⭐️前言
2023年12月28-31日,第十九届中国图象图形学学会青年科学家会议在中国广州召开。本次会议由中国图象图形学学会主办,琶洲实验室、华南理工大学、中山大学、中国图象图形学学会青年工作委员会承办。王耀南院士、谭铁牛院士、中山大学赖剑煌教授、华南理工大学徐向民副校长、许勇副校长、琶洲实验室常务副主任李远清教授、北京大学林宙辰教授共同担任大会主席。
会议面向国际学术前沿与国家战略需求,聚焦最新前沿技术和热点领域,会议将设5个大会报告,27个主题分论坛,4个Tutorial,总计近200场高水平学术报告。本文将给大家分享由合合信息智能技术平台事业部副总经理丁凯博士带来的企业报告《文档图像大模型的思考与探索》。
⭐️文档图像大模型的思考与探索
众所周知,2023年最火的便是CHAT GPT为代表的大规模语言模型,同时以GPT-4V和谷歌Gemini为代表的多模态大模型也非常受关注,并且取得了非常惊艳的效果。从微软对GPT-4V做的测评报告中可以看出GPT-4V在文档识别、图表识别这个领域的效果非常棒,特别是在认知和理解这个层面上,但文档领域的核心问题依然存在,如图像质量问题、文字识别问题、版面分析问题等。
在研究层面上将文档图像分析识别领域分成了若干个研究主题,包括图像分析与预处理、文档解析与识别、图像安全、版面分析与还原等。当规模的语言模型、大规模的视觉模型出来以后,文档图像分析识别领域会发生什么样的变化呢?核心问题能否得到彻底解决?会给研发方式带来什么冲击?
为了搞清楚上述问题,我们先来看一看GPT4-V在IDP领域的表现。首先在场景文字识别领域,无论是多种场景还是多种语言形态,GPT4-V都可以取得较好的结果,与此同时,在手写识别这样的密集文档,以及几何图形和文字结合这种教育场景的文字识别和理解GPT4-V也可以取得较好的结果,对于这些教育场景,传统的文档处理方法需要多个模型进行缝合,而且必须针对特定的场景做定制,这种方法的泛化能力非常有限,从这个角度来看GPT4-V是非常惊艳的。其次在表格领域GPT4-V对表格的识别和理解也是非常不错的。最后一点,在信息抽取和文档理解领域,除了像常规的证件照这类简单的信息抽取以外,GPT4-V还可以针对各种比较复杂版式的文档图像以及文档图像和自然场景结合的信息进行抽取、理解和推理。
除此之外GPT4-V在对流程图、曲线图以及表格中的柱状图、线形图等进行识别和理解方面已表现出非常大的潜力。在这个领域传统的方法其实不多,并且这个领域的难度非常高,尤其是在泛化能力上传统方法和GPT4-V的差距是非常大的,所以GPT4-V在领域中的有些问题上远远领先于传统方法的水平。
虽然GPT4-V的能力非常惊艳,但GPT4-V依然不能把OCR领域的所有问题都解决。经过详细的分析发现,GPT4-V也存在着很多问题,比如中文,大家在用的时候会发现中文不管是手写体还是印刷体,GPT4-V识别出来会产生严重的幻觉,经常会输出一大段不存在的文字,并且对于手写公式的识别效果也不是特别好。为了更直观的看出GPT4-V在OCR和IDP领域的效果怎么样,金老师的团队发表了一篇文章量化的评估了一下GPT4-V和SOTA在OCR领域的对比。通过对比发现除了在手写英文识别接近之外,其他的场景如文字书别、多语言识别、手写公式识别等GPT4-V和SOTA的差距都非常大。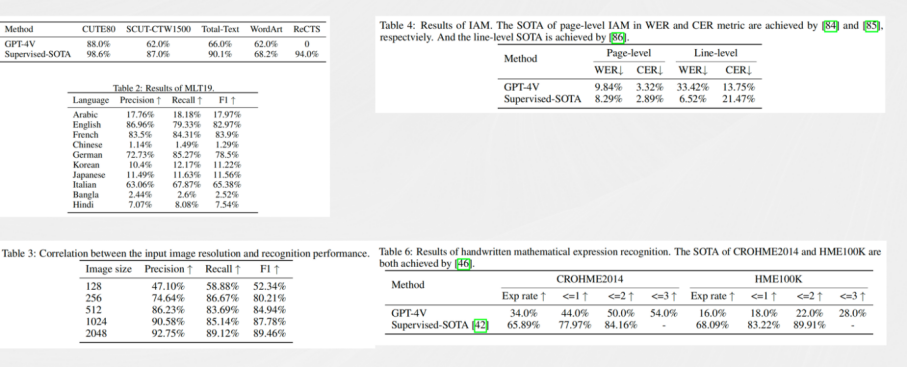
对以上问题进行分析可以看到GPT4-V的核心特点就是端到端的把文档领域的感知和认知问题解决了。传统方法是先做感知,再做认知,先做文档分析,再做NOP的理解。GPT4-V借助大规模语言模型在理解和认知的能力上非常强,它支持识别和理解文档元素,比如除了传统的文字表格、公式之外对流程图以及图表的识别能力也远远超过传统方法。当然GPT4-V也有不足的地方,比如它目前的精度距离SOTA还是有很大的差距。总体来说GPT4-V这种多模态的大模型其实就是提升了AI技术在IDP领域的能力边界,很多之前处理不好的问题,可以通过GPT4-V进行解决。
基于目前的现状,需要思考以下几个问题。
第一,GPT4-V这样动态大模型无法处理像素级的任务,比如OCR任务、篡改检测、文本分割、文本擦除等。传统的方法处理这些问题的时候,往往是一个任务一个模型。此时基于大模型的启发,可以思考能否在像素级的人物上面做一个统一的多任务模型,通过更大的数据和算力提升效果。
第二,GPT4-V大模型跟传统算法比,GPT4-V的优势是泛化能力强、支持文档种类高,它的劣势是精度不够。那么基于这个基础,可以思考能否将两者的优势相结合,既能提高识别的精度,又可以提升泛化能力。
第三、在长文档的场景里,大模型十分依赖于前置文档的识别与分析引擎。可以思考将该领域里的文档识别分析引擎和LLM更好的结合来解决一些问题。
基于上述三个思考,合合信息-华南理工大学文档图像分析识别与理解联合实验室针对以下任务进行了重点研究。
⭐️像素级OCR统一模型
首先分享像素级的OCR统一模型——UPOCR。它把文本擦除、文本分割和篡改文本检测者几个不同的像素级任务统一了任务的泛式架构和训练策略,并且通过引入科学系的任务提示来指导编码和解码结构,整个模型效果明显优于现有的专门模型。
UPOCR的主干网是ViTEraser,联合文本擦除、文本分割和篡改文本检测等3个不同的任务提示词进行统一训练,模型训练好后即可用于下游任务,无需针对下游任务进行专门的精调。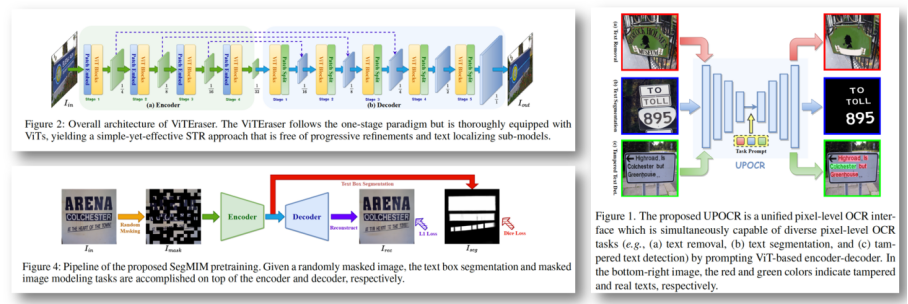
⭐️OCR大一统模型
其次是无需OCR的用于文档理解的Transformer模型,基于SPTS的OCR大一统模型(SPTS v3)将多种OCR任务定义为序列预测的形式。通过使用不同的prompt引导模型完成不同的OCR任务,可以极大地提高模型的泛化能力。例如,可以使用“where is the date on this document?”来询问文档中的日期位置,或者使用“what is the text on this image?”来识别图像中的文本。另外,SPTS v3沿用了SPTS的CNN + Transformer Encoder + Transformer Decoder的图片到序列的结构,这使得它可以更加高效地处理各种不同的OCR任务。
SPTSv3目前主要关注以下任务:端到端检测识别、表格结构识别、手写数学公式识别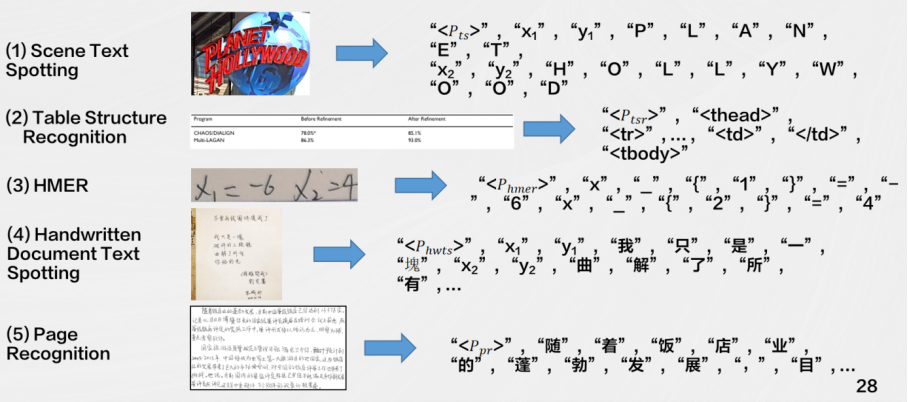
⭐️文档识别分析+LLM应用
最后就是文档识别分析在应用层面上的工作,传统的方案是将长文档进行切片,然后向量化、向量召回再进行问答。这个方案存在一个问题,文档本身是有逻辑、有结构的,无论是文档图像还是电子文档它的顺序结构和版面分析对结果的影响都非常大,基于这一点合合信息提出了一套技术框架。当一个文档图像输入进来之后,首先通过已有的文档识别与版面分析技术把图像里面的版面段落表格公式目录结构阅读顺序全部提取出来,拿到这些信息之后基于段落语义和目录结构的文档切分基于文档元素和语义结构的多层次召回策略(标题,表格,段落关系等),最后再LLM问答。
⭐️合合信息
合合信息是一家人工智能及大数据科技企业,基于自主研发的领先的智能文字识别及商业大数据核心技术,为全球C端用户和多元行业B端客户提供数字化、智能化的产品及服务。
公司C端业务主要为面向全球个人用户的APP产品,包括扫描全能王(智能扫描及文字识别APP)、名片全能王(智能名片及人脉管理APP)、启信宝(企业商业信息查询APP)3款核心产品;公司B端业务为面向企业客户提供以智能文字识别、商业大数据为核心的服务。
⭐️总结
GPT-4V给智能文档处理领域(IDP)带来了非常大的挑战和机遇,OCR和IDP领域也没有被GPT-4V给消灭,其中还是有非常多的工作值得我们去研究和探索。无论是OCR还是IDP它们和大模型不是互斥的,它们之间有着非常多的地方可以协作,可以让大模型做的更好,这里面也有很多工作是值得我们思考的。
⭐️抽奖福利

合合信息给大家送福利了!填写问卷抽10个人送50元京东卡,1月12日开奖噢~