1.什么是ResNet
残差神经网络(ResNet)是由微软研究院的何恺明、张祥雨、任少卿、孙剑等人提出的。ResNet 在2015 年的ILSVRC(ImageNet Large Scale Visual Recognition Challenge)中取得了冠军。残差神经网络的主要贡献是发现了“退化现象(Degradation)”,并针对退化现象发明了 “快捷连接(Shortcut connection)”,极大的消除了深度过大的神经网络训练困难问题。 下面我将一步步引出退化现象和快捷连接。
假设一个层数较少的神经网络已经达到了较高准确率,我们可以在这个神经网络之后,拼接一段恒等变换的网络层,这些恒等变换的网络层对输入数据不做任何转换,直接返回(y=x),就能得到一个深度较大的神经网络,并且,这个深度较大的神经网络的准确率等于拼接之前的神经网络准确率,准确率没有理由降低。层数较多的神经网络,可由较浅的神经网络和恒等变换网络拼接而成,如图所示。

1.1退化现象
由上述我们可知,随着网络深度增加,是不是准确率会一直增加呢?但是通过实验,ResNet随着网络层不断的加深,模型的准确率先是不断的提高,达到最大值(准确率饱和),然后随着网络深度的继续增加,模型准确率毫无征兆的出现大幅度的降低。这个现象与“越深的网络准确率越高”的信念显然是矛盾的、冲突的。ResNet团队把这一现象称为“退化(Degradation)”。ResNet团队把退化现象归因为深层神经网络难以实现“恒等变换(y=x)”。乍一看,让人难以置信,原来能够模拟任何函数的深层神经网络,竟然无法实现恒等变换这么简单的映射了?
让我们来回想深度学习的起源,与传统的机器学习相比,深度学习的关键特征在于网络层数更深、非线性转换(激活)、自动的特征提取和特征转换,其中,非线性转换是关键目标,它将数据映射到高纬空间以便于更好的完成“数据分类”。随着网络深度的不断增大,所引入的激活函数也越来越多,数据被映射到更加离散的空间,此时已经难以让数据回到原点(恒等变换)。或者说,神经网络将这些数据映射回原点所需要的计算量,已经远远超过我们所能承受的。
退化现象让我们对非线性转换进行反思,非线性转换极大的提高了数据分类能力,但是,随着网络的深度不断的加大,我们在非线性转换方面已经走的太远,竟然无法实现线性转换。显然,在神经网络中增加线性转换分支成为很好的选择,于是,ResNet团队在ResNet模块中增加了快捷连接分支,在线性转换和非线性转换之间寻求一个平衡。
1.2快捷连接
这个概念的核心思想是通过添加额外的连接来解决深度神经网络训练中的梯度消失和梯度爆炸等问题,从而允许构建非常深的神经网络。
ResNet通过引入快捷连接,允许某一层的输出直接跳过一个或多个层,连接到后续层的输入。这样做的好处是,即使某些层不做任何有意义的变换,它们仍然可以传递之前层的信息,而不会对梯度产生过多的损失。这可以用一个公式来表示:

那现在要解决的就是学习恒等映射函数了。 但是直接让一些层去拟合一个潜在的恒等映射函数H(x) = x,比较困难,这可能就是深层网络难以训练的原因。但是,如果把网络设计为H(x) = F(x) + x,如上图。我们可以转换为学习一个残差函数F(x) = H(x) - x. 只要F(x)=0,就构成了一个恒等映射H(x) = x. 而且,拟合残差肯定更加容易。
残差:观测值与估计值之间的差。
这里H(x)就是观测值,x就是估计值(也就是上一层ResNet输出的特征映射)。
我们一般称x为identity Function,它是一个跳跃连接;称F(x)为ResNet Function。
那么咱们要求解的问题变成了H(x) = F(x)+x。
注意:如果残差映射(F(x))的结果的维度与跳跃连接(x)的维度不同,那咱们是没有办法对它们两个进行相加操作的,必须对x进行升维操作,让他俩的维度相同时才能计算。
升维的方法有两种:
- 全0填充;
- 采用1*1卷积。
2.ResNet结构图
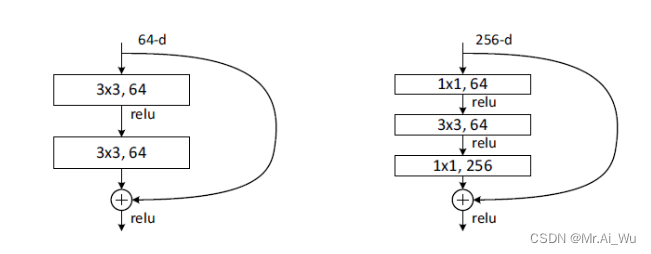
下图是论文给出的不同ResNet网络的层次需求

2.1ResNet18网络结构图
ResNet18的基本含义是,网络的基本架构是ResNet,网络的深度是18层。但是这里的网络深度指的是网络的权重层,也就是包括池化,激活,线性层。而不包括批量化归一层,池化层。
下图就是一个ResNet18的基本网络架构,其中并未加入批量化归一和池化层。
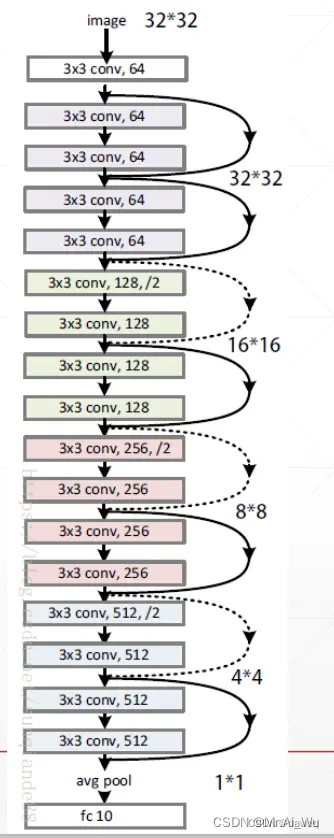
2.2具体解析网络中的大小和通道的变化
我们可以看到假设输入数据的大小为3*224*224,也就是3个通道,每个通道的大小为224*224。
(1)7*7卷积层
首先根据论文中所说的首先经过一个卷积层。这个卷积层的卷积核的大小为7*7,步长为2,padding为3,输出通道为64。根据公式:
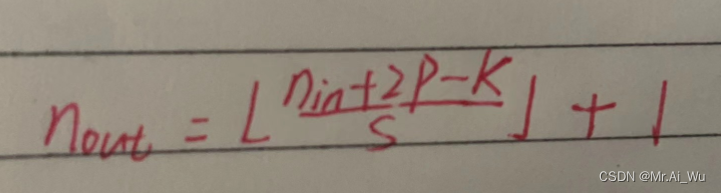
我们可以算出最后输出数据的大小为64*112*112.
(2)池化层
这里通过一个最大池化层,这一层的卷积核的大小是3*3,步长为2,padding为1。最后输出数据的大小为64*56*56
也就是说这个池化不改变数据的通道数量,而会减半数据的大小。
(3)第一个3*3卷积层
第一个卷积3*3卷积层,卷积核的大小为3*3,步长为1,padding为1。最后通过两个第一个卷积层的输出数据大小为64*56*56,也就是这一层不改变数据的大小和通道数。
(4)第二个3*3卷积层
首先通过一个1*1的卷积层,并经过一个下采样。这样最后的输出数据为128*28*28。也就是将输出通道翻倍,输出数据大小全部减半。
(5)第三个3*3卷积层
同样进行1*1卷积,和下采样。这样最后的输出为256*14*14。也就是将输出通道翻倍,输出数据大小全部减半。
(6)第四个3*3卷积层
和上述同理,最后的输出为512*7*7。也就是将输出通道翻倍,输出数据大小全部减半。
(7)平均池化层
最后输出为512*1*1
(8)线性层

3.ResNet-18实践
具体可见,本人发表的基于ResNet-18的阿里云天池-真零基础入门CV-定长字符识别
------------------------->https://blog.csdn.net/m0_64799972/article/details/132725566?spm=1001.2014.3001.5502