USPS手写数字识别
我们首先对USPS手写数字数据集进行预处理。使用 torchvision.transforms 将图像大小调整为32x32,以适应LeNet-5模型。同时,将图像转换为Tensor格式。
from torchvision.datasets import USPS
from torchvision import transforms
transform = transforms.Compose([transforms.Resize((32, 32)), transforms.ToTensor()])
train_dataset = USPS(root='USPS/train', train=True, transform=transform, download=True)
test_dataset = USPS(root='USPS/test', train=False, transform=transform, download=True)
为了方便处理USPS数据集,我们自定义一个数据集类 USPostalDataset,继承自 torch.utils.data.Dataset。该类负责读取图像数据和标签,并支持数据集长度查询和按索引获取数据。
import os
import torch
from torch.utils.data import Dataset
from PIL import Image
class USPostalDataset(Dataset):
"""读取数据集"""
def __init__(self, root_dir, train=True, transform=None):
self.root_dir = root_dir
self.train = train
self.transform = transform
if self.train:
self.data_dir = os.path.join(self.root_dir, 'train')
else:
self.data_dir = os.path.join(self.root_dir, 'test')
self.imgs = []
self.labels = []
for label in os.listdir(self.data_dir):
label_dir = os.path.join(self.data_dir, label)
for img_name in os.listdir(label_dir):
self.imgs.append(os.path.join(label_dir, img_name))
self.labels.append(int(label))
def __len__(self):
return len(self.imgs)
def __getitem__(self, idx):
img_path = self.imgs[idx]
image = Image.open(img_path).convert('L')
label = self.labels[idx]
if self.transform:
image = self.transform(image)
return image, label
def display_dataset_info(dataset):
"""显示数据集信息"""
print(f"Number of samples: {
len(dataset)}")
print(f"Number of classes: 10")
print(f"Image size: {
dataset[0][0].shape}")
display_dataset_info(train_dataset)
display_dataset_info(test_dataset)
LeNet-5是一种卷积神经网络,主要包括两个卷积层、两个池化层和三个全连接层。在本例中,我们还添加了Dropout层以防止过拟合。激活函数可以选择ReLU、LeakyReLU或Sigmoid。
import torch.nn as nn
import torch.nn.functional as F
class LeNet5Model(nn.Module):
"""LeNet5 CNN模型
包含:
- 两个卷积层:Conv2d(1, 6, 5), Conv2d(6, 16, 5)
- 两个池化层:MaxPool2d(kernel_size=2, stride=2)
- 三个全连接层:Linear(16 * 5 * 5, 120), Linear(120, 84), Linear(84, 10)
- Dropout with drop rate of 0.5
- ReLU激活函数
"""
def __init__(self, activation='relu', drop_rate=0.5):
super(LeNet5Model, self).__init__()
self.activation = activation
self.drop_rate = drop_rate
# 两个卷积层
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# 两个池化层
self.pool1 = nn.MaxPool2d(2, 2)
self.pool2 = nn.MaxPool2d(2, 2)
# 三个全连接层
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
# self.softmax = nn.Softmax(dim=1)
# Dropout层
self.dropout = nn.Dropout(self.drop_rate)
# 选择激活函数
if activation == 'relu':
self.act = nn.ReLU()
if activation == 'leaky_relu':
self.act = nn.LeakyReLU()
if activation == 'sigmoid':
self.act = nn.Sigmoid()
def forward(self, x):
# 第一个卷积层
x = self.act(self.conv1(x))
# 第一个池化层
x = self.pool1(x)
# 第二个卷积层
x = self.act(self.conv2(x))
# 第二个池化层
x = self.pool2(x)
# 展平层
x = x.view(-1, 16 * 5 * 5)
# 第一个全连接层
x = self.act(self.fc1(x))
# 第一个dropout层
x = self.dropout(x)
# 第二个全连接层
x = self.act(self.fc2(x))
# 第三个全连接层
x = self.fc3(x)
# softmax层
# x = self.softmax(x)
return x
我们定义了 train 和 test 函数用于进行模型训练和测试。训练时,我们使用损失函数、优化器和学习率调度器来更新模型参数。测试时,我们使用训练好的模型计算测试集上的损失和精度。
import time
import torch.optim as optim
def train(model, dataloader, criterion, optimizer, device, loss_function):
"""训练函数
参数:
- model: 模型
- dataloader: 训练集dataloader
- criterion: 损失函数
- optimizer: 优化器
- device: 训练设备
- loss_function: 损失函数类型
"""
model.train()
train_loss = 0.0
correct = 0
total = 0
for batch_idx, (imgs, labels) in enumerate(dataloader):
# 将输入和目标载入到设备device
imgs, labels = imgs.to(device), labels.to(device)
# 如果损失函数是mse,进行独热编码
if loss_function == 'mse':
labels = F.one_hot(labels, num_classes=10).float()
labels = torch.argmax(labels, dim=1)
# 梯度清零
optimizer.zero_grad()
# 前向传播
outputs = model(imgs)
# 计算损失
loss = criterion(outputs, labels)
# 反向传播
loss.backward()
# 梯度更新
optimizer.step()
train_loss += loss.item()
# 计算正确预测的数量
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
train_acc = 100. * correct / total
# # 打印训练精度
# print(f'Accuracy: {train_acc}%')
return train_loss / (batch_idx + 1), train_acc
def test(model, dataloader, criterion, device, loss_function):
"""测试函数
参数:
- model: 模型
- dataloader: 测试集dataloader
- criterion: 损失函数
- device: 训练设备
"""
model.eval()
test_loss = 0
correct = 0
total = 0
with torch.no_grad():
for batch_idx, (imgs, labels) in enumerate(dataloader):
# 将输入和目标载入到设备device
imgs, labels = imgs.to(device), labels.to(device)
if loss_function == 'mse':
labels = F.one_hot(labels, num_classes=10).float()
# 前向传播
outputs = model(imgs)
# 计算损失
loss = criterion(outputs, labels)
test_loss += loss.item()
# 计算正确预测的数量
_, predicted = outputs.max(1)
total += labels.size(0)
if loss_function == 'mse':
labels = torch.argmax(labels, dim=1)
correct += predicted.eq(labels).sum().item() # 预测正确的数量
test_acc = 100. * correct / total
# 打印测试精度
# print(f'Accuracy: {test_acc}%')
return test_loss / (batch_idx + 1), test_acc
为了观察模型在训练过程中的表现,我们定义了一个函数 plot_training_loss_and_acc,用于绘制训练损失和精度曲线。
import matplotlib.pyplot as plt
def plot_training_loss_and_acc(training_losses, training_accuracies, num_epochs):
"""绘制训练loss和精度曲线"""
epochs = list(range(1, num_epochs + 1))
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.plot(epochs, training_losses, label='Training Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(epochs, training_accuracies, label='Training Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
为了防止过拟合,我们使用早停法提前终止训练。当连续若干个epoch训练损失没有降低时,我们认为模型已经收敛,提前结束训练。
class EarlyStopping:
"""早停法
参数:
- patience: 容忍epoch数
- delta: 阈值
"""
def __init__(self, patience=2, delta=0.0001):
self.patience = patience
self.delta = delta
self.best_loss = float("inf") # 设置初始最优损失为无穷大
self.counter = 0 # 记录当前epoch数
def check(self, loss):
"""检查是否需要早停"""
if self.best_loss - loss > self.delta: # 如果损失降低
self.best_loss = loss
self.counter = 0
else:
self.counter += 1
if self.counter >= self.patience: # 如果损失连续patience个epoch没有降低
return True
return False
要训练LeNet模型,我们需要设置一些超参数,如训练周期数、批量大小和学习率。这里,我们将使用train_lenet5_model函数,该函数接受以下参数:
- 激活函数(
activation) - 损失函数类型(
loss_function) - 训练周期数(
num_epochs) - 批量大小(
batch_size) - 学习率(
learning_rate) - Dropout比率(
dropout_rate) - 早停法的patience值(
patience)
from torch.optim.lr_scheduler import StepLR
device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu") # 设置训练设备
def train_lenet5_model(activation='relu', loss_function='ce',
num_epochs=30, batch_size=64, learning_rate=0.001,
dropout_rate=0.5, patience=3):
"""训练 LeNet5 模型
参数:
- activation: 激活函数类型
- loss_function: 损失函数类型
- num_epochs: 训练周期数
- batch_size: 批量大小
- learning_rate: 学习率
- dropout_rate: Dropout 比率
- patience: 早停法的 patience 值
"""
# 数据加载器
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 模型初始化
model = LeNet5Model(activation=activation, drop_rate=dropout_rate).to(device)
criterion = nn.CrossEntropyLoss() # 设置损失函数默认为交叉熵损失函数
if loss_function == 'ce': # 交叉熵损失函数
pass
if loss_function == 'mse': # 均方误差损失函数
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate) # Adam优化器
scheduler = StepLR(optimizer, step_size=5, gamma=0.1) # 学习率衰减
# 跟踪训练loss和精度
train_losses = []
train_accuracies = []
start_time = time.time()
# 早停法监测器
early_stopper = EarlyStopping(patience=patience)
for epoch in range(num_epochs):
print('-' * 50)
train_loss, train_accuracy = train(model, train_loader, criterion, optimizer, device, loss_function)
print(f"Epoch {
epoch + 1}/{
num_epochs}, Loss: {
train_loss:.4f}, Accuracy: {
train_accuracy:.2f}%")
train_losses.append(train_loss)
train_accuracies.append(train_accuracy)
if (epoch + 1) % 5 == 0:
test_loss, test_accuracy = test(model, test_loader, criterion, device, loss_function)
print(f"Test Loss: {
test_loss:.4f}, Test Accuracy: {
test_accuracy:.2f}%")
# 检查是否early stop
if early_stopper.check(test_loss):
print(f"Epoch {
epoch + 1}/{
num_epochs}: Early stopping. Best test loss: {
early_stopper.best_loss}.")
num_epochs = epoch + 1
break
scheduler.step()
# 训练总时间
total_time = time.time() - start_time
print(f"Total training time: {
total_time:.2f} seconds")
# 保存模型文件
torch.save(model.state_dict(), f"LeNet5_{
activation}_{
loss_function}.pth")
# 绘制训练loss和精度曲线
plot_training_loss_and_acc(train_losses, train_accuracies, num_epochs)
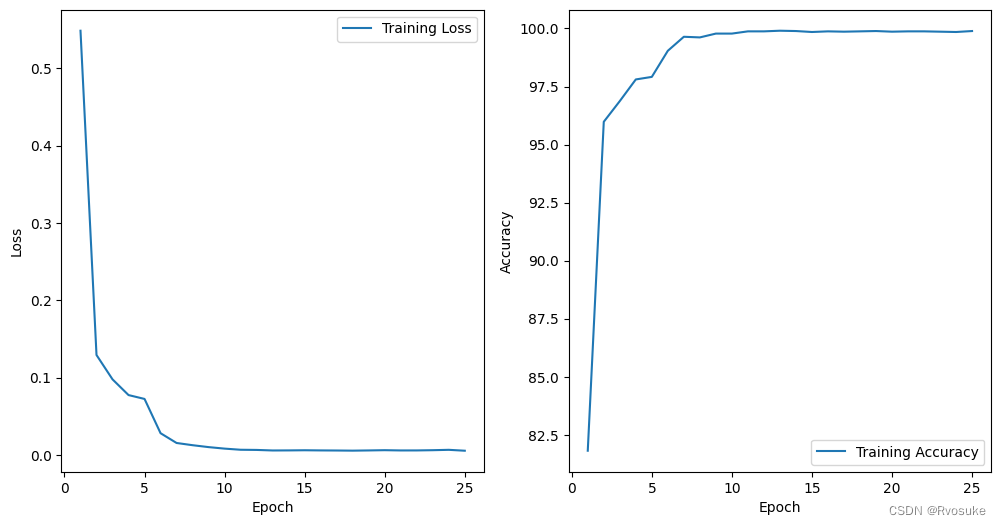
train_lenet5_model(activation='relu', loss_function='ce', num_epochs=30, batch_size=64, learning_rate=0.001, dropout_rate=0.5, patience=2)
# 激活函数为ReLU,交叉熵损失函数,迭代次数为30次,批量大小是64,比较适中,学习率0.001,步长比较小,设置dropout_rate为0.5,比较大,谨防过拟合,早停法的耐心值设为2
Epoch 20/30, Loss: 0.1748, Accuracy: 94.77%
Test Loss: 0.2881, Test Accuracy: 92.68%
Epoch 20/30: Early stopping. Best test loss: 0.28701677510980517.
Total training time: 25.67 seconds
第一个模型的设置比较稳妥,采用了都是很保守的参数设置。由于设置的dropout不低,所以模型的训练精度也不会很高,但也正是由于正则化,使得训练精度和测试精度之间并没有太大的差异。本次模型并没有触发早停发,说明模型尚未触发过拟合条件,或许可以尝试加大迭代次数,减小dropout来提升测试精度。
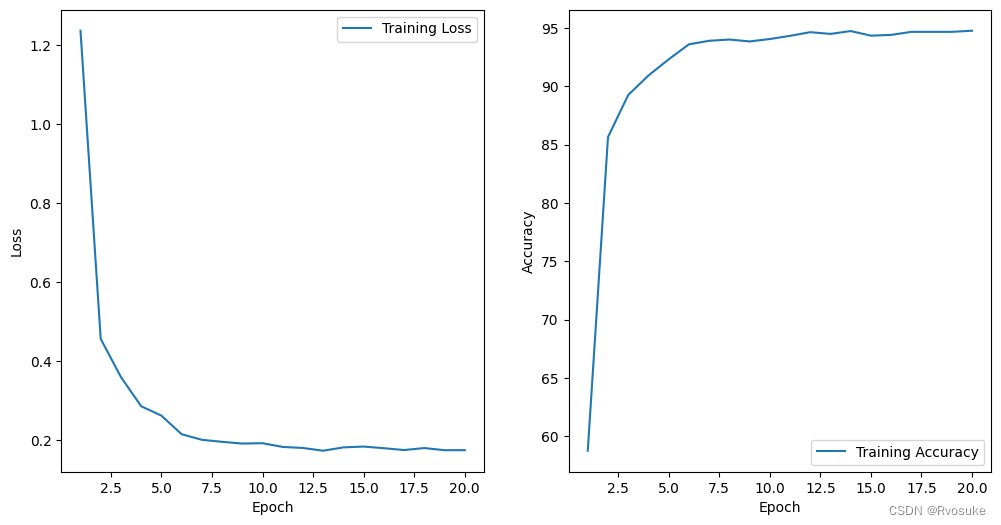
train_lenet5_model(activation='leaky_relu', loss_function='ce', num_epochs=30, batch_size=64, learning_rate=0.001, dropout_rate=0.5, patience=2)
Epoch 25/30, Loss: 0.1027, Accuracy: 96.90%
Test Loss: 0.2333, Test Accuracy: 93.92%
Epoch 25/30: Early stopping. Best test loss: 0.2331730374135077.
Total training time: 32.30 seconds
第二个模型与第一个模型仅仅是更换了激活函数,却触发了早停,可以看出leaky_relu在训练精度上有了一定的提升,而测试精度提升不大。考虑继续使用leaky relu
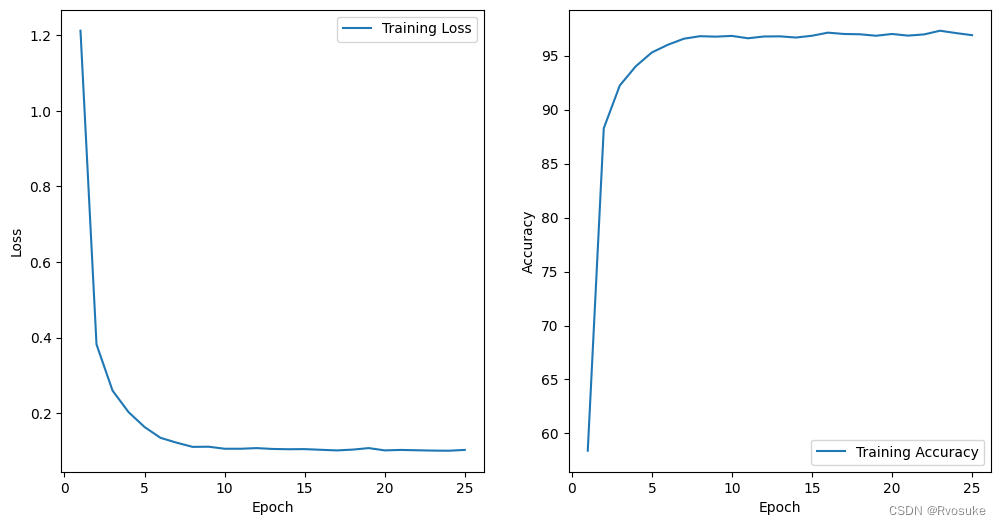
train_lenet5_model(activation='leaky_relu', loss_function='ce', num_epochs=30, batch_size=64, learning_rate=0.01, dropout_rate=0.1, patience=2)
Epoch 20/30, Loss: 0.0069, Accuracy: 99.86%
Test Loss: 0.2167, Test Accuracy: 96.11%
Epoch 20/30: Early stopping. Best test loss: 0.2119395238114521.
Total training time: 25.86 seconds
在第三个模型中我们增大了学习率,减小了dropout,由于我们在模型训练函数中设置了学习率衰退,所以我们可以尝试比较大的学习率来加快收敛速度,并减小后期的过拟合风险。可以看出本次训练较早地触发了早停发,收敛速度确实有所提升,而由于dropout的减小,模型的训练精度大大提高(99.86%),同时值得高兴的是测试精度也获得了不小的提升(突破了96.11%),所以我们可以将这个参数设置认为是最好的。(注意,使用同一模型进行训练后,生成的模型文件会替换掉原来的文件)
train_lenet5_model(activation='sigmoid', loss_function='ce', num_epochs=30, batch_size=64, learning_rate=0.01, dropout_rate=0.01, patience=2)
Epoch 25/30, Loss: 0.0606, Accuracy: 98.45%
Test Loss: 0.2493, Test Accuracy: 93.52%
Epoch 25/30: Early stopping. Best test loss: 0.24935081833973527.
Total training time: 32.46 seconds
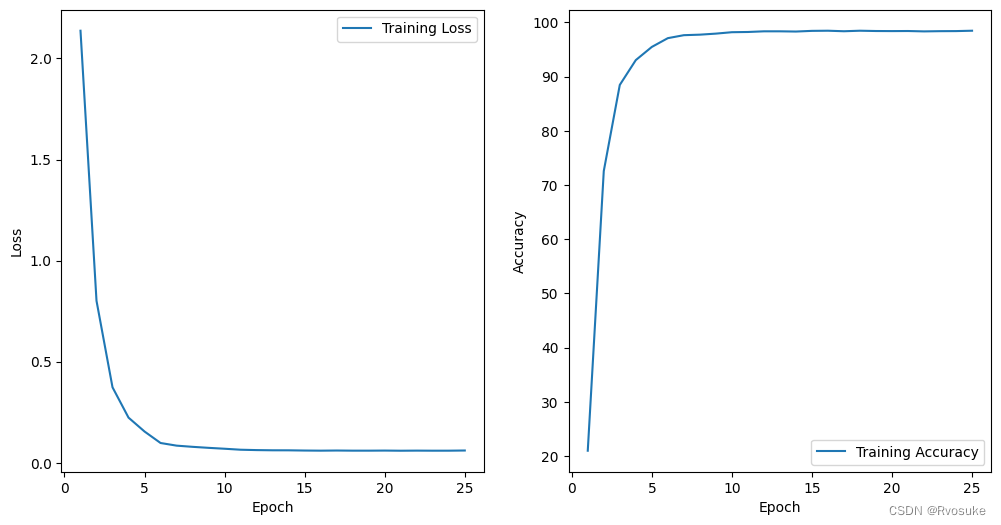
这一次采用上次模型的参数,更换激活函数为sigmoid函数。发现dropout设置为0.1时,模型的测试精度比较差(小于90%),所以采用更小的dropout或者不适用dropout。 在设置dropout为0.01后,我们发现测试精度来到了93.52%
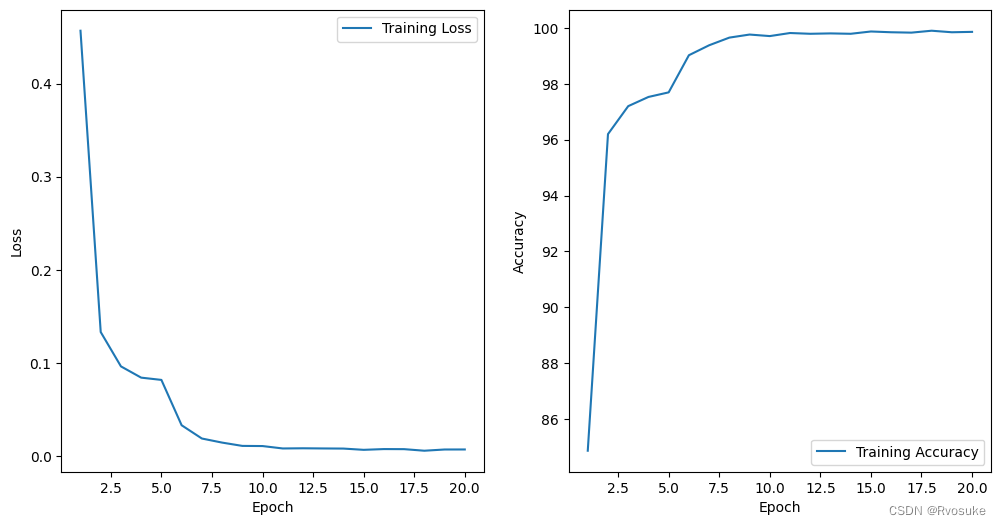
train_lenet5_model(activation='relu', loss_function='ce', num_epochs=40, batch_size=64, learning_rate=0.01, dropout_rate=0.01, patience=3)
Epoch 25/40, Loss: 0.0053, Accuracy: 99.89%
Test Loss: 0.2277, Test Accuracy: 96.26%
Epoch 25/40: Early stopping. Best test loss: 0.22380339703522623.
Total training time: 32.21 seconds
在经过多次调参后,我们发现dropout设置为0时,甚至没有设置为0.01训练精度高,另外对于批量大小的设定,大批量速度会降低,小批量精度会降低,而有意思的是,我将批量设置为32或者64是比16要更好的,这有可能是因为触发了过拟合。