1.概述
上文分析了elasticsearch的基础概念和基本操作,让大家熟悉了es的基础使用。本文将基于上文更深入分析elasticsearch的一些高级操作,来帮助更加深入了解和使用elasticsearch。
2.elasticsearch实战
本文将以最常见的酒店住宿场景作为演示,很多电商平台都会有住宿酒店预订的场景,用户可以根据位置、价格、评分等条件来搜索符合要求的酒店信息,搜索符合条件的酒店,然后进行下单、付款等一系列操作。首先需要了解elasticsearch中一个概念:聚合(aggregations)。
聚合可以实现对文档数据的统计、分析、运算。聚合常见的有三类:
(1)桶(Bucket)聚合:用来对文档做分组,按照文档字段值分组(TermAggregation)、按照日期阶梯进行分组(Date Histogram);
(2)度量(Metric)聚合:用以计算一些值,比如:最大值、最小值、平均值等;Avg(求平均值)、Max(求最大值)、Min(求最小值)、Stats(同时求max、min、avg、sum等);
(3)管道(pipline)聚合:其它聚合的结果为基础做聚合。
关于聚合的所有功能,都可以在官方文档进行查看,使用时可以进行查阅。
2.1 DSL实现聚合
2.1.1 DSL实现Bucket聚合
例:统计数据中的酒店属于哪几个城市,此时可以根据酒店所在城市city做聚合,如下所示:
#聚合
GET /hotel/_search
{
"size": 0, //设置size为0,结果中不包含文档,只包含聚合结果
"aggs": {
//定义聚合
"cityAgg": {
//定义聚合名称
"terms": {
//聚合的类型,按照分布城市进行聚合,所以选择term
"field": "city", //参与聚合的字段
"size": 10, //希望获取的聚合结果数量
"order": {
"_count": "asc" //排序方式,默认倒序
}
}
}
}
}
默认情况下,Bucket聚合是对索引库的所有文档做聚合,我们可以限定要聚合的文档范围,只要添加query条件即可,如下所示:
#聚合
GET /hotel/_search
{
"query": {
"range": {
"price": {
"gte": 1000 //酒店价格大于1000
}
}
},
"size": 0,
"aggs": {
"cityAgg": {
"terms": {
"field": "city",
"size": 10
}
}
}
}
2.1.2 DSL实现Metrics聚合
例:获取每个品牌的用户评分最大值(max)、最小值(min)、平均值(avg)等。
#聚合
GET /hotel/_search
{
"size": 0,
"aggs": {
"cityAgg": {
"terms": {
"field": "city",
"size": 10,
"order": {
"scoreAgg.avg": "desc" //根据评分score的平均值进行降序排序
}
},
"aggs": {
"scoreAgg": {
//对按city聚合后的子聚合,也就是分组后对每组分别计算
"stats": {
//聚合类型,这里stats可以计算min、max、avg等
"field": "score" //聚合字段,这里是score
}
}
}
}
}
}
2.2 利用RestHighLevelClient请求
2.2.1 RestHighLevelClient实现聚合
针对2.1.1中的案例,利用JAVA进行实现:
public List<HotelBo> countListByCity() {
SearchRequest request = new SearchRequest(Constants.HOTEL_INDEX);
request.source().size(0);
//组装DSL聚合语句,按照city进行聚合查询
request.source().aggregation(AggregationBuilders.terms("cityAgg").field("city").size(20));
List<HotelBo> hotelBos = new ArrayList<HotelBo>();
try {
SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
log.info("请求返回结果:{}", response);
Aggregations aggregations = response.getAggregations();
//解析结果,获取Bucket中的数据
Terms terms = aggregations.get("cityAgg");
List<? extends Terms.Bucket> buckets = terms.getBuckets();
for (Terms.Bucket bucket : buckets) {
HotelBo hotelBo = new HotelBo();
hotelBo.setCity(bucket.getKey().toString());
hotelBo.setTotal((int) bucket.getDocCount());
hotelBos.add(hotelBo);
}
log.info("hotelbos:{}", hotelBos);
} catch (IOException e) {
e.printStackTrace();
}
return hotelBos;
}
运行结果如下图所示:

2.2.2 RestHighLevelClient实现多条件查询
//根据条件查询list
public Page queryListByParams(QueryParams queryParams) {
SearchRequest searchRequest = new SearchRequest(Constants.HOTEL_INDEX);
Page page = new Page();
page.setPageNo(queryParams.getPageNo());
page.setPageSize(queryParams.getPageSize());
//
buildParams(queryParams, searchRequest);
Integer start = 0;
if (queryParams.getPageNo() != null && queryParams.getPageSize() != null) {
start = (queryParams.getPageNo() - 1) * queryParams.getPageSize();
}
page.setStart(start);
searchRequest.source().from(start);
if (queryParams.getPageSize() != null) {
searchRequest.source().size(queryParams.getPageSize());
} else {
searchRequest.source().size(10);
}
SearchHits hits = null;
TotalHits totalHits = null;
try {
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
log.info("result:{}", response);
hits = response.getHits();
totalHits = hits.getTotalHits();
} catch (IOException e) {
e.printStackTrace();
}
page.setTotal(totalHits.value);
log.info("总数为total:{}", totalHits);
List<Hotel> lists = new ArrayList<Hotel>();
SearchHit[] hitsList = hits.getHits();
for (SearchHit documentFields : hitsList) {
String sourceAsString = documentFields.getSourceAsString();
log.info("查询结果:{}", sourceAsString);
if (StringUtils.isNotBlank(sourceAsString)) {
Hotel hotel = JSON.parseObject(sourceAsString, Hotel.class);
Object[] sortValues = documentFields.getSortValues();
if (sortValues.length != 0) {
hotel.setDistance(sortValues[0].toString());
}
lists.add(hotel);
}
}
page.setData(lists);
return page;
}
查询的参数如下:
@Data
public class QueryParams {
private Integer pageSize;
private Integer pageNo;
//关键字
private String keyWord;
//所在城市
private String city;
//酒店名称
private String hotelName;
//酒店最低价
private Double minPrice;
//酒店最高价
private Double maxPrice;
//排序方式,asc:升序,desc:降序
private String sortBy;
//星级
private String starName;
//位置,附近的人
private String location;
}
测试根据名称和星级查询结果如下:
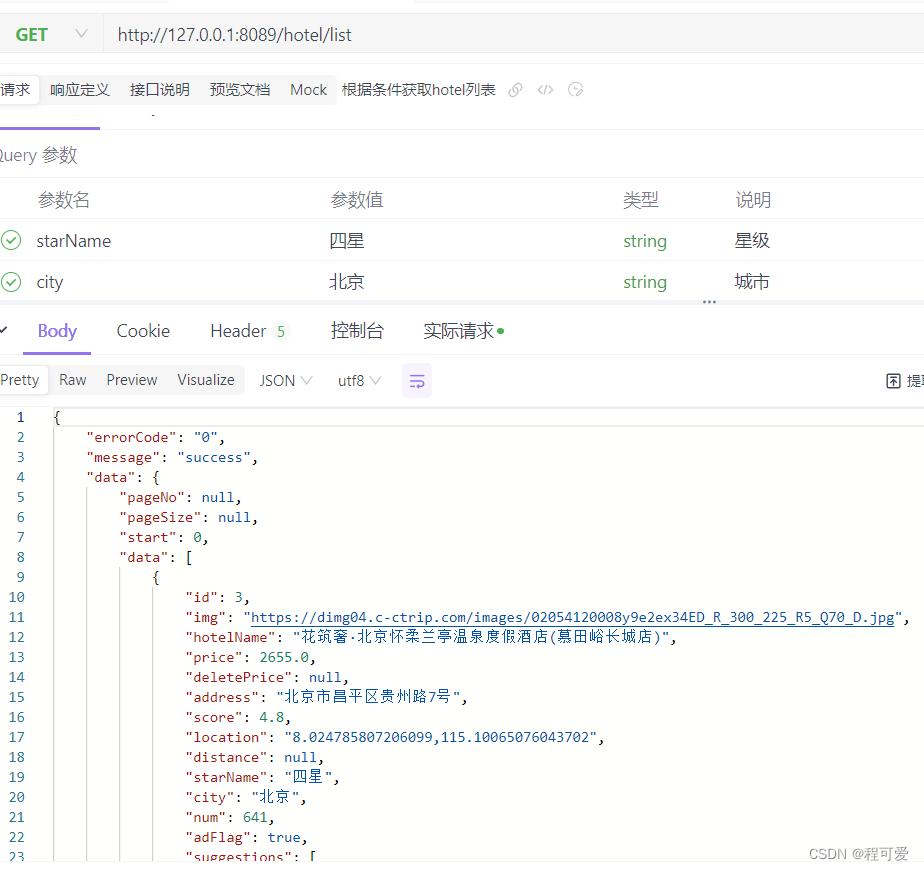
具体代码及测试数据参考附录部分。

2.2.3 elasticsearch分词器
elasticsearch中分词器包含三个部分:character filters、tokenizer、tokenizer filter,每部分的主要功能如下:
- character filters:对文本进行预处理(删除字符、替换字符登);
- tokenizer:将文本按照一定的规则切割成词条(term),keyword不分词;
- tokenizer filter:将tokenizer输出的词条做进一步处理,例如大小写转换、同义词处理、拼音处理登。
2.2.3 es实现拼音自动补全搜索
要实现根据字母做补全,就必须对文档按照拼音分词。拼音分词插件可以从github上获取,安装方式与IK分词器一样,共分为三步:
(1)下载对应版本的拼音分词包,上传到elasticsearch的plugin目录;
(2)进行安装包解压;
(3)重启elasticsearch。
安装成功之后,通过Restful API进行测试,请求方式如下:
POST /_analyze
{
"text": ["中国万岁"],
"analyzer": "pinyin"
}
若出现以下结果,表明拼音分词器安装成功:
{
"tokens" : [
{
"token" : "zhong",
"start_offset" : 0,
"end_offset" : 0,
"type" : "word",
"position" : 0
},
{
"token" : "zhgws",
"start_offset" : 0,
"end_offset" : 0,
"type" : "word",
"position" : 0
},
{
"token" : "hua",
"start_offset" : 0,
"end_offset" : 0,
"type" : "word",
"position" : 1
},
{
"token" : "guo",
"start_offset" : 0,
"end_offset" : 0,
"type" : "word",
"position" : 2
},
{
"token" : "wan",
"start_offset" : 0,
"end_offset" : 0,
"type" : "word",
"position" : 3
},
{
"token" : "sui",
"start_offset" : 0,
"end_offset" : 0,
"type" : "word",
"position" : 4
}
]
}
通过Restful API自定义拼音分词器的请求如下:
#自定义分词器
PUT /pinyin_test
{
"settings": {
"analysis": {
"analyzer": {
//拼音分词器名称
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
}
},
//拼音分词器的一些配置
"filter": {
"py": {
"type": "pinyin",
"keep_full_pin": false,
"keep_joined_full_pinyin": false,
"keep_original": true,
"limit_first_letter": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
//mapping指定哪个字段需要使用拼音分词器
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer",
//搜索时采用ik_smart分词器
"search_analyzer": "ik_smart"
}
}
}
}
创建成功之后,利用下面Restful API请求进行测试:
POST /pinyin_test/_analyze
{
"text": ["中国万岁"],
"analyzer": "my_analyzer"
}
如出现如下结果,则表明分词器创建成功:
{
"tokens" : [
{
"token" : "zhong",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "guo",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "中国",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "zg",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "wan",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "sui",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "万岁",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "ws",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "wan",
"start_offset" : 2,
"end_offset" : 3,
"type" : "TYPE_CNUM",
"position" : 4
},
{
"token" : "万",
"start_offset" : 2,
"end_offset" : 3,
"type" : "TYPE_CNUM",
"position" : 4
},
{
"token" : "w",
"start_offset" : 2,
"end_offset" : 3,
"type" : "TYPE_CNUM",
"position" : 4
},
{
"token" : "sui",
"start_offset" : 3,
"end_offset" : 4,
"type" : "COUNT",
"position" : 5
},
{
"token" : "岁",
"start_offset" : 3,
"end_offset" : 4,
"type" : "COUNT",
"position" : 5
},
{
"token" : "s",
"start_offset" : 3,
"end_offset" : 4,
"type" : "COUNT",
"position" : 5
}
]
}
elasticsearch提供了Completion Suggester查询来实现补全功能,这个查询会匹配以用户输入内容开头的词条并返回。为了提高补全查询的效率,对应文档中字段的类型有一些约束:参与补全查询的字段必须是completion类型。
PUT /pinyin_test
{
"mappings": {
"properties": {
"name":{
"type": "completion"
}
}
}
}
例如根据关键字进行搜索:
GET /hotel/_search
{
"suggest": {
"titleSuggest": {
"text": "h",
"completion": {
"field": "suggestions", //suggestions是根据city与hotelName组合的快速搜索数组
"skip_duplicates":true,
"size":10
}
}
}
}
利用RestHighLevelClient进行数据查询代码如下:
public List<String> searchByPinyin(String string) {
SearchRequest searchRequest = new SearchRequest(Constants.HOTEL_INDEX);
//进行根据输入拼音进行关键字匹配
searchRequest.source().suggest(new SuggestBuilder().addSuggestion("suggestions", SuggestBuilders.completionSuggestion("suggestions").prefix(string).skipDuplicates(true).size(10)));
List<String> lists = new ArrayList<String>();
try {
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
Suggest suggest = response.getSuggest();
Suggest.Suggestion<? extends Suggest.Suggestion.Entry<? extends Suggest.Suggestion.Entry.Option>> titleSuggest = suggest.getSuggestion("suggestions");
String name = titleSuggest.getName();
log.info("name:{}",name);
for (Suggest.Suggestion.Entry<? extends Suggest.Suggestion.Entry.Option> options : titleSuggest.getEntries()) {
log.info("options:{}",options);
List<? extends Suggest.Suggestion.Entry.Option> options1 = options.getOptions();
for (Suggest.Suggestion.Entry.Option option : options1) {
log.info("option1:{}",option);
lists.add(option.getText().toString());
}
}
} catch (IOException e) {
e.printStackTrace();
}
return lists;
}
2.3 ElasticSearch数据同步
在生产环境中,elasticSearch主要用来提供数据查询功能,数据存储工作主要由关系型数据库保存,因此如何保持关系型数据库与elasticsearch数据一致就成为关键。本文以mysql为例,分析mysql与elasticsearch进行数据同步的三种方式:
2.3.1 同步调用

由上图所示,同步调用在于当新增或修改数据时,数据会经由管理服务进行入库mysql,入库成功后调用搜索服务(操作es)更新数据到elasticsearch,整个过程同步调用。这种方式的优势在于数据更新实时,能够快速同步。缺点在于数据更新频繁时,数据入库时间会受elasticsearch性能影响,一旦elasticsearch出现问题,可能导致后续数据都无法入库。
2.3.2 利用消息中间进行同步
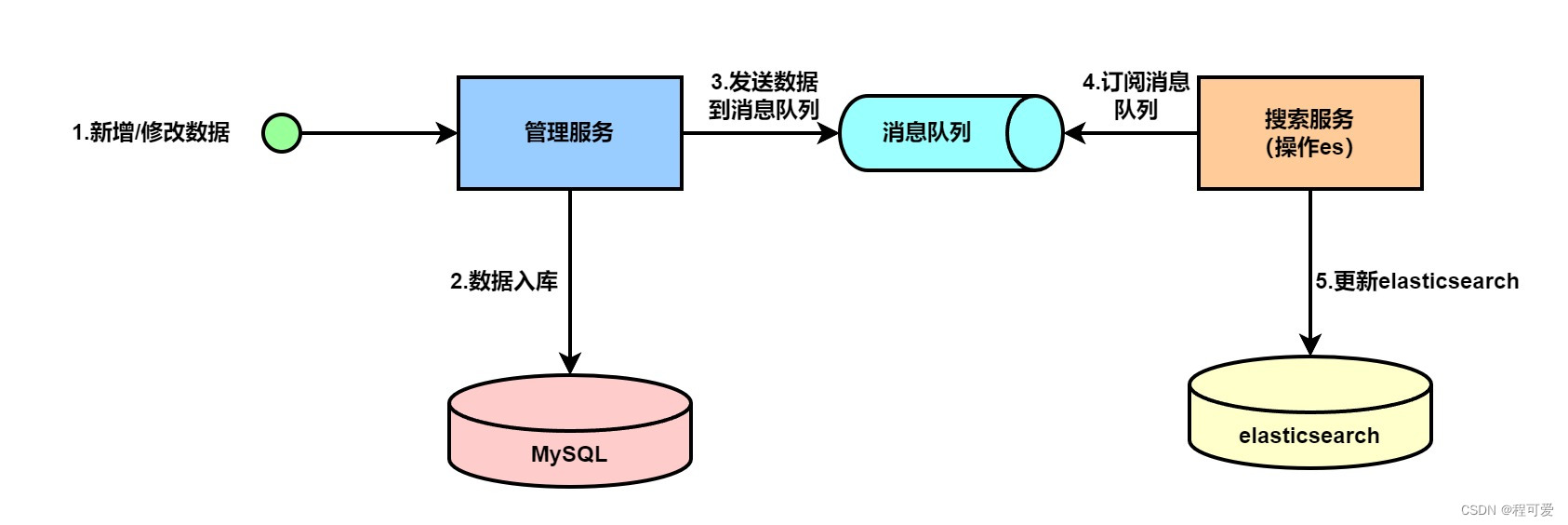
利用消息中间件进行同步与方案一的区别在于:在管理服务和搜索服务之间新增了一个消息队列,管理服务将数据存入到mysql之后,再将数据发送到消息队列,搜索服务通过订阅消息队列,获取变更数据,然后更新到elasticsearch。这种方式的优势在于将数据更新到mysql和elasticsearch进行解耦,使两者互不影响。缺点在于数据同步实时性相对于方案一较低。
2.3.3 利用canal进行数据同步

利用canal来进行数据同步,mysql需要开启binlog日志,当有数据发生增删改时,canal会根据binlog日志获取数据变更信息,推送变更信息至搜索服务,搜索服务判断数据操作类型并同步至elasticsearch。这种方式的优势在于数据同步效率会比使用中间件高,缺点是会消耗mysql性能。
2.4 ElasticSearch集群
单机ElasticSearch会面临两个问题:
(1)海量数据存储问题:要解决这个问题,可以将索引库从逻辑上分为N个分片(shard),存储到多个节点;
(2)单点故障问题:将分片数据在不同节点备份(replica);
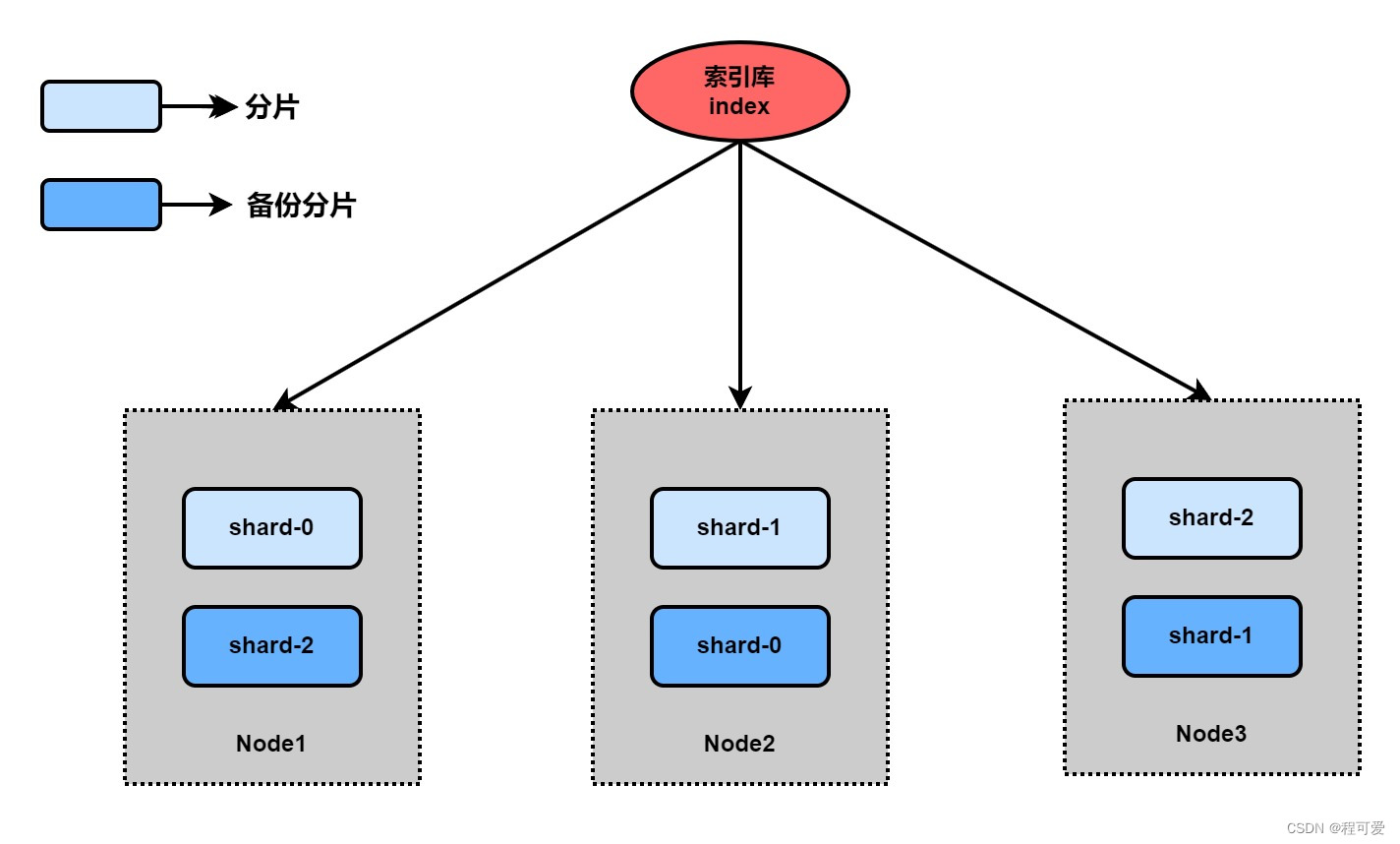
以上述三台机器为例,机器1上备份了shard-2,机器2上备份了shard-0,机器3上备份了shard-1,即使机器1挂掉,机器2和机器3上也包含了完整的shard-0、shard-1、shard-2数据。
3.小结
1.聚合必须三要素为:聚合名称、聚合类型、聚合字段;
2.聚合可配置属性有:size(指定聚合结果数量)、order(指定聚合结果排序方式)、field(指定聚合字段);
3.拼音分词器适合在创建倒排索引的时候使用,但不能在搜索的时候使用;
4.参考文献
1.https://docs.spring.io/spring-data/elasticsearch/docs/current/reference/html
2.https://www.bilibili.com/video/BV1LQ4y127n4
3.https://www.elastic.co/guide/en/elasticsearch/reference/6.0/search-aggregations-bucket-datehistogram-aggregation.html
5.附录
1.https://gitee.com/Marinc/nacos.git