我们知道 Elastics Learned Sparse EncoderR (ELSER) 可以被用来做语义搜索。它是一个 out-of-domain 的语义搜索模型。无需训练,我们就可以得到很好的相关性。有关 ELSER 的更多知识,请参考文章 “Elastic Learned Sparse Encoder 简介:Elastic 用于语义搜索的 AI 模型”。在传统的 BM25 搜索中,我们可以对所需要搜索的文字进行分词。它也可以得到很好的召回率。那么,他们在实际的使用中,有什么区别呢?在今天的文章中,我们将通过一个实际的例子来进行展示。我们针对同样一段文字,同时使用 BM25 及 ELSER 来对它们进行搜索,我们可以看看他们的相关性如何。
在本展示中,我们将使用最新的 Elastic Stack 8.11 来进行展示。你将需要部署 Elasticsearch (> 8.11) 并部署 ELSER 模型。
安装
安装 Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana,那么请参考一下的文章来进行安装:
在安装的时候,请选择 Elastic Stack 8.x 进行安装
为了能够正确使用 ELSER,我们必须订阅白金版或试用:
部署 ELSER
我们可以参考文章 “Elasticsearch:部署 ELSER - Elastic Learned Sparse EncoderR” 来部署 ELSER。
安装 Enterprise Search
我们可以参考文章 “Enterprise:使用 MySQL connector 同步 MySQL 数据到 Elasticsearch” 来安装 Enterprise Search。这里就不再累述了。
装载数据
最好的方法是使用企业搜索创建新索引并配置摄取管道以丰富数据。从 Kibana 的登录页面导航至 “Search”。
创建索引
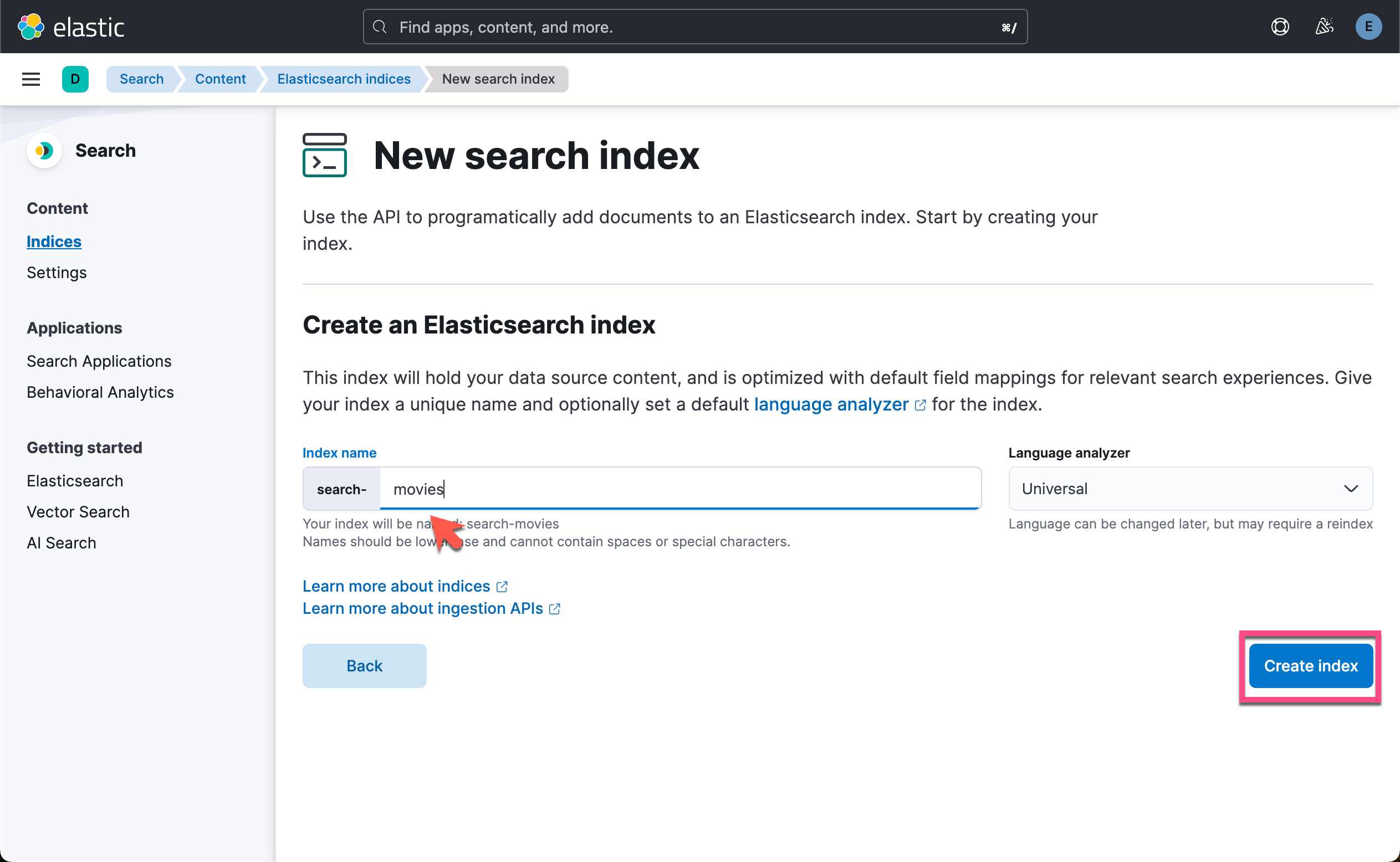
在上面我们创建一个叫做 search-movies 的索引。
配置 ingest pipeline
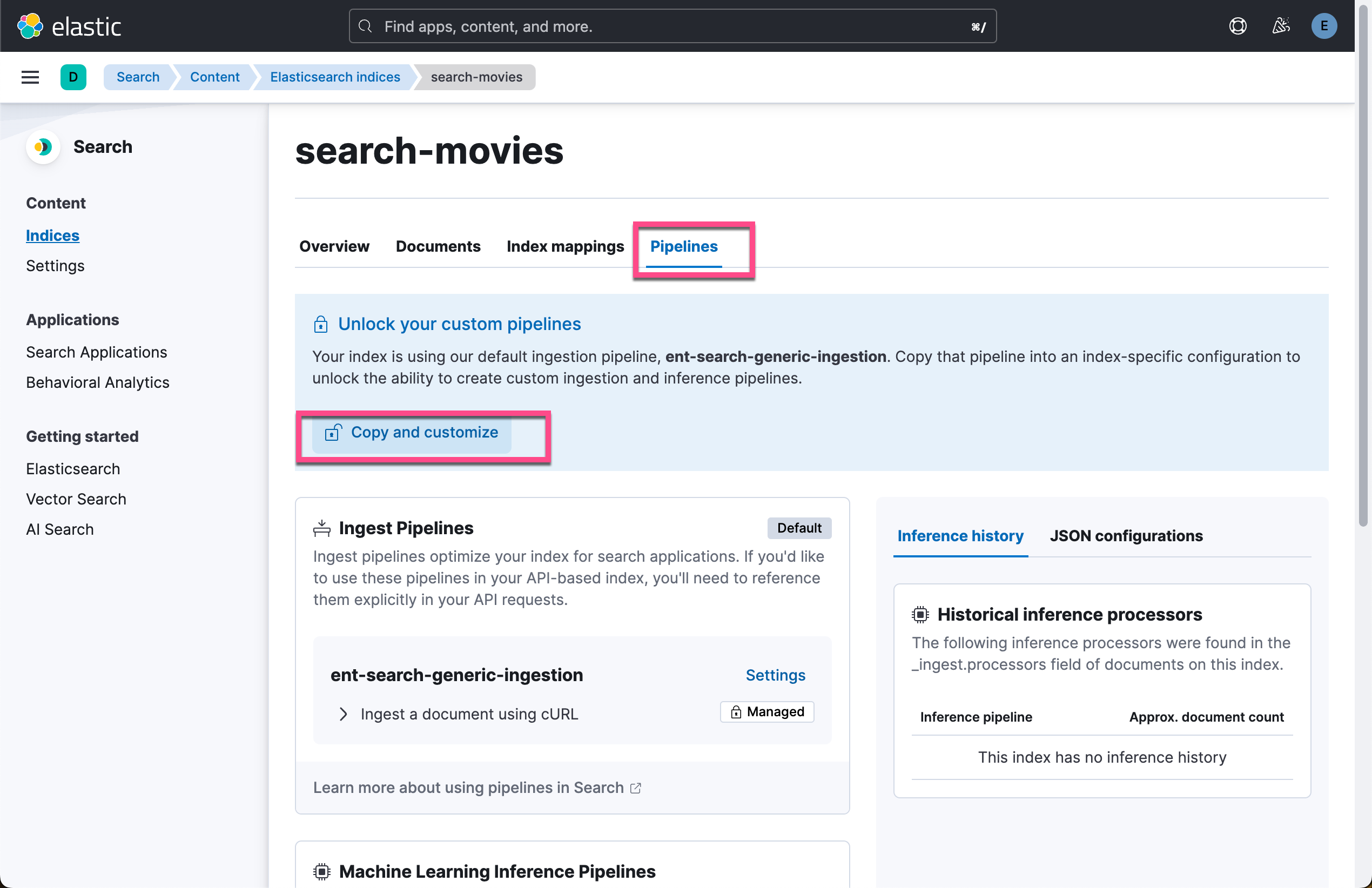
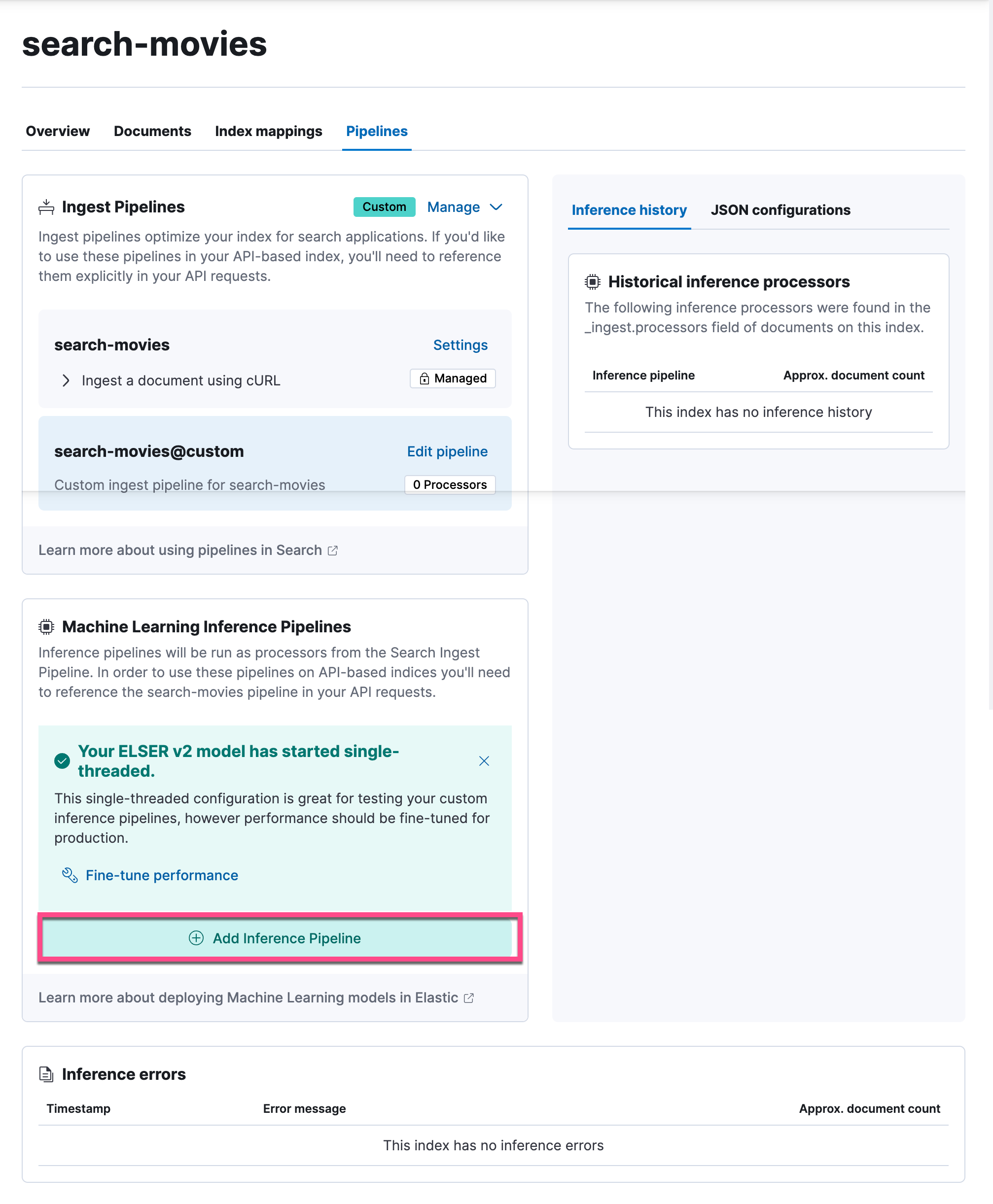
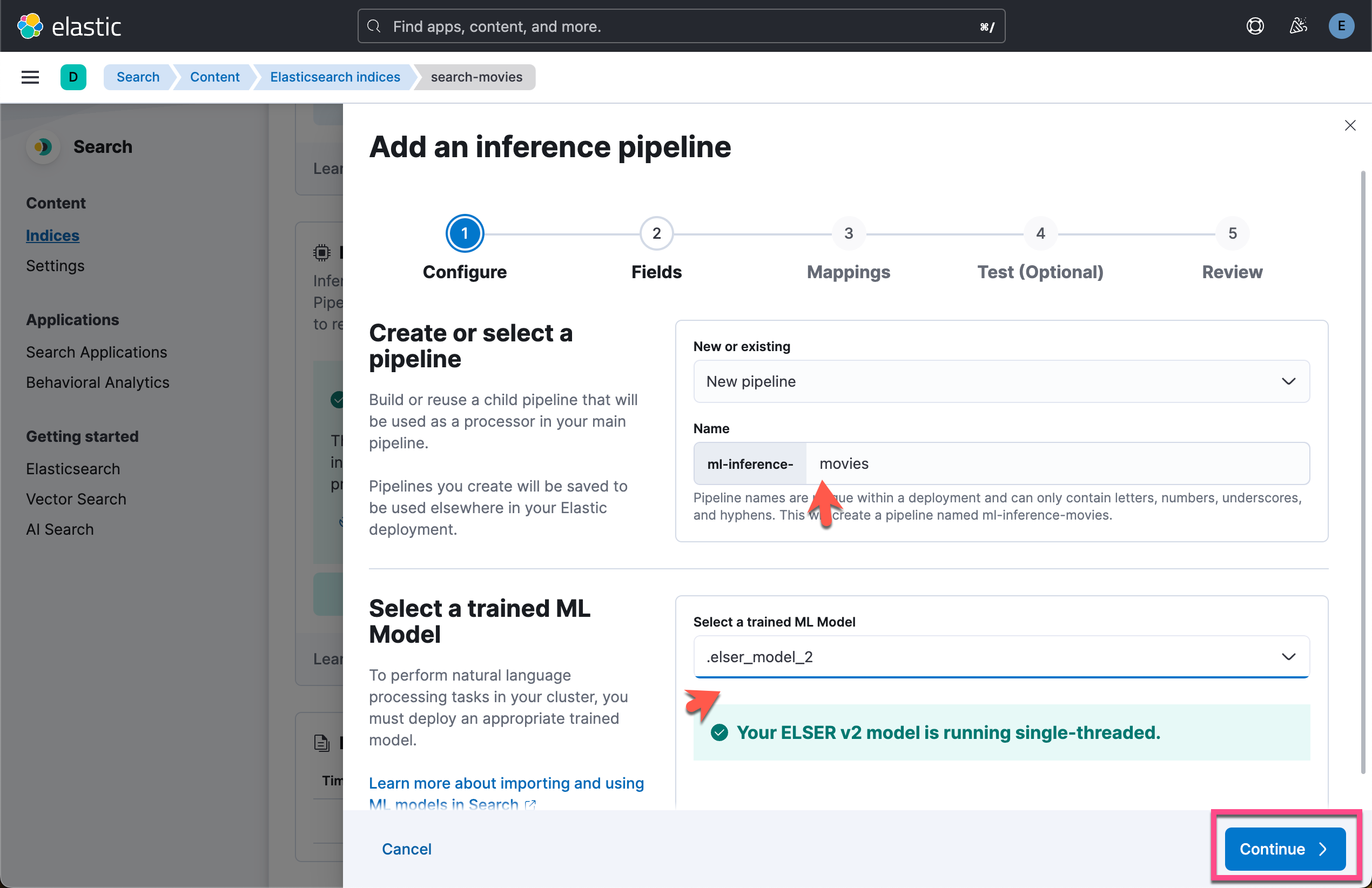
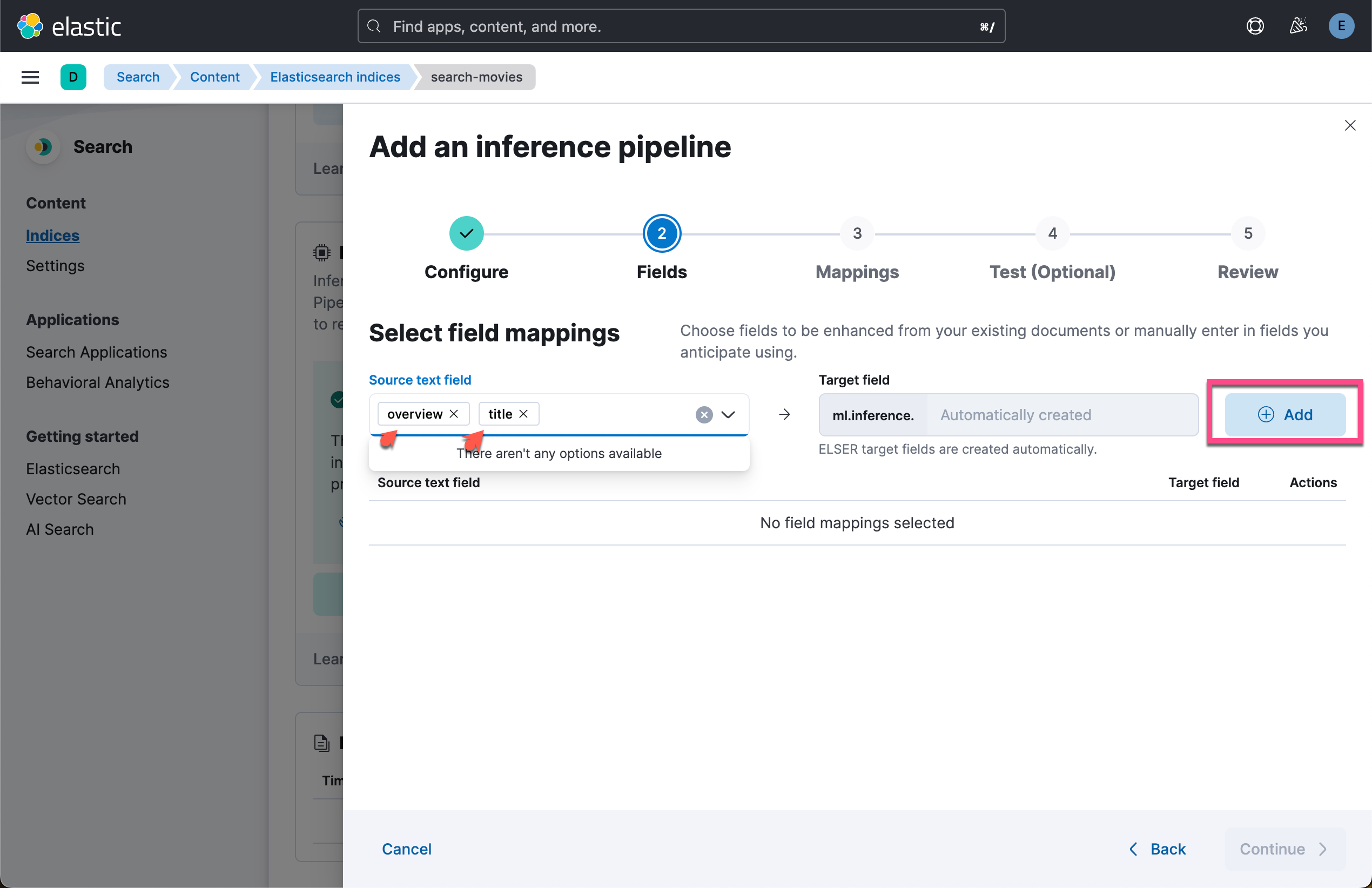
在索引配置屏幕上,导航到 “Pipelines” 选项卡,然后单击 “Copy and customize”。
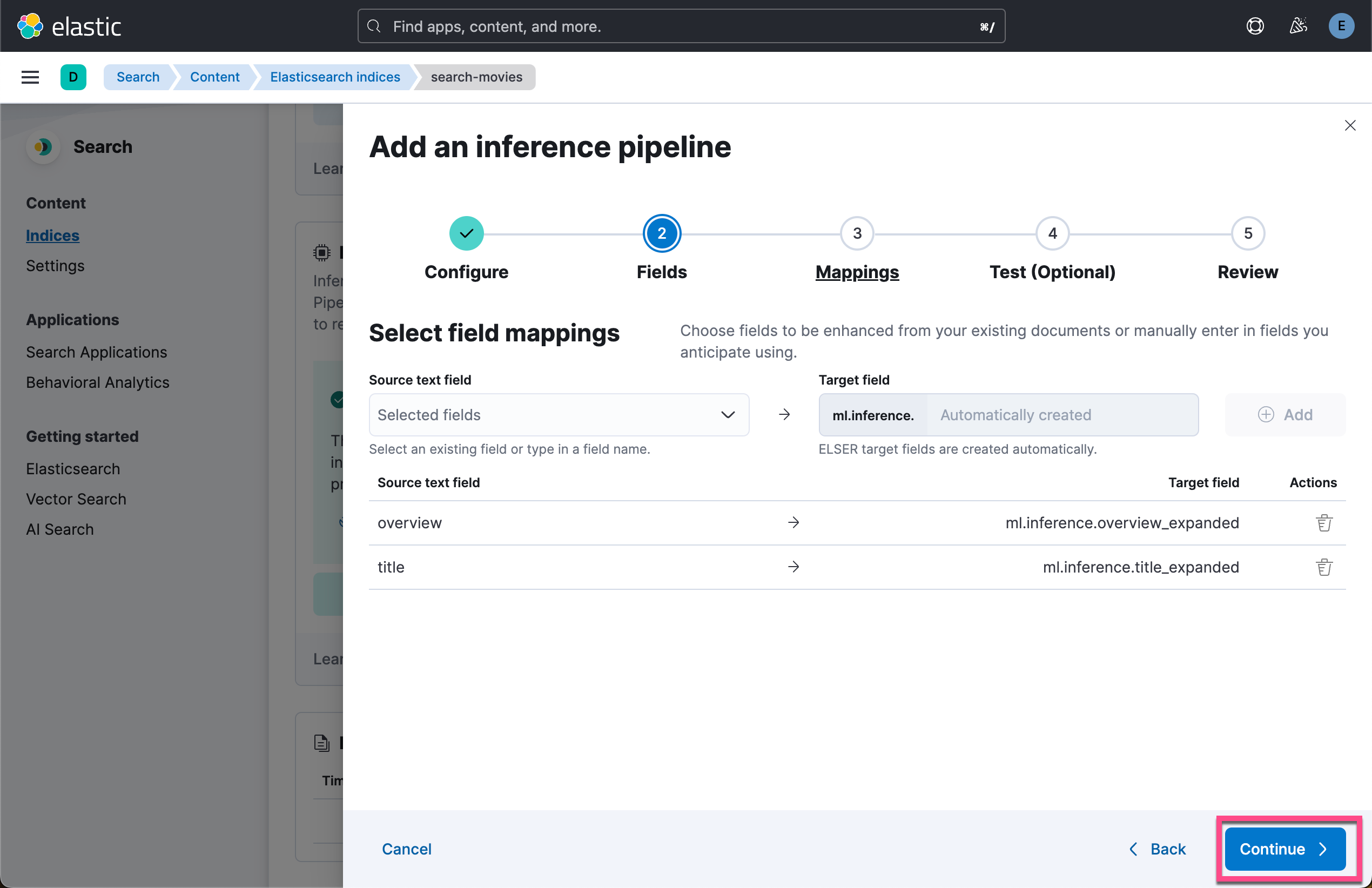
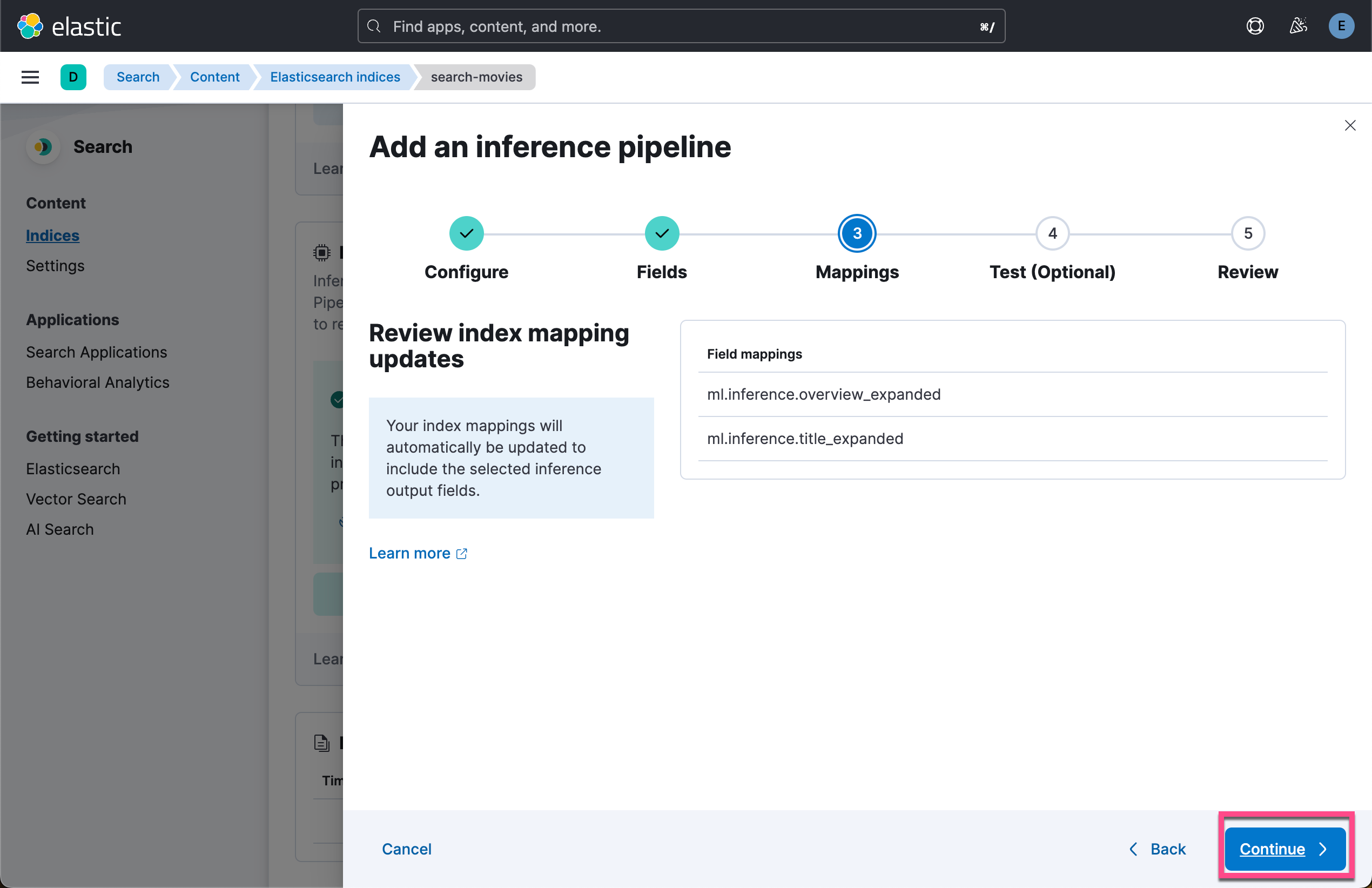

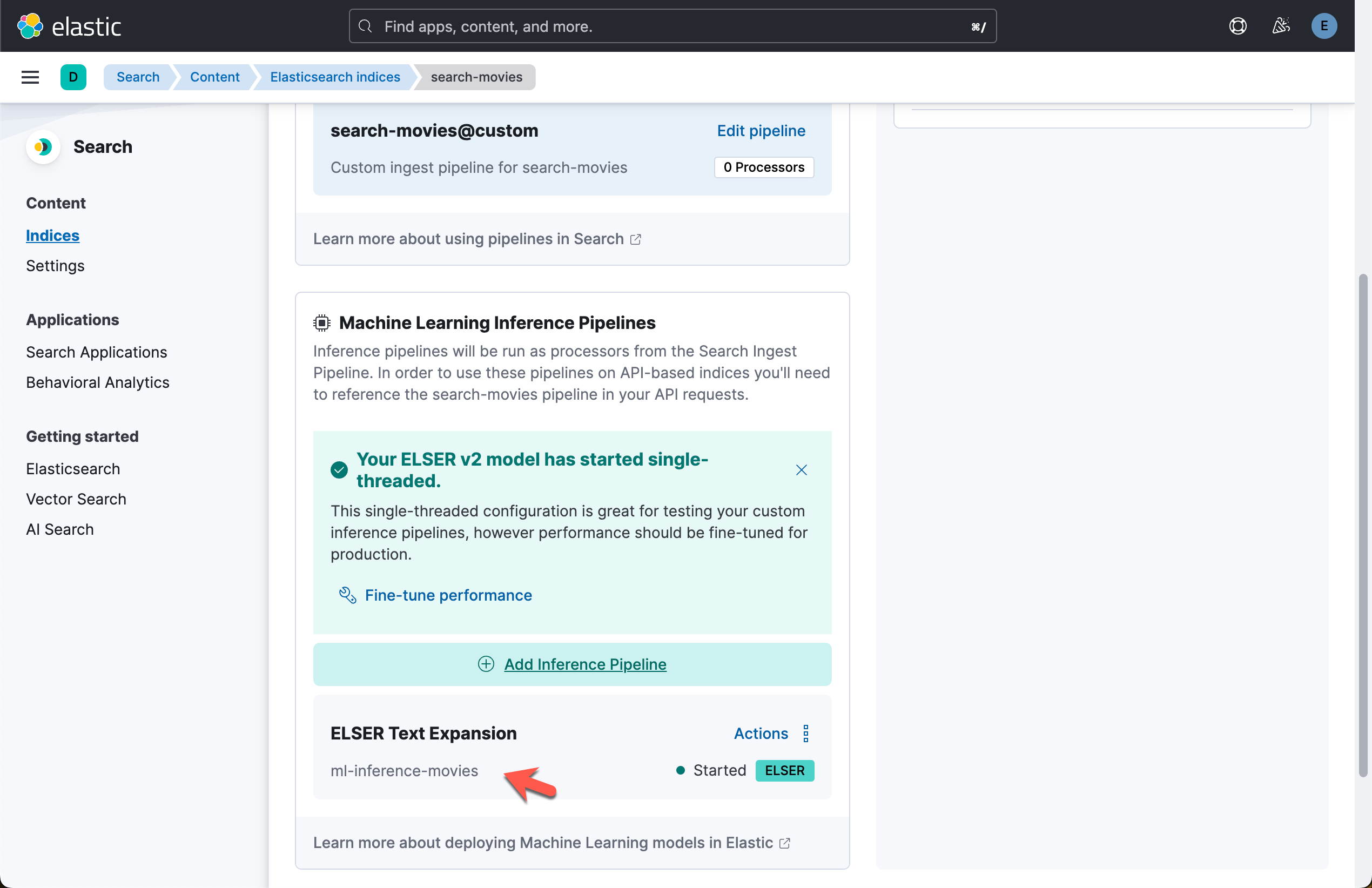
运行脚本来摄入数据
转到文件夹 data 并运行 python 脚本 index-data.py 以提取电影数据集。
为了将其连接到正确的 Elasticsearch 实例,我们需要需要把相应的 Elasticsearch 证书拷贝到当前的目录中。
$ pwd
/Users/liuxg/python/elasticsearch-labs/example-apps/relevance-workbench/data
$ cp ~/elastic/elasticsearch-8.11.0/config/certs/http_ca.crt .
$ ls
http_ca.crt movies-sample.json.gz requirements.txt
index-data.py movies.json.gz我们按照如下的步骤来运行脚本:
python3 -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
接下来,我们使用如下的命令来写入数据:
python3 index-data.py --es_password=o6G_pvRL=8P*7on+o6XH --es_url=https://localhost:9200$ python3 index-data.py --es_password=o6G_pvRL=8P*7on+o6XH --es_url=https://localhost:9200
Init Elasticsearch client
{'name': 'liuxgm.local', 'cluster_name': 'elasticsearch', 'cluster_uuid': 'n1BjmRPcR2GObT6ZMbJ9xA', 'version': {'number': '8.11.0', 'build_flavor': 'default', 'build_type': 'tar', 'build_hash': 'd9ec3fa628c7b0ba3d25692e277ba26814820b20', 'build_date': '2023-11-04T10:04:57.184859352Z', 'build_snapshot': False, 'lucene_version': '9.8.0', 'minimum_wire_compatibility_version': '7.17.0', 'minimum_index_compatibility_version': '7.0.0'}, 'tagline': 'You Know, for Search'}
Indexing movies data, this might take a while...
100%|█████████████████████████████████████████████████████████████████████████████████████████████| 100/100 [00:12<00:00, 8.19documents/s, success=100]
Indexing completed! Success percentage: 100.0%
Done indexing movies data你需要根据自己的 Elasticsearch 密码进行相应的修改。请注意,这里的密码默认的是超级用户 elastic 的密码。
请注意,默认情况下,仅对数据集的子集(100 部电影)建立索引。 如果你有兴趣对整个数据(7918 部电影)建立索引,可以通过在命令行中添加选项 --gzip_file=movies.json.gz 来选择 movie.json.gz 文件。 请注意,索引完整数据集可能需要长达 1 小时的时间。
等写入完数据,我们可以在 Kibana 中进行查看:
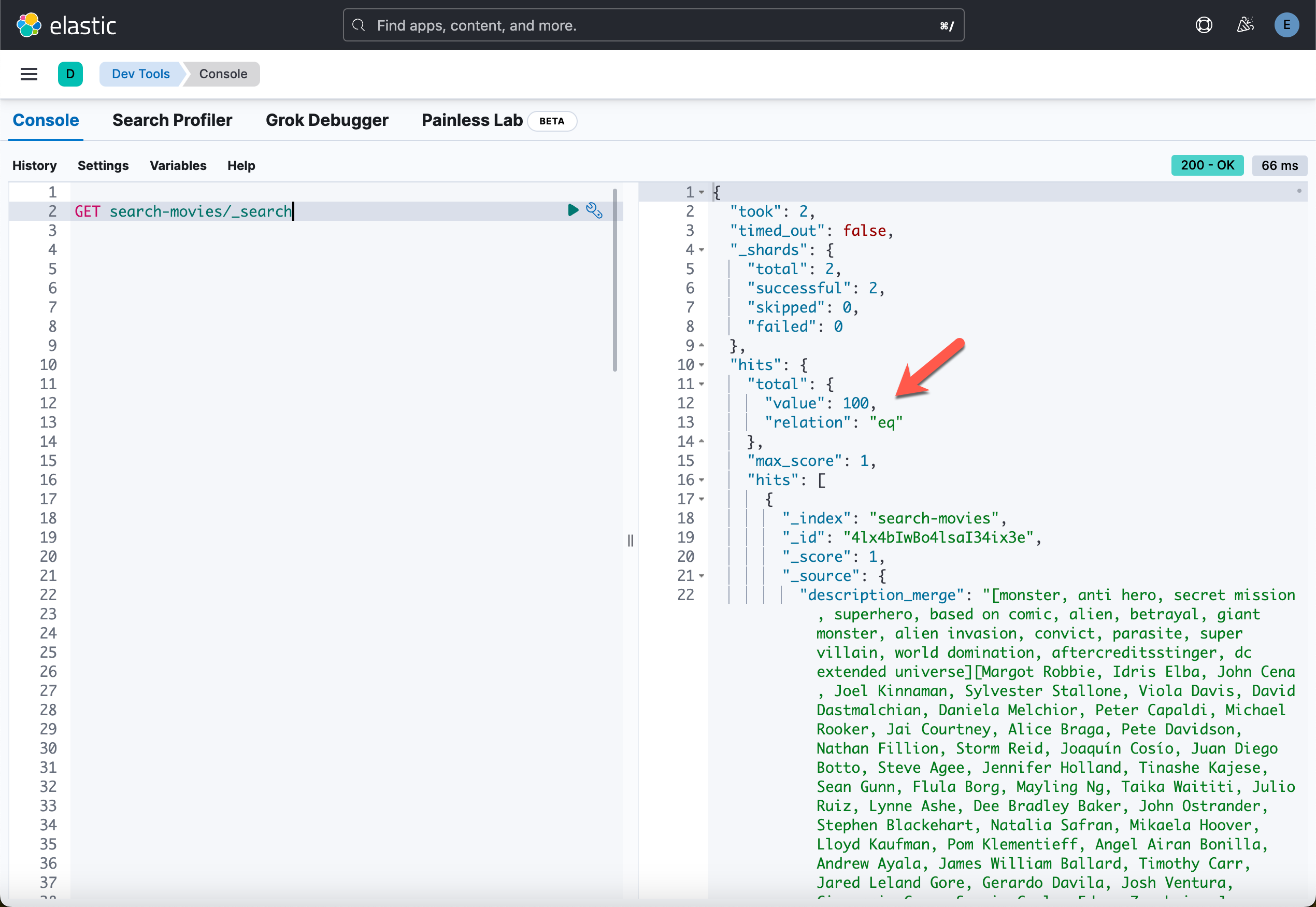
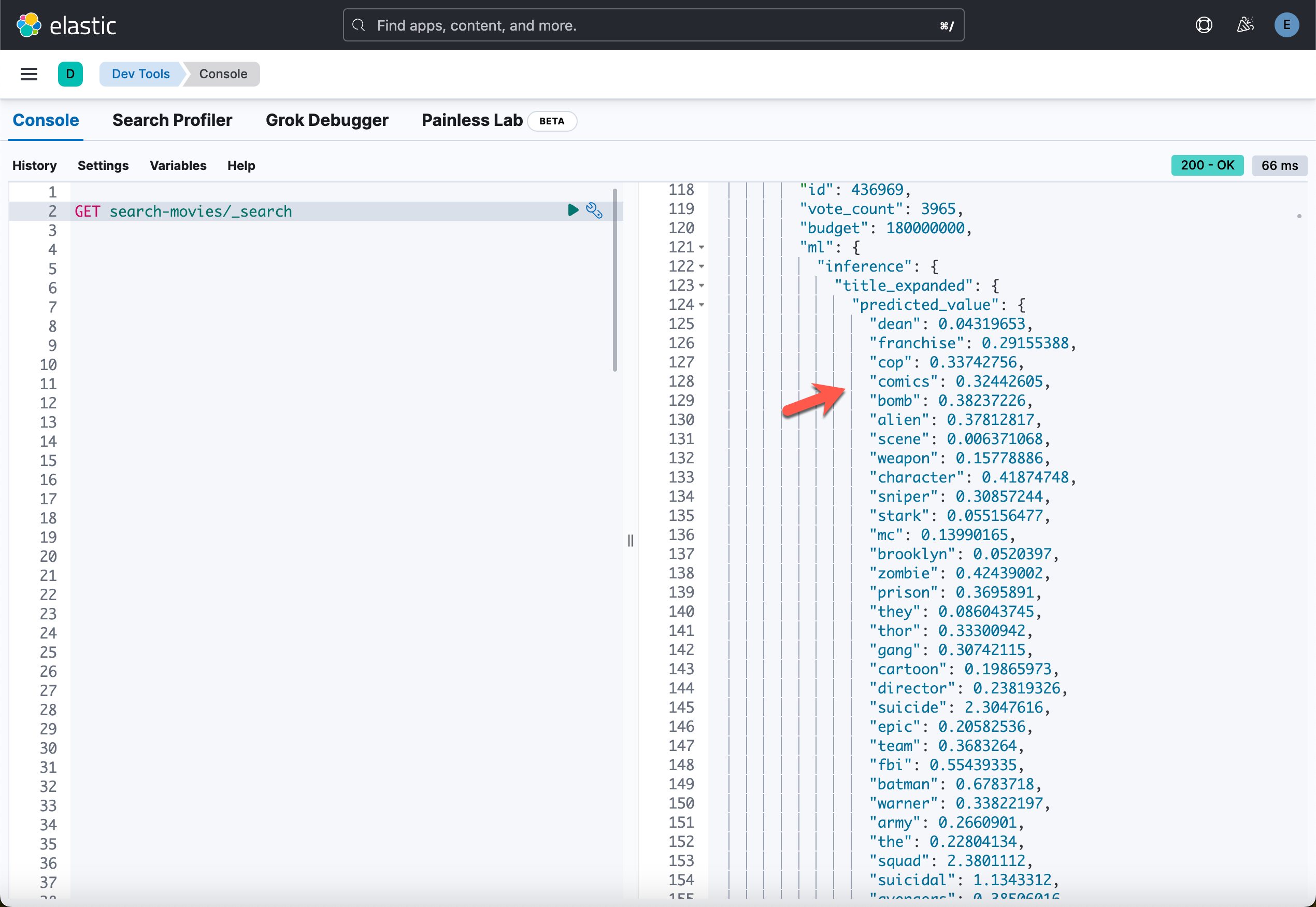
运行应用
一旦数据成功建立索引,你就可以运行应用程序来开始比较相关性模型。
该应用程序由后端 Python API 和 React 前端组成。 你可以使用 Docker compose 在本地运行整个应用程序。
编辑 docker-compose.yml 文件以替换其值。 重复使用用于加载数据的相同信息。
为了能够使得 docker 能够针对自签名的 Elasticsearch 部署起作用,我们把证书拷贝到当前的目录中:
(.venv) $ pwd
/Users/liuxg/python/elasticsearch-labs/example-apps/relevance-workbench
(.venv) $ cp ~/elastic/elasticsearch-8.11.0/config/certs/http_ca.crt .
(.venv) $ ls
LICENSE app-api data http_ca.crt
README.md app-ui docker-compose.yml images在运行之前,我们必须确认你的 elaser id:

它必须和 app-api/app.py 里的 model_id 是一致的:
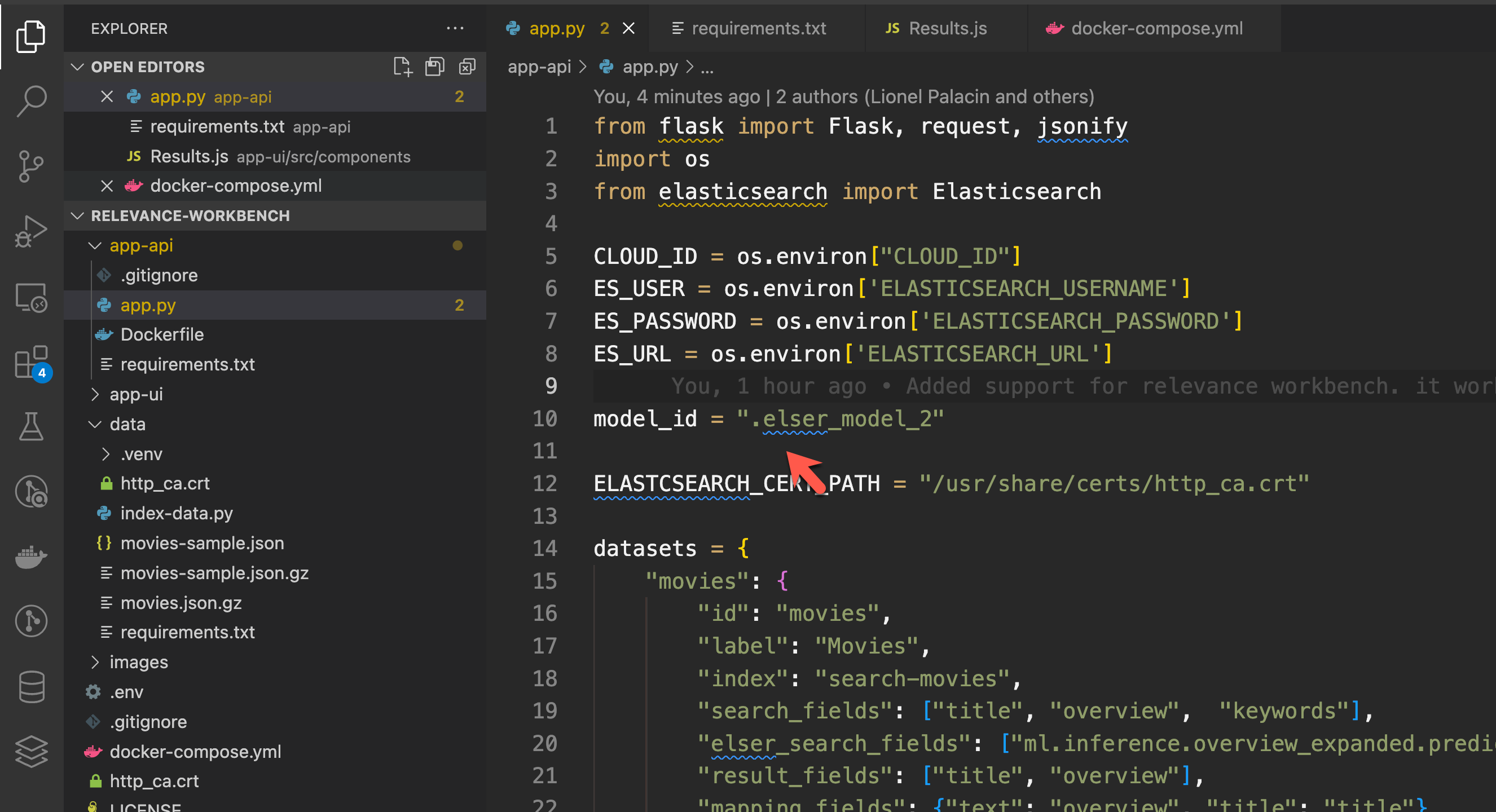
然后,我们需要使用如下的命令来启动应用:
docker-compose up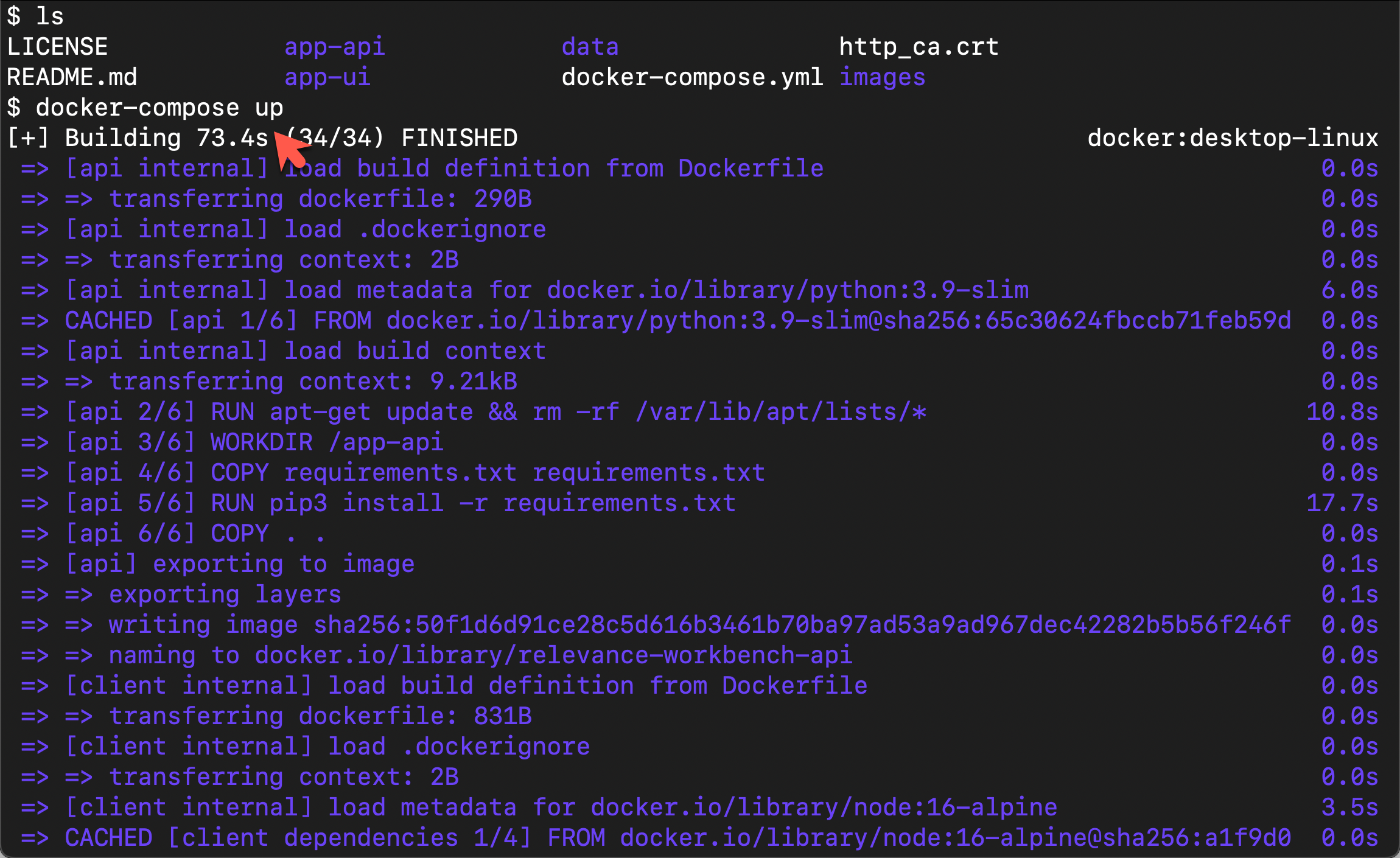
我们使用的 docker-compose.yml 文件如下:
docker-compose.yml
version: '3.7'
services:
api:
build:
context: ./app-api
dockerfile: Dockerfile
volumes:
- './app-api:/usr/src/app'
- './http_ca.crt:/usr/share/certs/http_ca.crt:ro'
ports:
- 8000:8000
environment:
- CLOUD_ID=<cloud_id>
- ELASTICSEARCH_USERNAME=elastic
- ELASTICSEARCH_PASSWORD=o6G_pvRL=8P*7on+o6XH
- ELASTICSEARCH_URL=https://192.168.0.3:9200
client:
build:
context: ./app-ui
dockerfile: Dockerfile
volumes:
- './app-ui:/usr/src/app'
ports:
- 3000:3000
environment:
- NEXT_API_URL=http://host.docker.internal:8000
depends_on:
- api
在上面,你需要根据自己的 Elasticsearch 配置来修改上面的环境变量。你需要传入相应的证书信息。
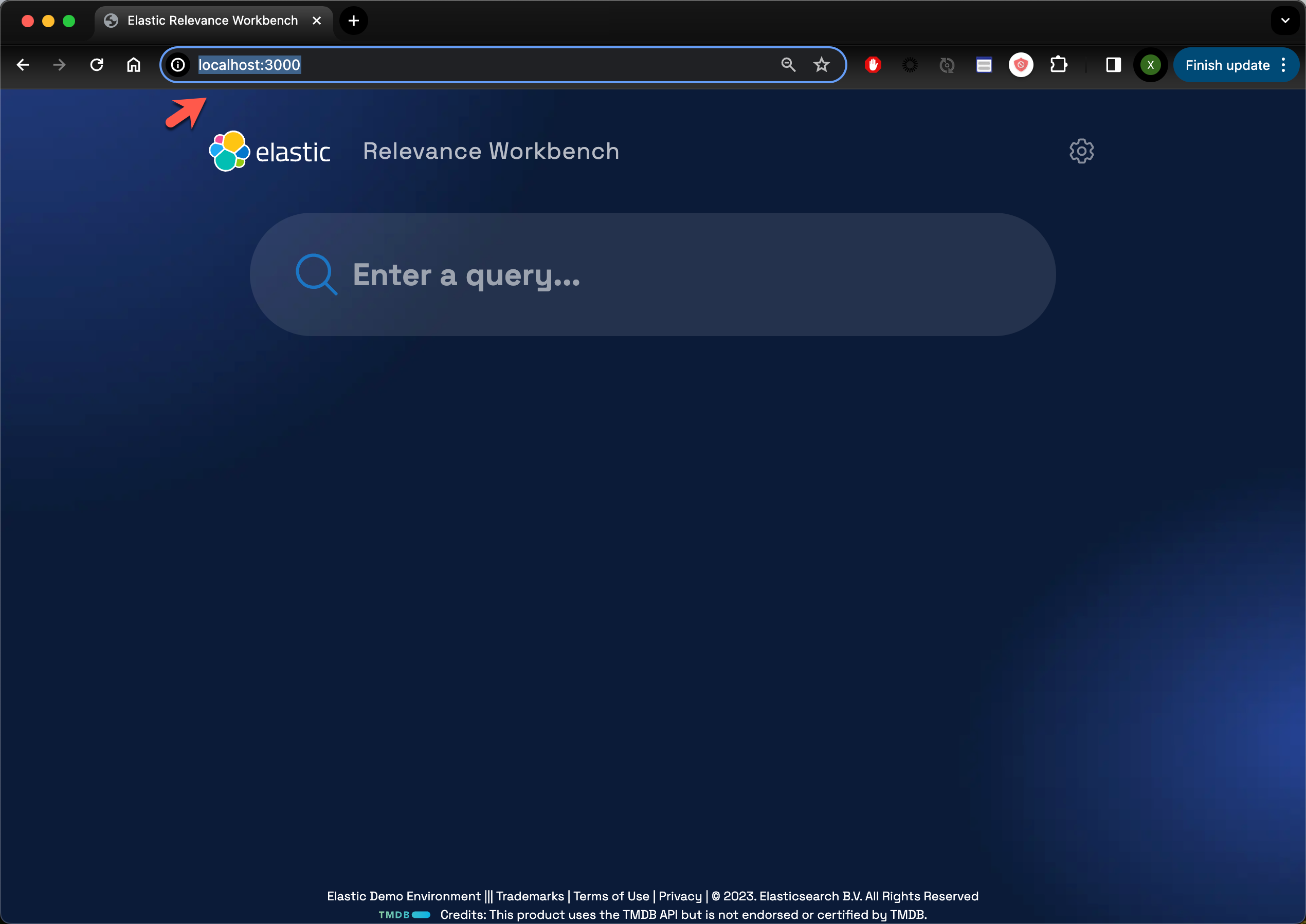
我们可以在浏览器中输入地址 localhost:3000:
一旦应用成功启动,我们可以看到有两个容器正在运行中。如果你只看到其中的一个,则表明你的运行是有问题的:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ffda44fa148b relevance-workbench-client "./entrypoint.sh yar…" 59 seconds ago Up 59 seconds 0.0.0.0:3000->3000/tcp relevance-workbench-client-1
6970577e8278 relevance-workbench-api "python3 -m flask ru…" 59 seconds ago Up 59 seconds 0.0.0.0:8000->8000/tcp relevance-workbench-api-1
$ 搜索一下
我们搜索一下 super hero:

我们再搜索一下 animated movies:
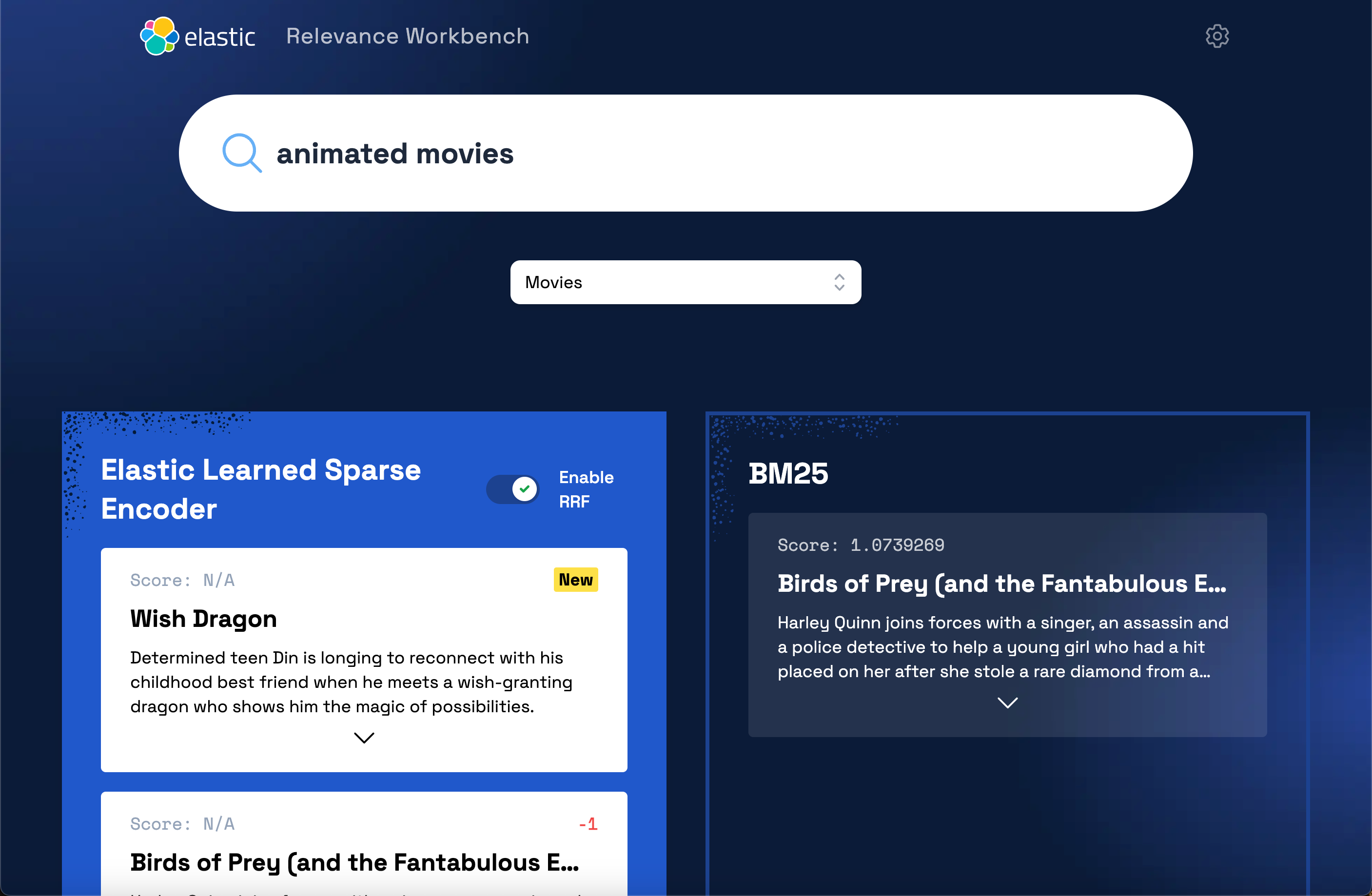
我们发现 ELSER 可以得到更加满意的语义搜索结果。