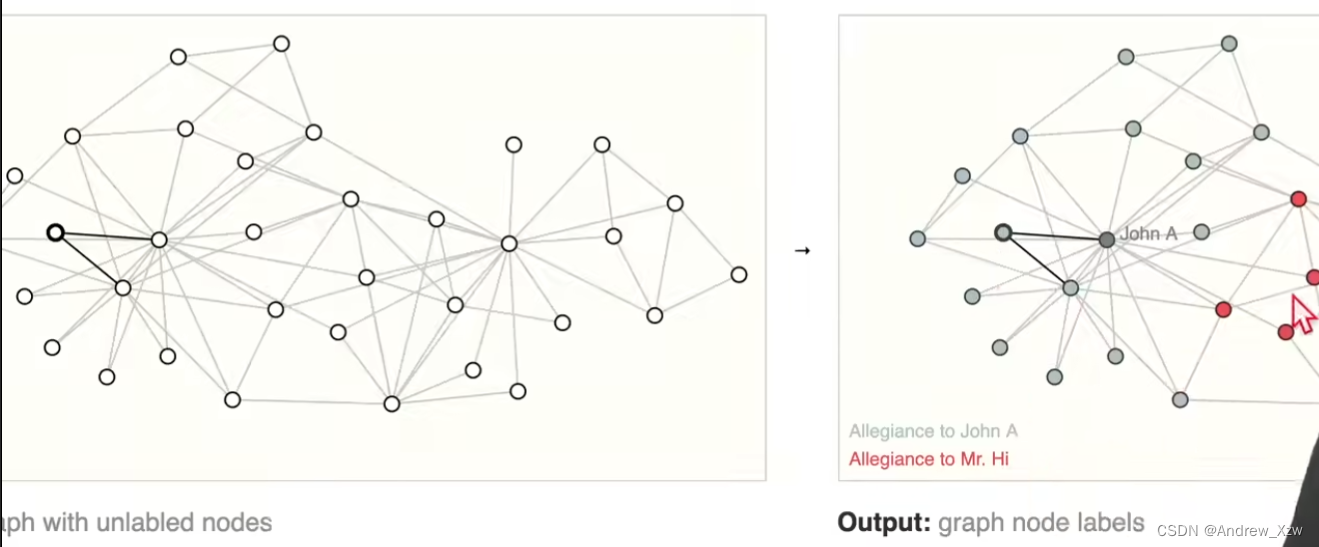
(2)顶点层面
比如空手道社交图,2个老师决裂,判断出每一个学生是属于A老师这个点,还是B老师这个点。
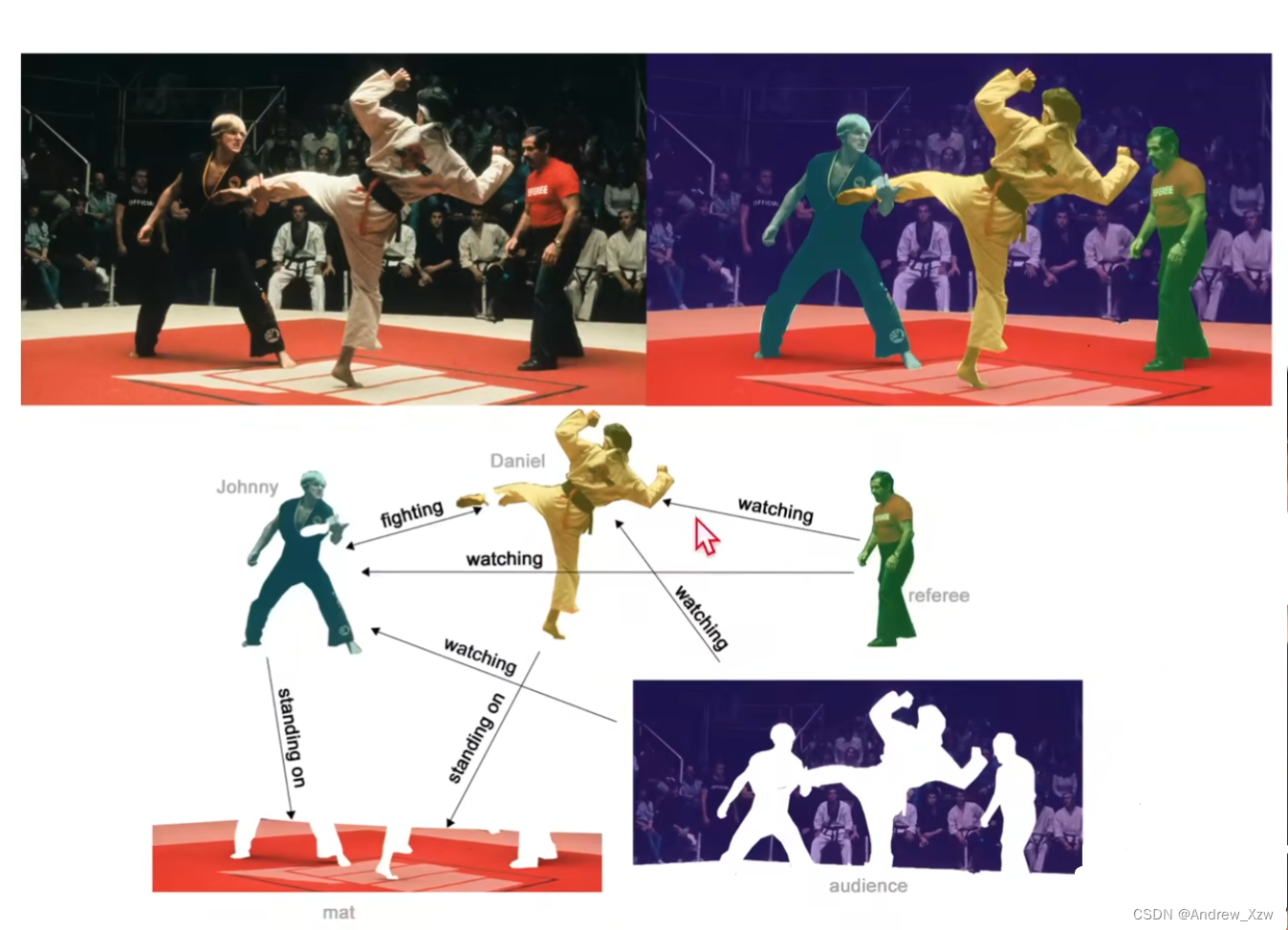
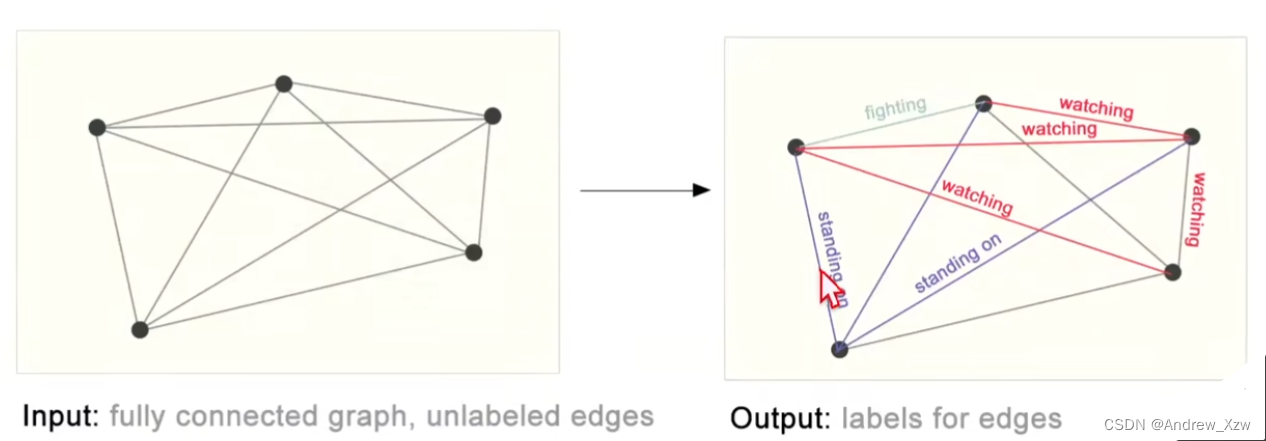
(3)边层面
通过语义分割,获得了每个点,判断每个点之间的属性是什么
4、实际表示方法
在将神经网络用在图上面,最大的问题就是应该怎么样表示图,使得和神经网络之间是兼容的。
图上一般有4种信息:图的属性,边的属性,全局的一些信息,连接性(这条边连接的是哪两个点)。前面3个属性,都可以用”向量“进行表示,每个顶点的属性都可以用向量进行表示。神经网络对向量是很友好的。
关键这个连接性呢?用前面的邻接矩阵(有n个点,就是1个nxn的邻接矩阵)?
实际中,想象如果邻接矩阵是nxn的,这个矩阵但是会很大,,上万个点,要维护这个矩阵,效率肯定特别低,需要很大的计算资源。
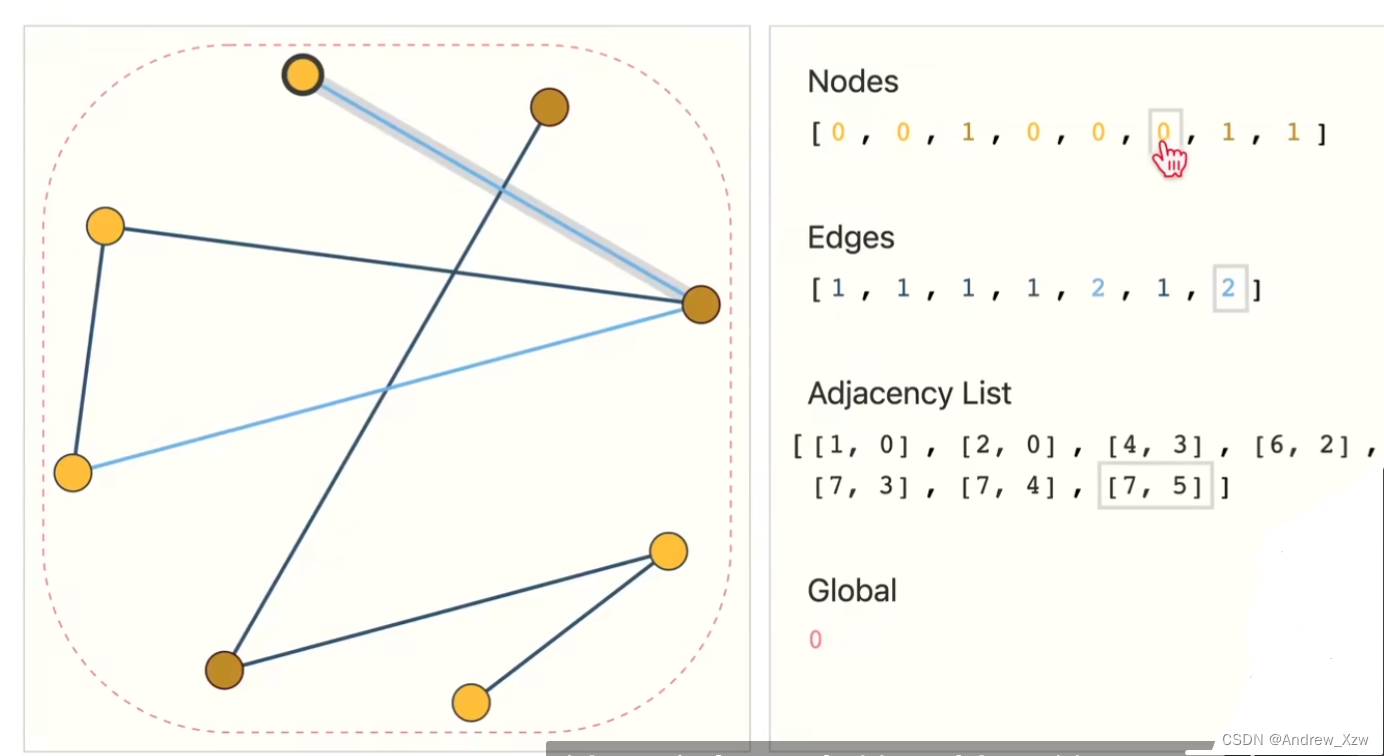
实际,代码实现中,是2xn的矩阵,n表示边的个数,2表示:图中的[1,0]就代表的是[souce,target]的关系,表示由谁到谁,由第1个点到第0个点。
用这种方式进行存储:8个顶点,7条边,每个点的属性用的是1个标量,邻接列表的长度和边数是一样的,第i个项表示的第i条边连接的哪两个节点,在存储上只是把所有的边和所有的属性存储了,计算更高效,并且对顺序没关系的。
5、消息传递
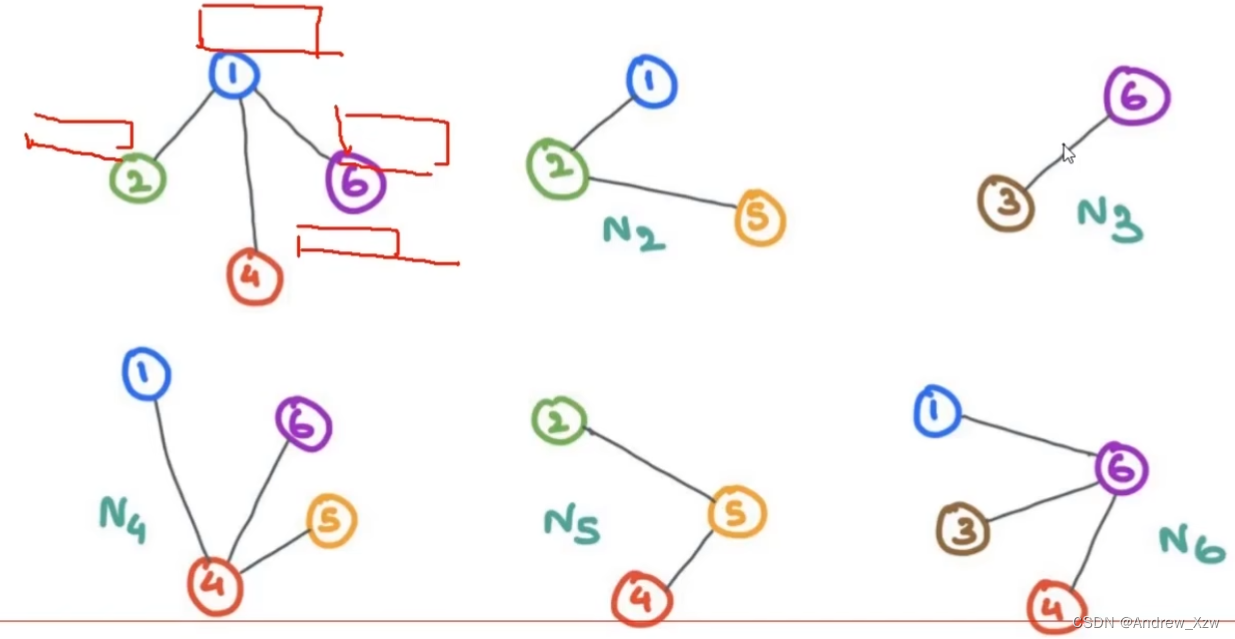
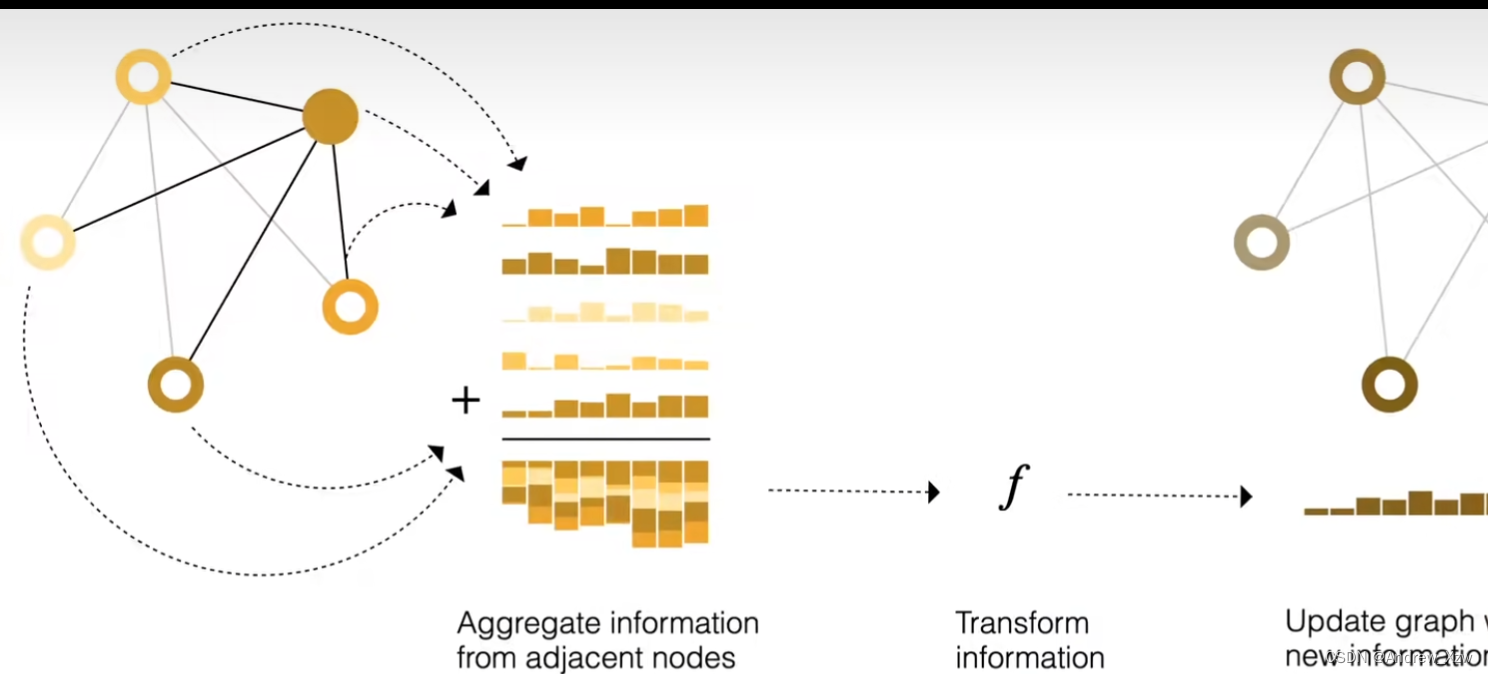
这里每个点连接的点都不是同,该如何重构每个点的特征呢?消息传递,重构特征只要记住,一方面要考虑自身,另一方面考虑邻居的特征就行。
这里的X6,做更新,最终就是这样子的,W就是可学习参数,类似于卷积神经网络的全连接层。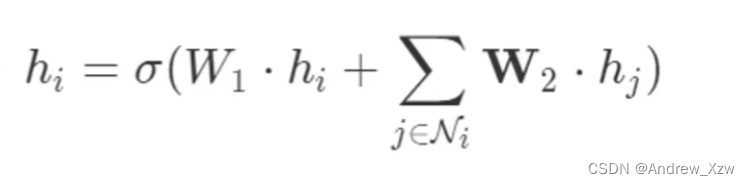
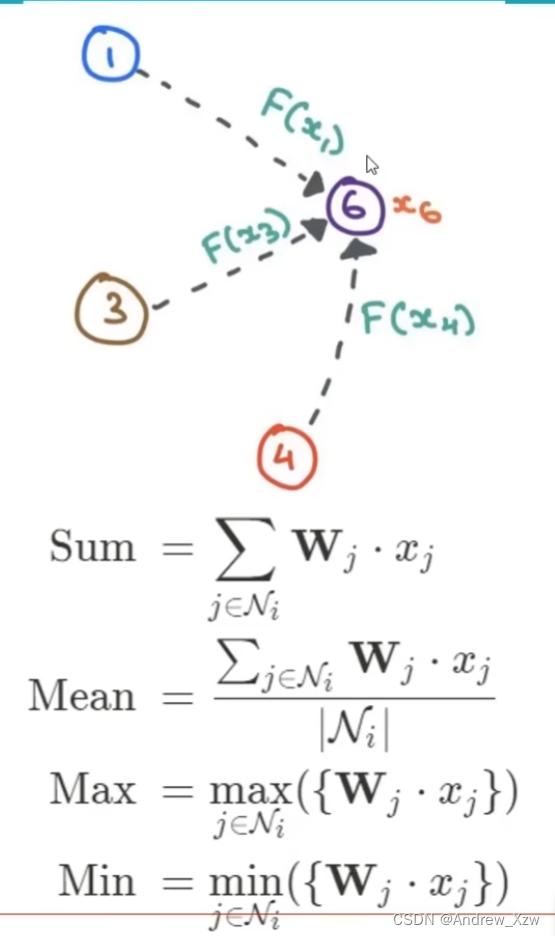
求和,求平均等,哪种方式合适就选择哪种。
6、图神经网络GNN
GNN最重要的就是更新每个点最好的特征,根据每个点最好的特征就可以完成不同的任务了。
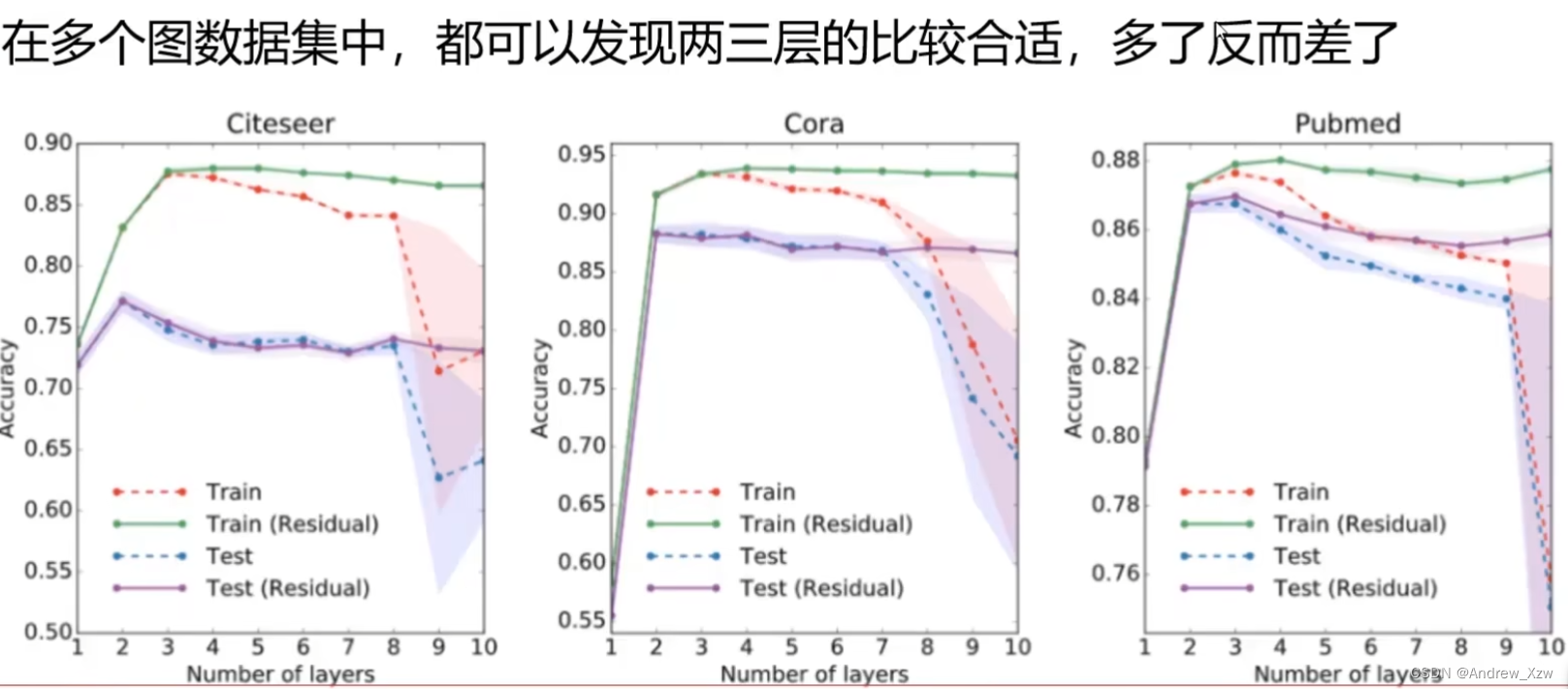
6.1多层GNN
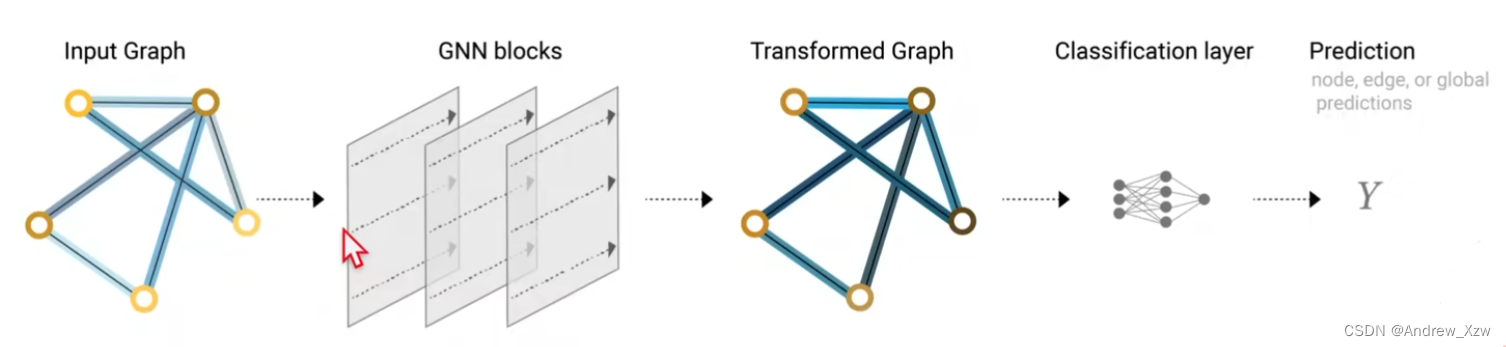
GNN就是对图上所有属性:顶点、边、全局的上下文进行的一个优化变换。这个变换,是能够保持住图的对称信息(将这些顶点进行排序之后,整个结果是不会变的)的。
信息传递神经网络(message passing neural network),GNN的输入是1个图,输出也是1个图,会对那些属性:顶点、边、全局的上下文这些向量进行更新变换,但是不会改变”图的连接性“。邻接矩阵也是不会变的。
层数越多,“感受野”就越大,全局信息更充分。比如一开始的时候,x1只考虑自身和直接相关联的两个邻居,但是经过第一层GNN的时候,由于x2是由自身和x3和x4进行了更新,这个时候x1将x2再拿过来,x1进行自身和直接相关联的两个邻居进行了更新,这时就是经过更新了的x2了。意思就是x1在更新就是也会简间接考虑到x3和x4了。
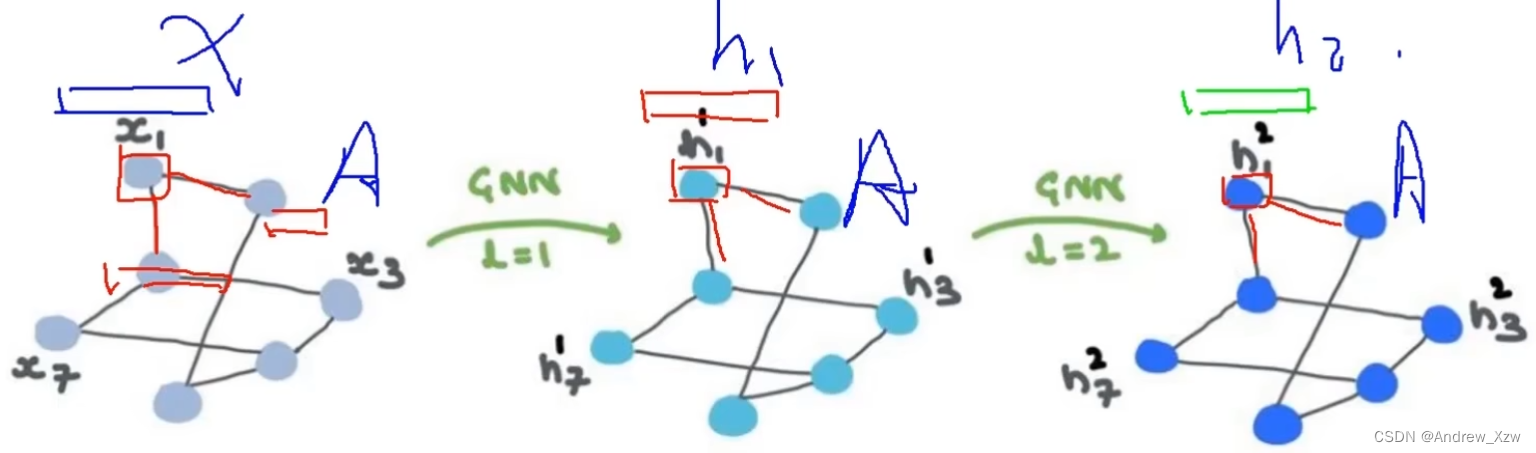
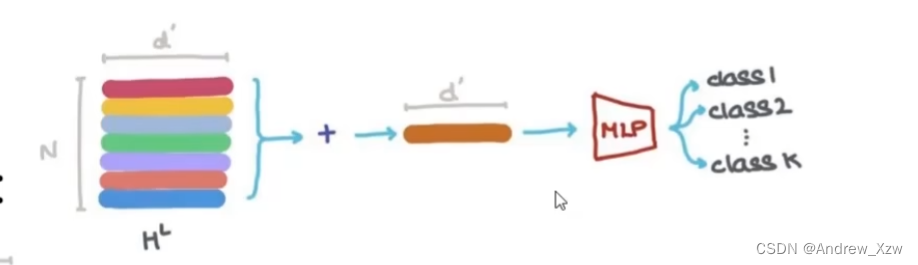
得到每个点的更新的最终特征后,加一个maxpooling,连上一个全连接,是不是就可以做点、边、图的分类和回归?
6.2CNN和GNN?
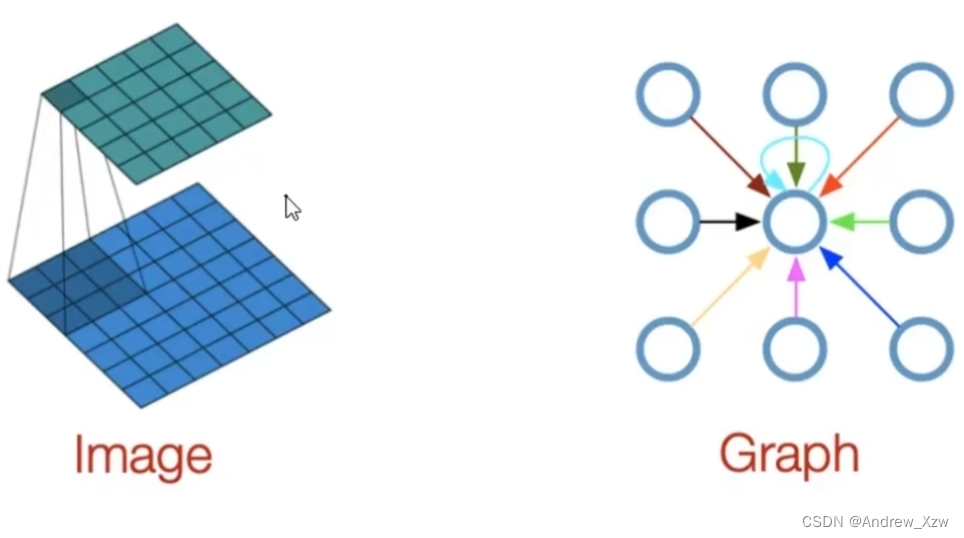
图卷积和卷积神经网络不同,图卷积中根本没有滑动窗口,图卷积都是基于消息传递的,基于每个点的自身和邻居做传递更新。
传统机器学习解决不了输入的数据结构不一致、不规则的问题。
获取每个点的特征,不需要我们自己绞尽脑汁,交给图神经网络就可以了。GCN(各个点的特征,邻接矩阵A)。
6.3半监督学习
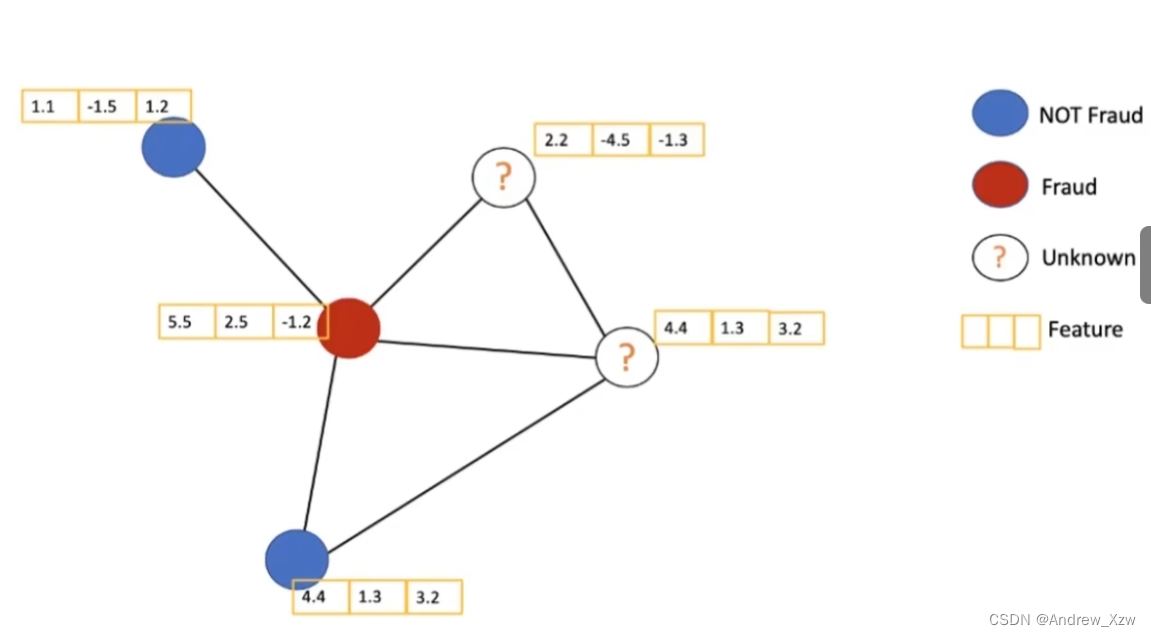
每个图中有很多点,不可能每个点的标签都能够获取到。但是也不需要所有标签也能训练。计算损失时,用带标签的点进行计算。虽然一些点没有标签,但是在图中每个点由自身和周围邻居的点更新,所以没有标签的点也能产生自己的作用。
6.4GCN的基本思想
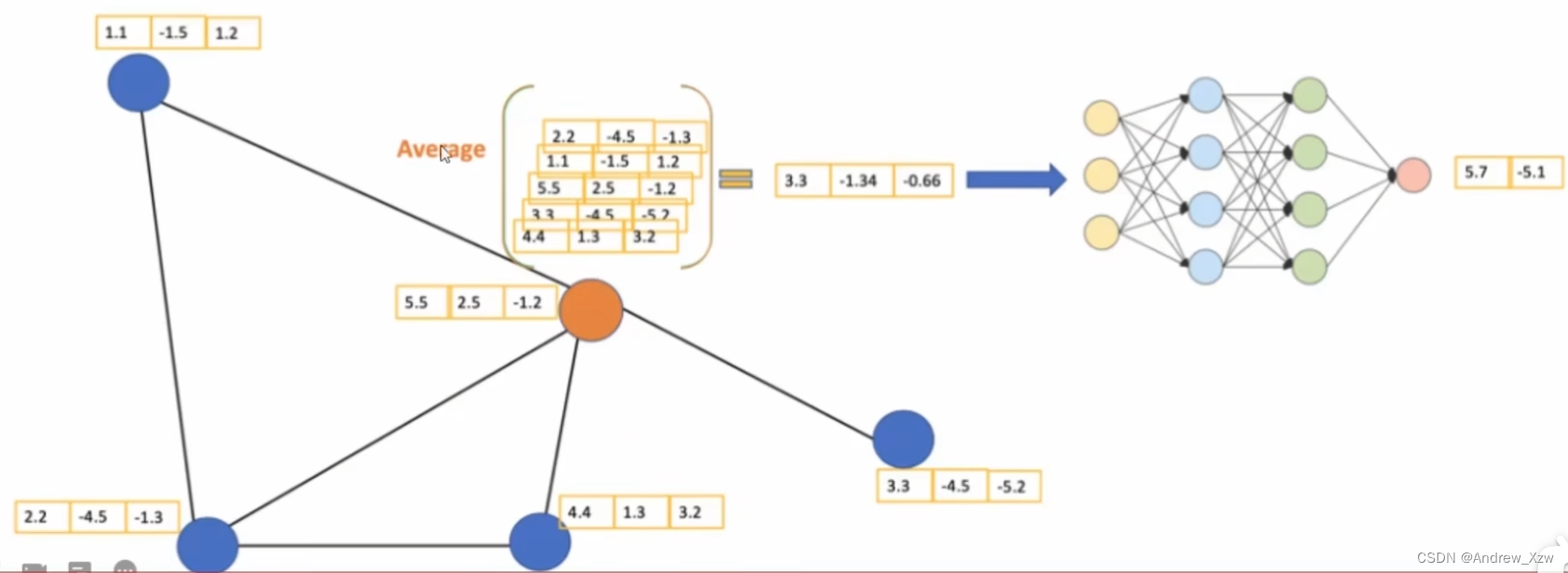
每个点都有自己实际的特征,现在要更新黄色的点得到新的特征。
第一步:消息传递(聚合),自身和周围邻居点的特征求和求平均(一种简单的方法)。接着经过神经网络(走个FC全连接层,就有了可训练参数),最后得到2个特征。(3维特征就–>2维特征)。
和CNN一样,GCN也可以做多层。目前GCN还没有太多层,就和这个图中一样,每个点要想最远的点达成联系,其实只需要2层就达到了。
拿到图之后,经过第一个图卷积层,这当中会对每一个点都做更新。再接激活函数,第二层图卷积层以此类推。最后的输出结果,就是每个点对应的向量。
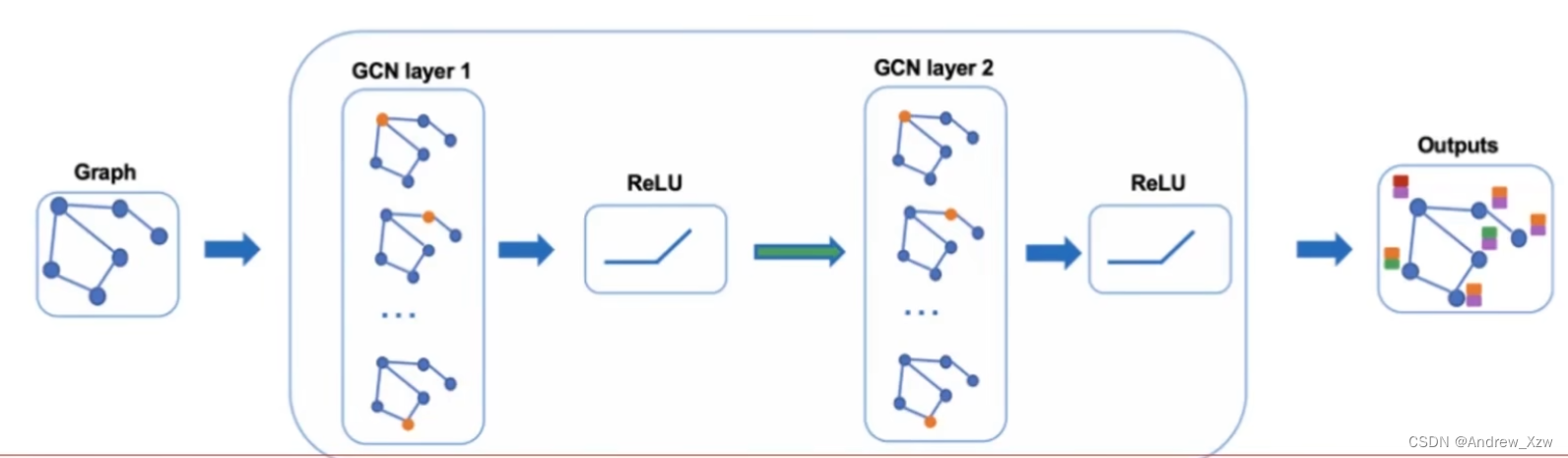
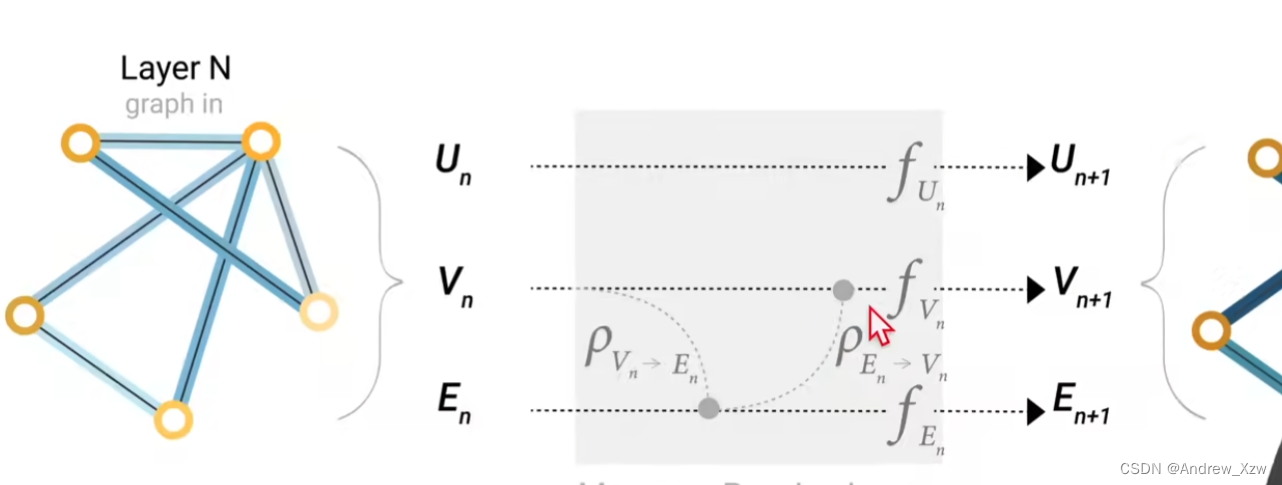
详细的:
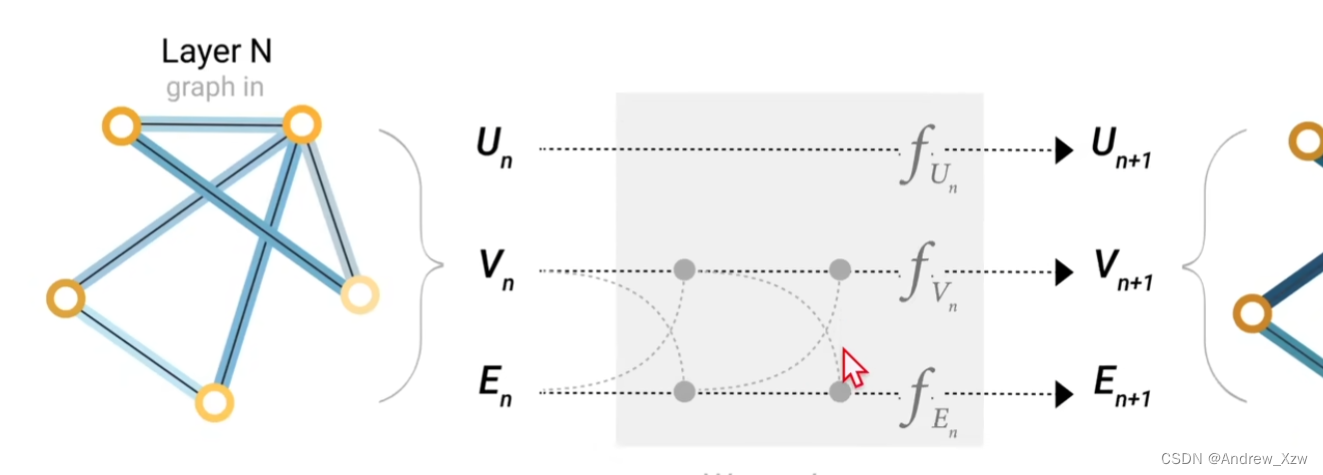
对于顶点向量U,边向量V,和全局向量E,分别构建1个MLP(输入、输出大小是一样的,所有的顶点共享1个MLP,所有的边共享1个MLP。。。。),这3个MLP就组成了一个GNN的层,分别输入进对应的MLP,进行相应的更新。
整个属性都发生了更新,但是整个图的结构没有发生变化。并且每个MLP只会对每个属性进行作用,它不会考虑所有的连接信息。
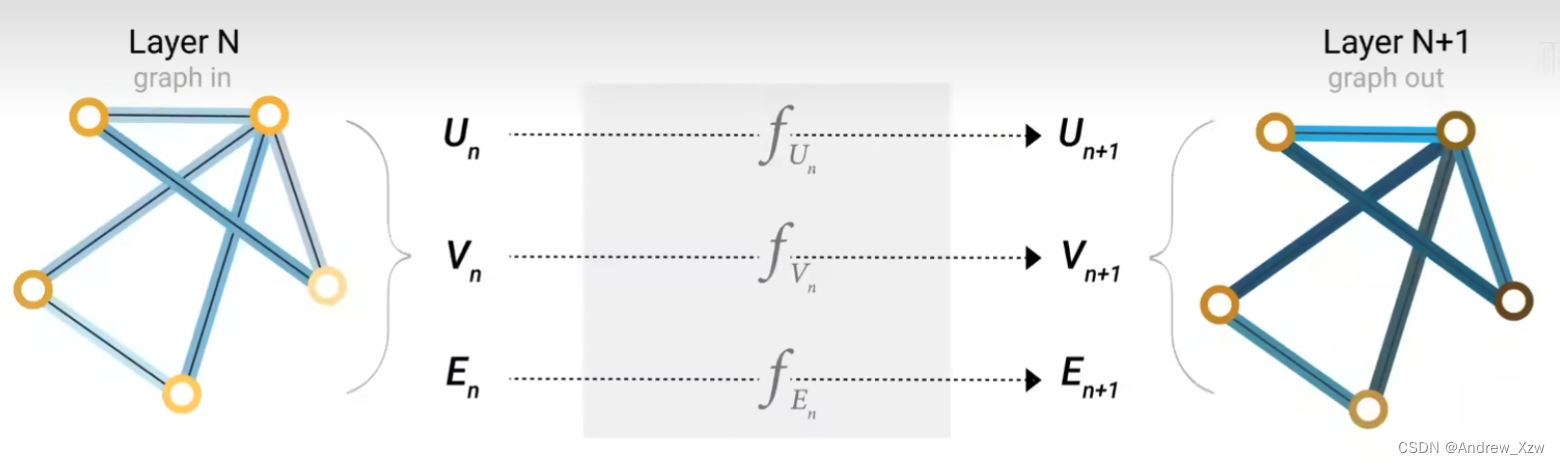
最后一层的输出,得到预测值:
对顶点进行预测,比如那个跆拳道的每一个学生到底跟了哪一个老师,其实就是变成了1个二元分类问题。得到每个顶点的向量后,接一个输出为2的全连接层,再加一个softmax就可以得到最终的输出了。(这里注意所有的顶点共享1个全连接层的参数)
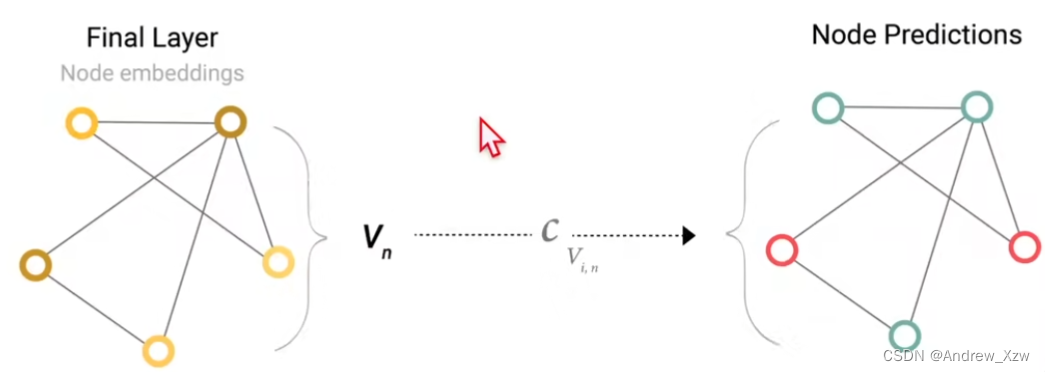
假设我们还是想对顶点做预测,但是没有这个顶点的向量呢?这里用到一个pooling(汇聚,和CNN中没有太大的本质区别)
假设这个点没有自己的向量,还是想得到他的向量做预测,可以把跟这个点连接的那些边的向量拿出来,同意把全局的向量拿出来,就会拿出来5个向量,把5个向量全部加起来,就会得到代表这个点的向量(维度要一致)。
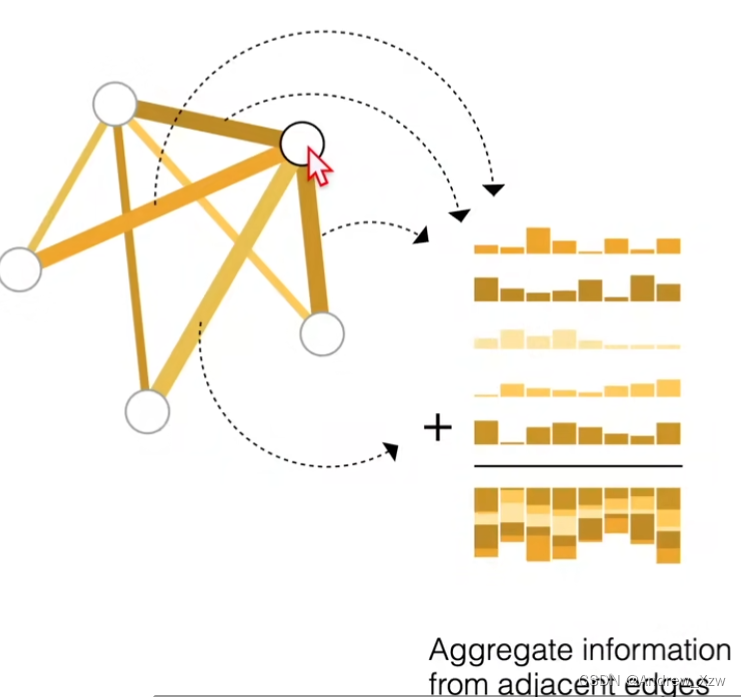

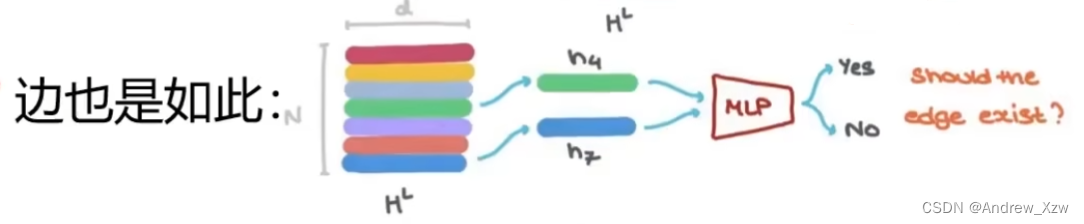
同意的,如果没有边的向量,而一个边是连接的两个点,可以把两个点的向量加起来,也可以再加上全局的那个向量,最后得到这个边的向量。
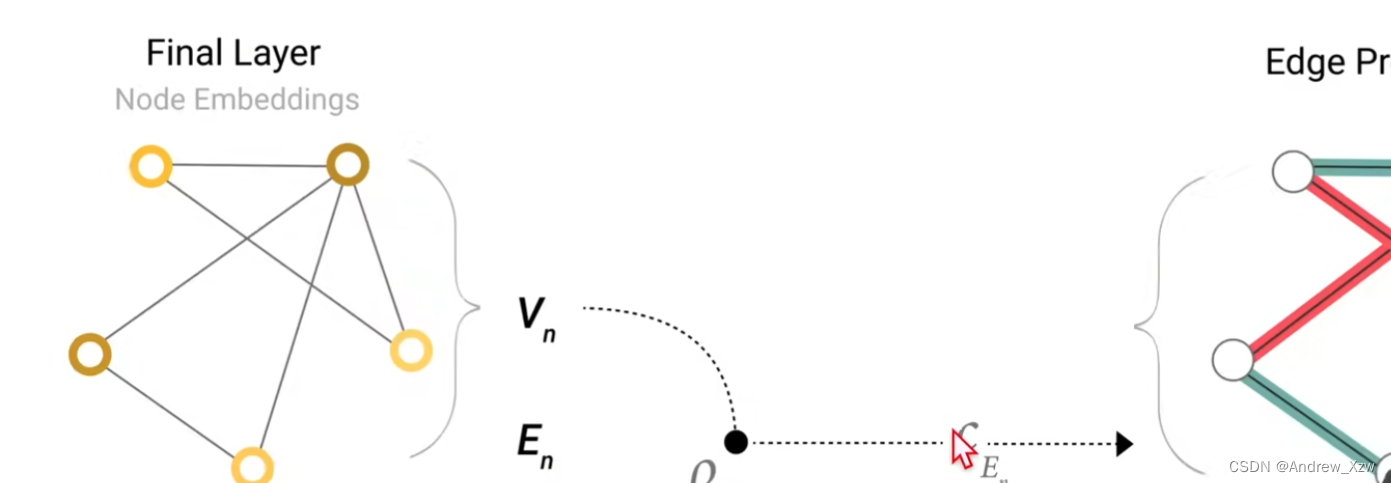
全局的也是如此,把点和边的全部加起来。
最终的GNN:
首先进入一系列GNN层,每一层里面有三个MLP,对应的3种不同的属性,最后的输出会得到一个保持了整个图结构的输出(但是里面的所有属性进行了更新变换)。最后根据要对哪个属性进行预测,添加合适的一些输出层,如果缺失信息,就用上面的polling汇聚。
但其实在GNN这一块,我们并没有对他使用图的信息,对属性进行做变化的时候,只是每个属性自己进去到MLP,并没有看到这个顶点和哪个边相连或者和哪个顶点相连,并没有合理的把整个图的信息更新进属性里。导致最后的结果不太能够完全代表整个图的信息。
可以就是说,在将顶点的向量输入MLP之前,把它和邻居顶点的向量进行相加,得到一个pooling汇聚的向量。就有点类似于图片上的卷积了。
完成顶点到边,边到顶点的传递后,再进行MLP更新。
两种不一样的先后顺序会导致不一样的结果。
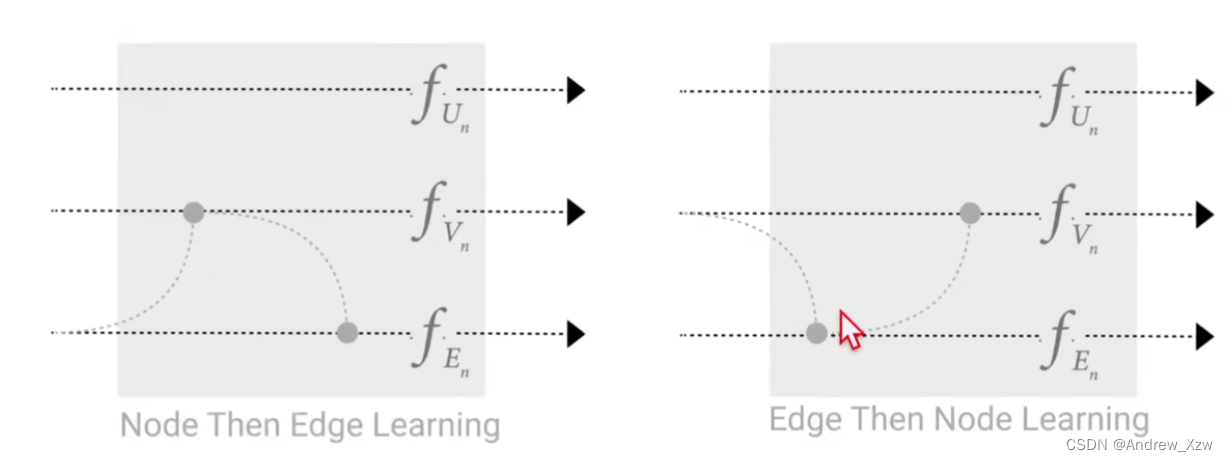
也可以考虑到全局信息的加入:

6.5图中的基本组成
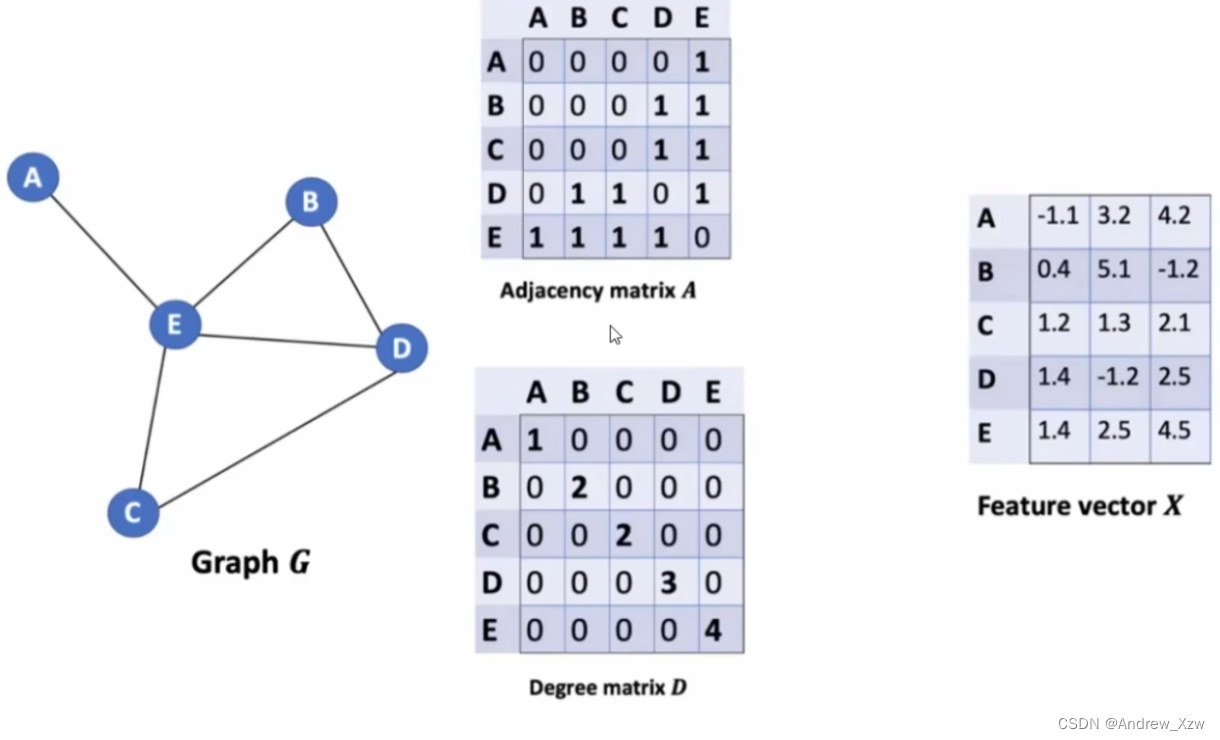
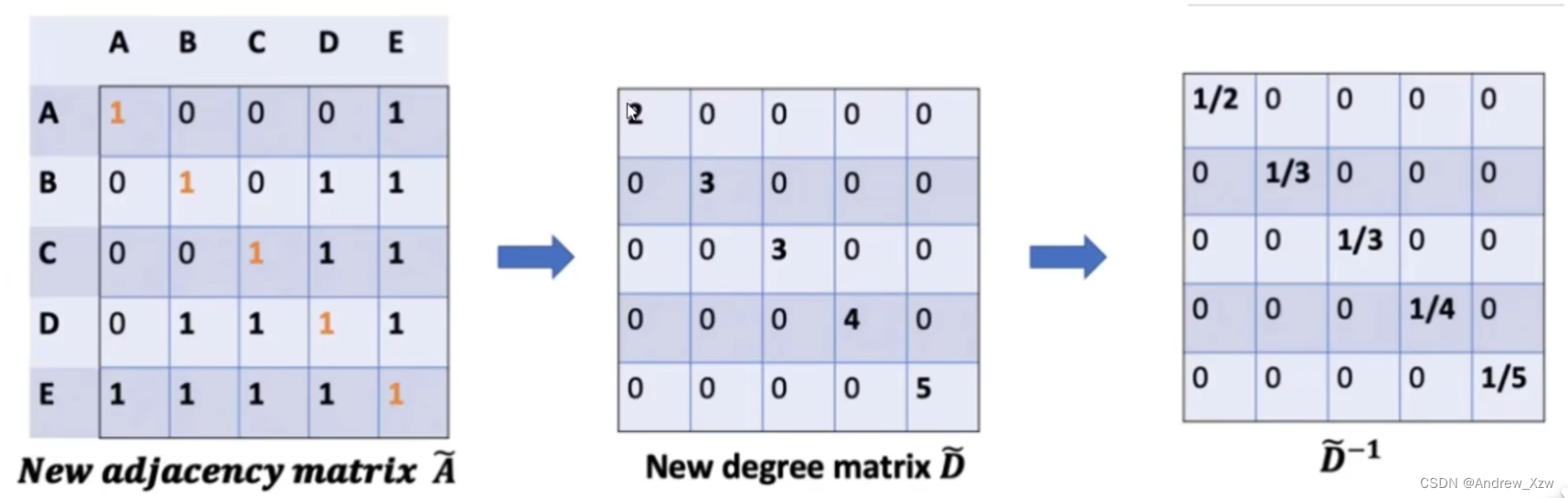
A:邻接矩阵,代表图中每个点是怎么相连的。
D:度矩阵。比如图中的E这个点和周围4个点都有相连,度矩阵对应的就是4。表示每个点和多少个点有关系。
F:每个点的向量。
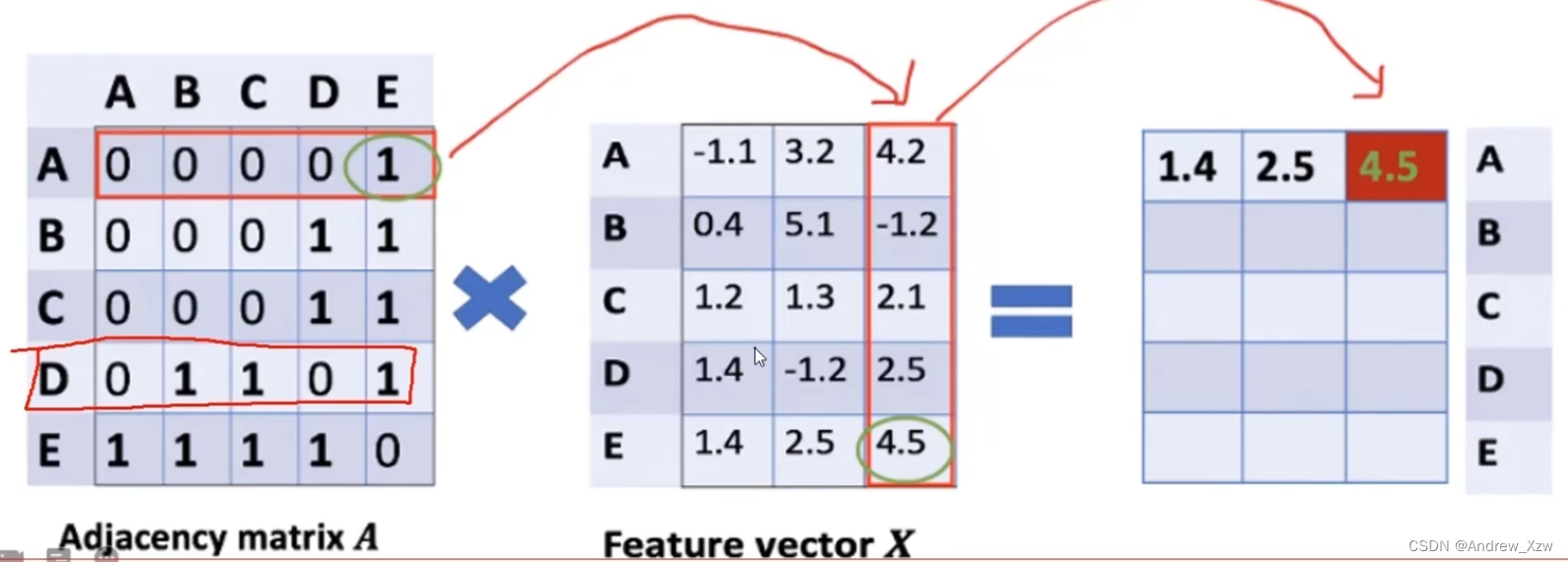
AxX,邻接矩阵x特征向量X,表示聚合邻居的信息。
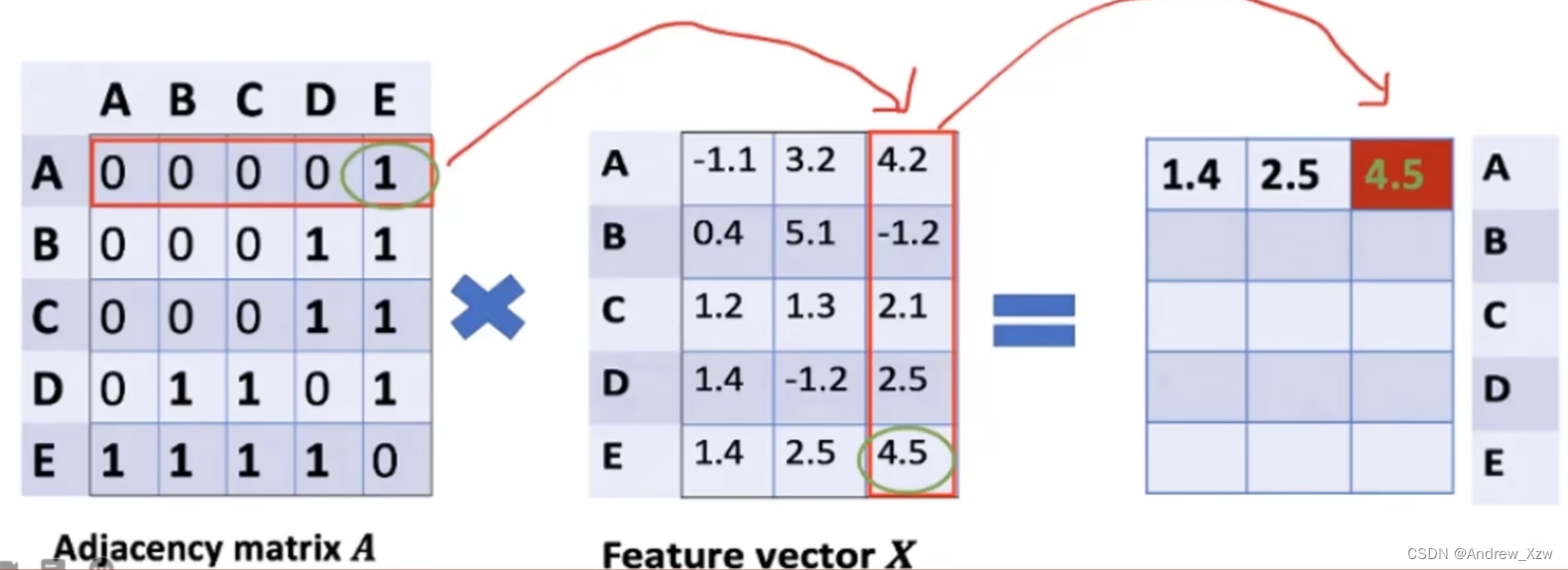
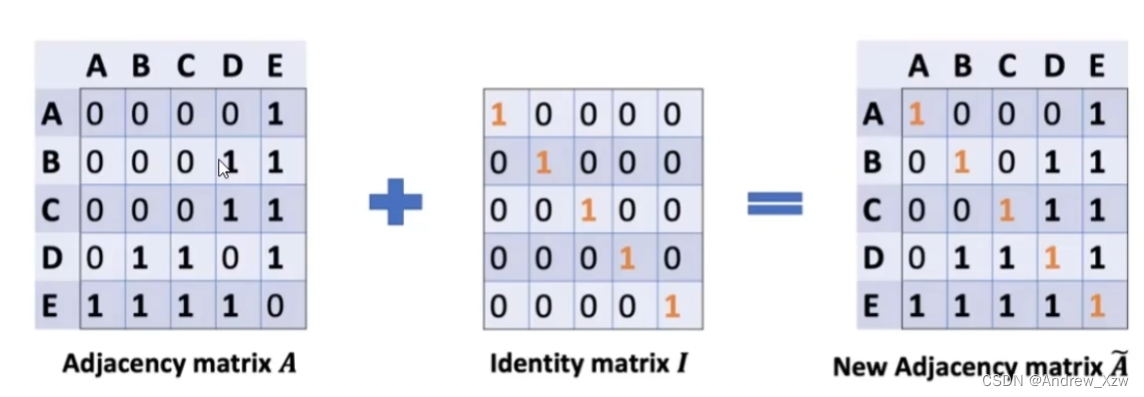
就比如这里重构A向量,会发现A和E这一个点相连,但是AxX进行重构,会发现没有考虑到A自己本身。
所以这里的邻接矩阵,要加上自身I矩阵。(重构特征,不仅要考虑邻居的,要加上自身)。
但是直接使用最新的邻接矩阵Ax特征向量X,会出现问题:比如D这个点和好几个点相连,相乘后的结果会相对于其他的更大,但是理论上不是你连接的点越多,你就越大,应该要进行一个平均才合理。
所以,这里我们把度矩阵D考虑进来(和邻接矩阵A一样,要把自身考虑快进来,对角线+1)。求D矩阵的逆矩阵,就相当求平均的感觉了(因为度矩阵D的对角线是相当于每个点周围相邻的点的数量,有点类似于权重大小,倒数就有点求平均的感觉了)。
D矩阵的逆矩阵x邻接矩阵,就得到了求平均的新的邻接矩阵了。

这里出现了个问题,左乘度矩阵D的逆矩阵,只是相当于对邻接矩阵A做了一个行维度的归一化,那列肯定也要管一管啊,对不对?
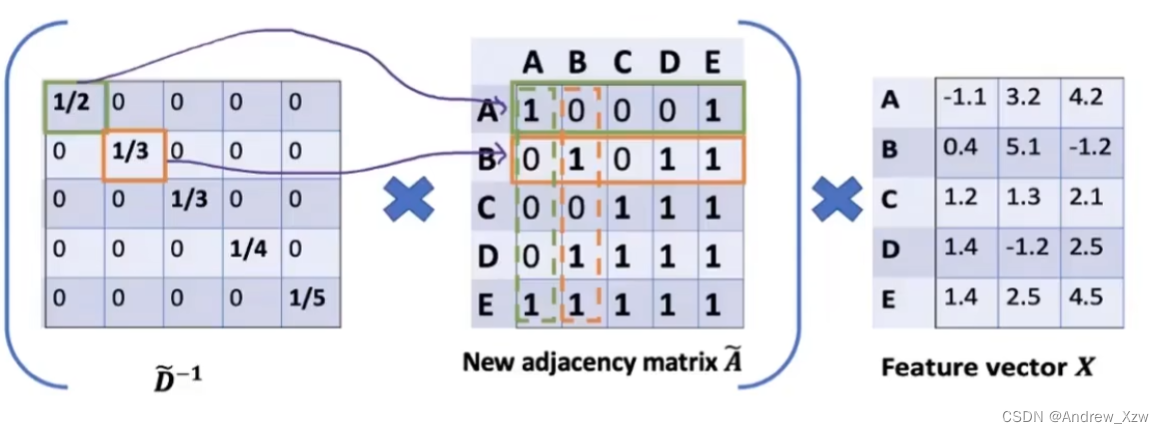
我们这里,右乘一个度矩阵D的逆矩阵,就相当于又对列维度做了一个归一化了。
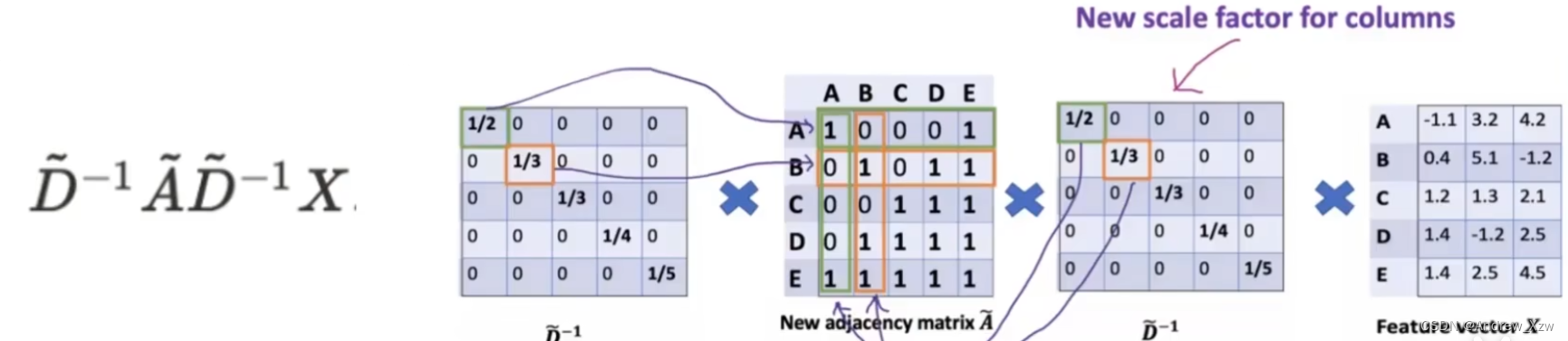
但是,虽然在行和列两个维度上都做看归一化了。但其实每一个值是重复做了两遍归一化。会使得值变得很小。所以解决方法:同时开个根号。
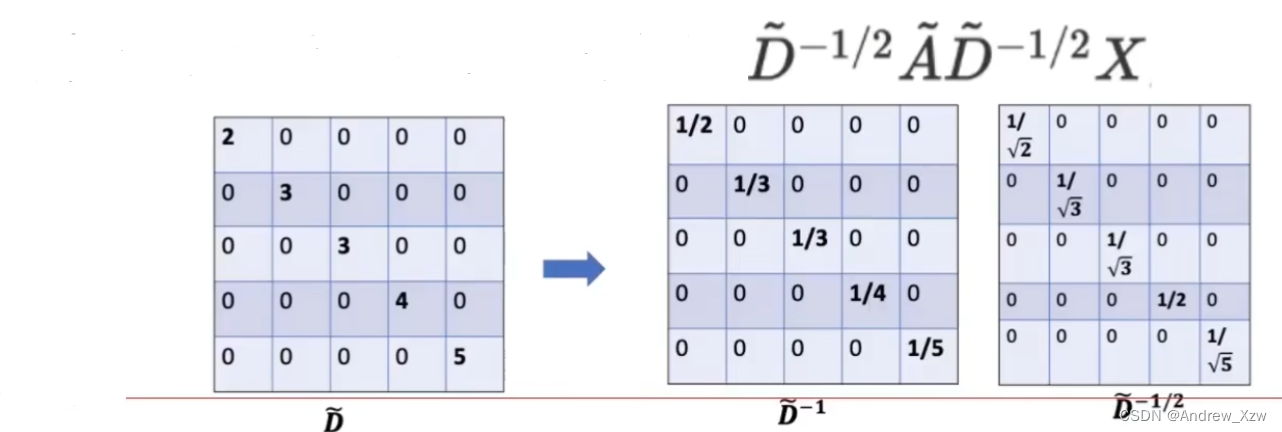
整体的2层的GCN的公式为,其中式中的邻接矩阵为已经左乘右成进行了行和列的归一化的邻接矩阵。