本文旨在为不懂SQL的同学快速梳理SQL在干嘛,以及入门SQL。
一、SQL是什么
SQL(Structured Query Language:结构化查询语言)是用于关系型数据库的数据管理所用的一种语言,在数据分析与数据挖掘领域有着广泛的应用。别看SQL貌似是一门编程语言,但这项技能是互联网公司数据分析岗位的必备技能,早已经成为统计学、管理学、数学、市场营销等专业同学的通用技能。
SQL当年能火,就是因为足够简单,到底有多简单呢,我们下面来看看。
本文的例子可以直接在这个在线平台使用(SQL Fiddle)。
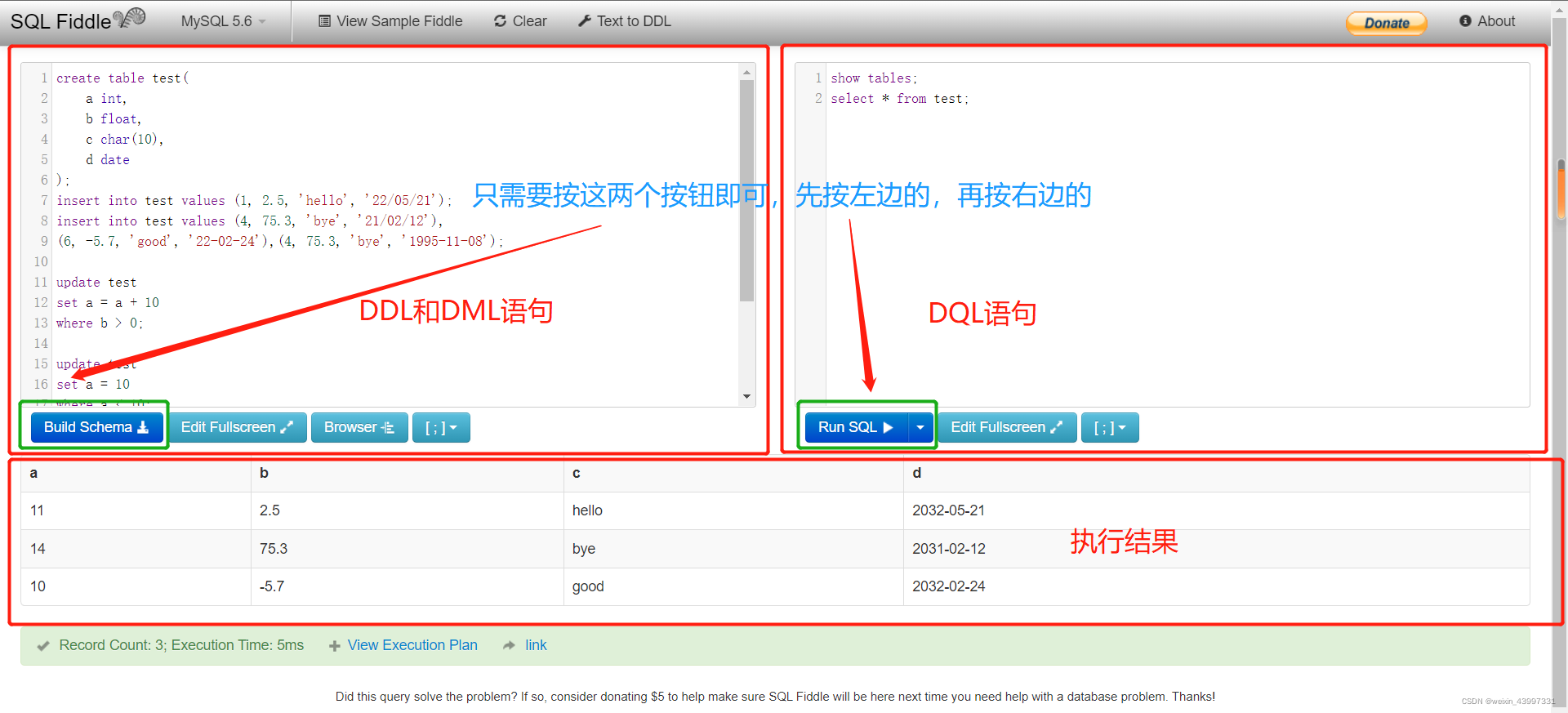
二、开始入门
SQL语言不区分大小写,关键字之间以空格分割,对换行和缩进均不敏感,一个语句结束的标志是分号。
首先定义一下最基本的术语,方便下面的交流:
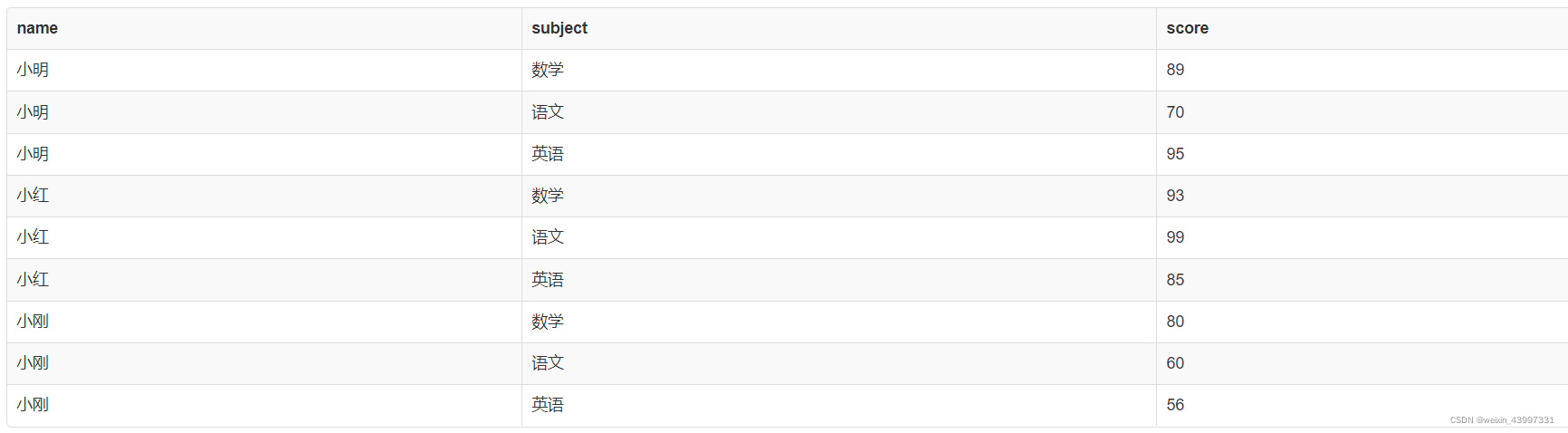
关系: 一个关系对应通常说的一张表,如上图这张表。
元组: 表中的一行即为一个元组。
属性: 表中的一列即为一个属性。
关系模式: 对应关系的描述,一般表示为 关系名(属性1、属性2),如上的关系可以描述为:成绩单(姓名、课程、成绩)
1. DDL语句(create,alter,drop)
这个很好记,全程是Data Defination Language,即数据定义语句。具体来说,就是定义数据要按照什么样的格式去存储。通俗理解,就是定义一张表的表头有哪几列,每一列叫什么名字,每一列是什么数据类型。
举个例子:
create table test(
a int,
b float,
c char(10),
d date
);
可以看到,要创建一张表,我们需要
- 首先输入create table + 表名,
- 然后输入一个括号,
- 再输入括号中每个属性的名称和类型,以逗号分割。注意与C语言不同,名称在前类型在后,
- 结尾以分号结束。
SQL所支持的数据类型网上很好查到,我这里列举了最基本的几种,包括int(integer)、float、char、date。char表示字符串,括号中表示字符串的长度,数据库不能存储超过定义时长度的字符串。varchar表示可变长度字符串,用法和char一样,但更省空间。
DDL语句中的alter是修改已经定义的表,这个暂时不讲,我们讲一下drop怎么用。
drop table test;
就这么简单,drop table + 要删除的表,就可以删掉之前定义过的一个表了。
2. DML语句(insert,update,delete)
这个的全程是Data Manipulation Language,即数据操纵语言,读者可以把dml用输入法打在输入框里,看看排在第一位的词是什么,方便记忆。我打上去发现是“都没了”。
简单来说,DML语句的作用是对数据进行增、删、改。刚刚的DDL语句把表定义好了,这次总得放点数据吧。
我们可以用INSERT语句来插入数据,语法如下:
insert into 表名称 values (一行具体值1), (一行具体值2), (一行具体值3)……;
# 一次只插入一行值
insert into test values (1, 2.5, 'hello', '22/05/21');
# 同时插入多行值
insert into test values (4, 75.3, 'bye', '21/02/12'),
(6, -5.7, 'good', '22-02-24'),(4, 75.3, 'bye', '1995-11-08');
对于字符串,单引号和双引号没有区别,对于日期,要当做字符串来输入,遵循年月日的顺序,分隔符比较自由,甚至可以省略年份的前两位数字,由数据库来补齐。
在执行完上面的语句之后,表格长这样。

接下来说改,用UPDATE语句来实现某些值的修改。语法规则为:
UPDATE table_name
SET column1=value1,column2=value2,...
WHERE some_column=some_value;
举个例子,我想让b列大于0的行中的a列的值都加10。
用SQL语句写出来是这样:
update test
set a = a + 10
where b > 0;
这个语句可以倒过来看,where后面跟的是筛选行的条件。首先找到b > 0的行,然后把这些行中的a设置为a+10。执行完之后,表格长这样:

where中涉及的列也可以于set中的列相同,这个是不冲突的。
我们想让现在a < 10的行中的a都等于10,语句应该这样写:
update test
set a = 10
where a < 10;
执行完之后的结果如下表。

理解update之后,delete就好理解了,删除满足where条件的行。比如,删除日期小于2000年1月1日的行。
delete from test
where d < '2000-01-01';
可以看一下执行之后的结果,感觉怎么样,是否有一种操纵数据的感觉了?

对于update和delete,如果没有where也是可以的,那这样就是对所有行进行操作了,比如:我们需要让每一行的d都加10年。
update test
set d = d + '00100000';
结果如下:

3. DQL语句(select,where,distinct,or,and)
这个是Data Query Language的缩写,即数据查询语言。这里的Q和和SQL的Q是同一个词,由此可见DQL在SQL中的核心地位。
本文先讲在单表上的查询,读者需要记住两个东西:选择和投影。
(1)选择
一个表存储的数据有很多行,选择即为筛选符合条件的行。在SQL语言中,条件要写在where之后,这一点在上面的update和delete中已经简要提过。可以联想一下excel的筛选功能,就对这个功能有更直观的理解了。
(2)投影
一个表有很多列,投影操作就是选取其中的几列作为结果返回。
(3)选择+投影
如果既有选择,又有投影,就可以从行和列两个维度去查询数据了。
(4)去重distinct
如果返回的结果中有两行一模一样,可以用distinct消除重复值。
查询语句用SELECT语句,下面展示一下基本的select语句的结构。
select * from table_name where 条件; #星号表示选取所有列
select 选取的列 from table_name where 条件;
(1)全表查询举例,返回所有数据
select * from test;

(2)只选择
select * from test where b > 0;

多个条件可以用and表示∩的关系。
select * from test where b > 0 and a < 12;

多个条件可以用or表示∪的关系。
select * from test where b > 0 or a < 12;

(3)只投影
select a,b,c from test;

列的顺序可以调换
select d, b, a, c from test;

列还可以用as来取一个别名,表也可以用as取一个别名。
select d as date, b as float_number, c from test;

(4)选择+投影
大家对于选择和投影应该都明白了,所以这里只举一个例子
select d as date_value,
b as float_number,
c as string_value
from test
where b > 0 and c < 'dad';

(5)有时候查询返回的结果可能会有重复值,我们可以用distinct来消除重复
例如下面这个表及数据:
create table test(
a int,
b int);
insert into test values (1,3),(2,2),(2,1);
select a from test;
结果为

如果在select和列名之间加distinct,返回的结果就会消除重复。
select distinct a from test;

三、略微进阶
1. 使用SQL内置函数(aggregate function、scalar function)
SQL中的函数分为两种:
(1)非聚合函数(scalar function)
输入数据的行数与返回数据的行数相等,也就是说输入与结果一一对应
(2)聚合函数(aggregate function)
输入的值为多行数据,返回一行数据
各列举一个例子:
select concat('ruc:', c) from test; #非聚合函数
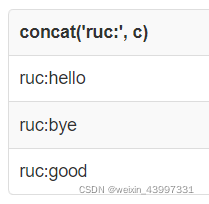
select group_concat(c) from test; #聚合函数

常见的非聚合函数有:UCASE(字符串转为大写)、LCASE(字符串转为小写)、MID(c,start[,end]) (截取字符串的一部分,start从1开始)、isnull/ifnull(在不同的数据库中名称不同,用来判断一个值是否为null)等。
聚合函数使用更多,常见的聚合函数有:COUNT(统计行数)、MIN(返回一组值中的最小值)、MAX(返回一组值中的最大值)、AVG(返回一组值中的平均值)等等。
2. 排序(order by)
excel中是有排序功能的,作为比excel强大得多的数据管理工具,SQL怎么可能没有排序功能呢?
排序的关键字是ORDER BY,后面可以加列名,列名之后还可以加DESC
表示降序,ASC表示升序,默认是升序。如果ORDER BY后面加多个列,则表示按从左到右的要求进行排序。
例如下面这个表及数据:
create table test(
a int,
b int);
insert into test values
(2,3),(2,2),(2,1),
(1,2),(1,3),(1,4),(1,5),
(3,4),(3,2),(3,5);
查询语句如下所示,先按b降序排列,再按a升序排列:
select * from test order by b desc, a asc;

3. 分组(group by,having)
分组要搭配聚合函数一起使用,还是上面的表和数据,给大家举个例子:
我们希望得到按a的值分组时,b的平均值,需要用到关键字GROUP BY,加在最后。SQL语句如下:
select a, avg(b) from test group by a;

来分析一下avg(b)是如何得到的。当a=1时,一共有4行,b分别为2、3、4、5,平均值为3.5。当a=2时,一共有3行,b分别为3、2、1,平均值为2。当a=3时,一共有3行,b分别为2、4、5,平均值为3.6667。
再举一个比较形象的例子,有如下成绩单:
create table ScoreTable(
name char(20),
subject char(20),
score float
);
insert into ScoreTable values
('小明', '数学', 89),
('小明', '语文', 70),
('小明', '英语', 95),
('小红', '数学', 93),
('小红', '语文', 99),
('小红', '英语', 85),
('小刚', '数学', 80),
('小刚', '语文', 60),
('小刚', '英语', 56);
如果要统计各个科目的平均分,SQL语句如下:
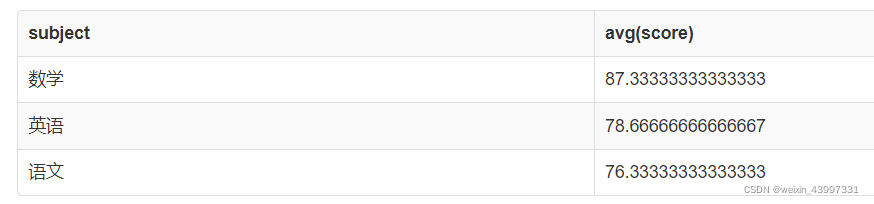
如果要统计学生的平均成绩,SQL语句如下:
select name, avg(score) from ScoreTable
group by name;

如果还要成绩从高到低排列,则再最后加上ORDER BY即可
select name, avg(score) from ScoreTable
group by name
order by score desc;
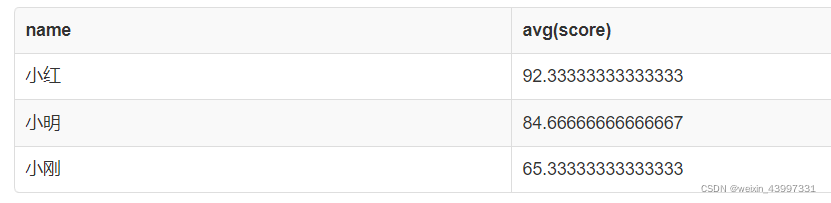
如果,我们只想得到平均成绩在80分以上的学生,该怎么办呢?这里要介绍一个新的语法:having。
having的作用也是筛选,但其筛选的条件是含有聚合函数的条件,看下面这个例子:
select name, avg(score) from ScoreTable
group by name having avg(score) > 80
order by score desc;

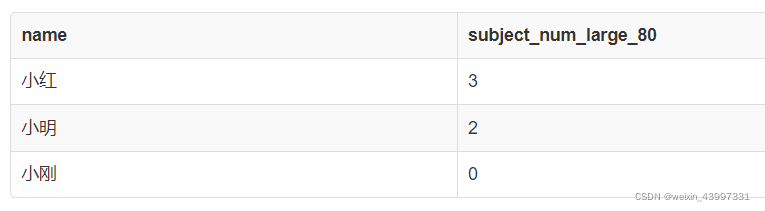
这时,我们想要找到,每个学生大于80分的课程门数且按降序排列,SQL语句如下,如果我上面的都讲明白了,大家应该能明白这个语句什么意思:
select name, count(score) as subject_num_large_80
from ScoreTable where score > 80
group by name order by subject_num_large_80 desc;
结果是如下所示,发现好像少了一个人:

究其原因,是小刚成绩太差,没有80分以上的课程,所以在where子句选择结束之后就不含有小刚的成绩了。但这显然不是我们期望的,我们期望的是显示小刚且80分以上的课为0门,如下图所示。
要解决这个问题,还需要学习下面更多的知识,读者们也可以先思考一下有无简单的办法。
4. where条件的比较语法(between,in,like)
SQL中直接支持的符号有:>, <, >=, <=, =, <>,分别表示大于、小于、大于等于、小于等于、等于、不等于。
此外,还有一些关键字也是用于比较的条件的。这几个关键词都很好理解:
- between:在两个值中间,用法用下面的来举个例子
查找小明成绩位于80到90之间的课程
select subject from ScoreTable
where name = "小明" and score between 80 and 90;

- in:一个值在一个范围之内。in的右边可以是一个元组或者一个查询的结果
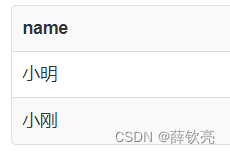
查询有课程成绩正好等于60,70,80,90,100的同学名字
select distinct name from ScoreTable
where score in (60,70,80,90,100);
- like:用来查找符合一定要求的字符串,需要借助通配符%,意思是匹配任意多的任意字符。我们可以在%前后加上我们所限定的字母来进行模式匹配。
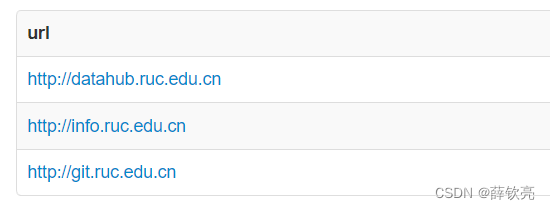
下面举个例子来说明,有这样一个表,包含了很多url链接。
create table Web(
url char(50)
);
insert into Web values
('http://datahub.ruc.edu.cn'),
('http://info.ruc.edu.cn'),
('http://www.baidu.com'),
('http://git.ruc.edu.cn'),
('http://www.pku.edu.cn');
我们要找出所有是人大域名下的链接,即以“ruc.edu.cn”结尾的链接。下面的查询可以实现这样的功能:
select url from Web
where url like "http%ruc.edu.cn";
四、嵌套查询
嵌套查询大体分为相关嵌套查询和不相关嵌套查询。嵌套查询有以下规则:
1、子查询的select查询总是使用圆括号括起来。
2、任何可以使用表达式的地方都可以使用子查询,只要它返回的是单个值。
3、子查询最多可以嵌套到32层。个别查询可能会不支持32层嵌套。
4、如果某个表只出现在子查询中而不出现在外部查询中,那么该表的列就无法包含在输出中。
1. 不相关嵌套查询
父查询就是SQL语句的主体,子查询就是其返回的结果作为一部分嵌入在父查询之中。不相关嵌套查询就是子查询的结果可以与父查询的结果很容易地分开处理,看下面这个例子。
我们依然用上面的这个成绩的例子。
create table ScoreTable(
name char(20),
subject char(20),
score float
);
insert into ScoreTable values
('小明', '数学', 89),
('小明', '语文', 70),
('小明', '英语', 95),
('小红', '数学', 93),
('小红', '语文', 99),
('小红', '英语', 85),
('小刚', '数学', 80),
('小刚', '语文', 60),
('小刚', '英语', 56);
找出数学成绩比小明的数学成绩高的同学的名字,SQL语句如下:
select name from ScoreTable
where subject = '数学'
and score > (
select score from ScoreTable
where name = '小明' and subject = '数学');
score大于的那个部分就是子查询,而子查询如果没有父查询,也可以单独执行,所以,这个嵌套查询,属于不相关嵌套查询。
2. 相关嵌套查询
反之,子查询无法单独执行,与父查询有依赖关系的查询,就叫相关嵌套查询。这种嵌套查询更加复杂,有时候难以理解,下面举出一个场景来帮助大家理解什么叫做相关嵌套查询。
假如我们需要做这样一个查询,查询每个学生超过他自己所学课程平均成绩的课程名。先考虑子查询,查找一个学生所学课程平均成绩非常简单,SQL语句如下,xxx为任意一名同学的名字:
select avg(score) from ScoreTable where name = 'xxx';
再考虑父查询,大体结构应该是这样:
select name, subject from ScoreTable where score > (子查询);
我们发现,子查询中的xxx,其实就是外层父查询的name,因此,合起来可以初步写为:
select name, subject from ScoreTable
where score >
(select avg(score) from ScoreTable
where name = name);
但这样写明显有问题,因为name=name这个条件是无效的,在括号内,所有的name都会认为是属于子查询中的表。这里,我们给父查询和子查询的表用as起一个别名以示区分,最终写成:
select name, subject from ScoreTable as x
where score >
(select avg(score) from ScoreTable as y
where y.name = x.name);
上面这个语句之所以能执行,可以类比其他编程语言中的双重for循环来理解。SQL语句是先执行父查询,再执行子查询,并且父查询中已经查找到的值,可以在当前的子查询中使用。讲到这里,读者应该可以理解为什么上一个例子是不相关嵌套查询了,因为我们限定了子查询的name必须是小明,这样就和父查询不相关了。
3. 小练习
讲到这里,上面留下的问题已经可以解答了:
查询每个学生大于80分的课程门数且按降序排列,答案依旧留给读者去思考,如果要查询正确答案,可以关注公众号,发送sql。

五、多表连接(join)
1. 关系代数基础
学习多表连接,需要稍微了解一点关系代数的基础了。不要害怕,关系代数和大家学的高等代数关系不大。关系代数是一种抽象的数据查询语言,用对关系的运算来表达查询,其输入和输出都是关系(还记得关系吗?关系就是一张表)
我们把一个表中的每一行当做一个元素,那么每一张表,其实就是一个可重复集合( m u l t i s e t multiset multiset),每一行就是可重复集合的一个元素。
1.1 传统的集合运算
由此,引申出四个传统的集合操作,下面是R和S都是一个关系:
- 并 ( ∪ ) (\cup) (∪): R ∪ S = { t ∣ t ∈ R ∨ t ∈ S } R \cup S= \left\{ t \big| t \in R \vee t \in S \right\} R∪S={ t∣∣t∈R∨t∈S}
sql1 union sql2; #会合并重复的行
sql1 union all sql2; #会展示所有重复的行
- 交 ( ∩ ) (\cap) (∩): R ∩ S = { t ∣ t ∈ R ∧ t ∈ S } R \cap S= \left\{ t \big| t \in R \wedge t \in S \right\} R∩S={ t∣∣t∈R∧t∈S}目前SQL标准没有对交的实现方法做定义,各个数据库软件有不同的实现方式,比如mysql通过join来实现交(下面会讲)。
- 差 ( − ) (-) (−): R − S = { t ∣ t ∈ R ∧ t ∉ S } R - S= \left\{ t \big| t \in R \wedge t \notin S \right\} R−S={ t∣∣t∈R∧t∈/S}目前部分数据库支持关键字except,但更标准的一般用not in来表示“不在”,作为筛选的条件出现。
select * from table1 where name
not in (select name from table2);
- 笛卡尔积 ( × ) (×) (×): R × S = { ( t r , t s ) ∣ t r ∈ R ∧ t s ∈ S } R × S= \left\{ (t_r,t_s) \big| t_r \in R \wedge t_s \in S \right\} R×S={
(tr,ts)∣∣tr∈R∧ts∈S}
笛卡尔积直观理解,就是两个集合元素组成的有序对,第一个元素来自第一个集合中,第二个元素来自第二个集合中,这个在离散数学中叫做序偶。
笛卡尔积在SQL语句中表示非常简单,如果要求两个表的笛卡尔积,写如下表达式即可,如果需要加选择条件,可以正常在后面加入where等语句:
select * from R, S;
select * from R join S;
多个表进行笛卡尔积操作,可以写多个表,但笛卡尔积的大小是所有表大小的乘积,计算非常耗时间耗空间。
select * from R, S, T, ..., Z, ...;
1.2 专门的关系运算
在上面讲解DQL语句的过程中,讲到了两个操作:选择,投影,这也是关系代数中的运算。此外,还有连接、除两个运算。除法运算比较抽象,这里不讲了。
选择 ( σ ) (\sigma) (σ):其中F表示条件,F(t)是一个逻辑表达式,有真或假两种取值。 σ F ( R ) = { t ∣ t ∈ R ∧ F ( t ) = T r u e } \sigma_F(R) = \left\{ t \big| t \in R \wedge F(t)=True\right\} σF(R)={
t∣∣t∈R∧F(t)=True}
投影 ( Π ) (\Pi) (Π):R是一个关系,包含了A在内的多个属性,投影简单理解就是选取R中的几个属性组成一个新的关系。
Π A ( R ) = { t [ A ] ∣ t ∈ R } \Pi_A(R)= \left\{ t[A] \big| t \in R \right\} ΠA(R)={
t[A]∣∣t∈R}
连接 ( ⋈ ) (\Join) (⋈),也称为 θ \theta θ 连接( ⋈ θ \Join_{\theta} ⋈θ):这是一种以笛卡尔积为基础的运算,是在笛卡尔积的运算结果中,选取属性间满足一定条件的元组形成一个新的连接。
如果 θ \theta θ是等于条件,则这个连接被称为等值连接。
自然连接是一种特殊的等值连接,比较两个关系中相同的属性组成一个属性组,最后只保留属性组中分量完全相同的元组,然后在连接的结果中把重复的属性去掉,相当于在笛卡尔积上既做行运算又做列运算。
左连接:在自然连接的基础上加上左边表上不包含自然连接中所含元组(行)的元组。
右连接:在自然连接的基础上加上右边表上不包含自然连接中所含元组(行)的元组。
外连接:左连接+右连接
2. 例子1(等值连接,自然连接,左连接,右连接)
相信读者现在一定很懵,我们结合具体数据来看一下,大家就明白了。
create table College(
cid int,
cname varchar(20)
);
create table Student(
sid int,
cid int,
sname varchar(20)
);
insert into College values
(0, '信息学院'),(1, '数学学院'),
(2, '统计学院'),(3, '交叉科学学院');
insert into Student values
(1000, 0, '小明'),(1001, 0, '小红'),(1002, 0, '小刚'),
(1003, 1, '小李'),(1004, 1, '小张'),(1005, 1, '小赵'),
(1006, 2, '小王'),(1007, 2, '小白'),(1008, 2, '小黑'),
(1009, -1, '野鸡'),(1009, -1, '野鸭');
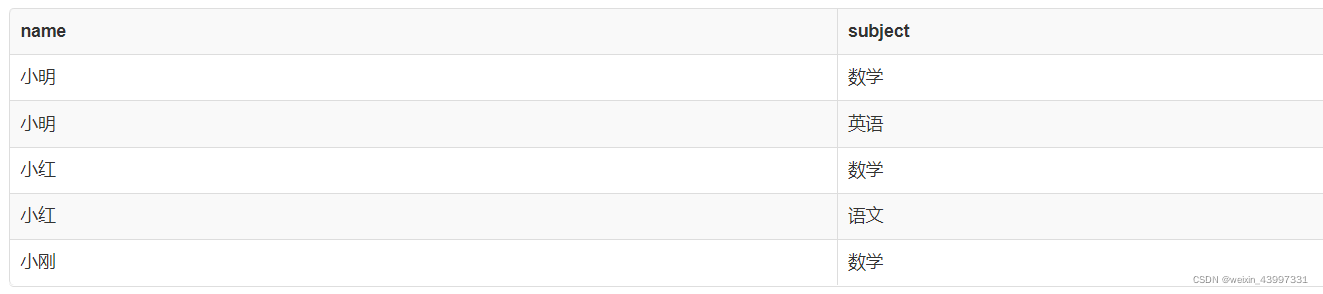
这里有两个表,一个学院表,一个学生表,但有的学院没有学生,有的“学生”的学院其实不存在。这两个表之间的联系在于,都用cid表示了学院编号,因此可以用连接操作将这两个表连接起来。这里显然需要用自然连接。下面两种写法输出的结果是一样的。
select * from College natural join Student;
select * from College join Student using(cid);
结果如下,发现自然而然地就按照cid把两个表的信息对应起来了,且去除了重复的cid列。
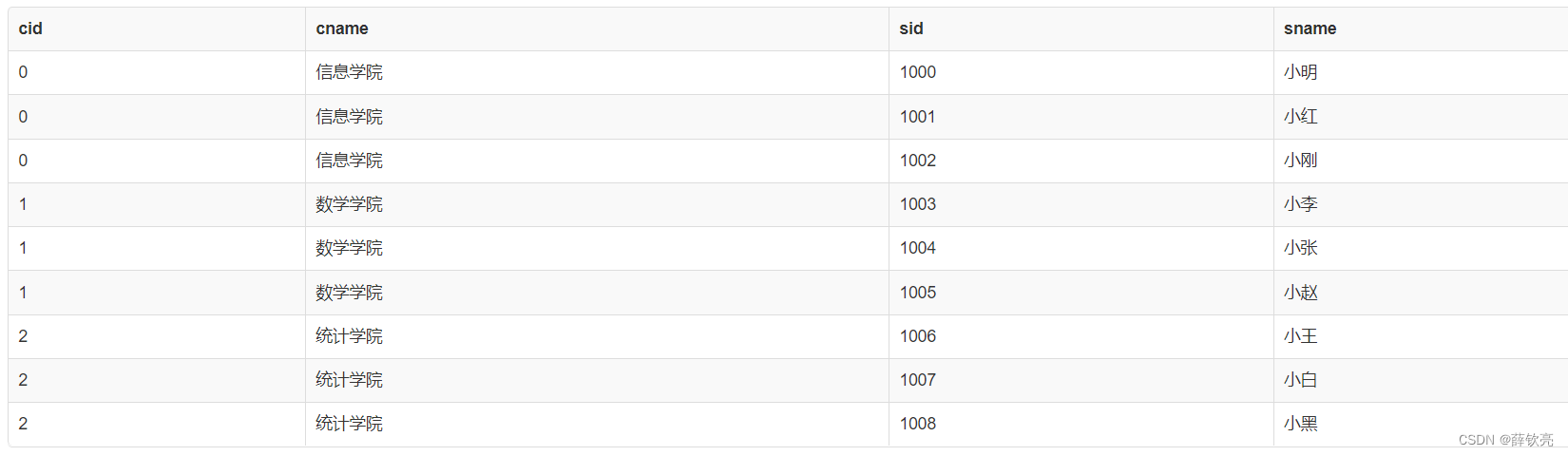
如果是用on后面接连接的条件,就会发现变成普通的等值连接了,因为重复出现了cid。这里可以看到on和where都可以加条件,on后面所跟的条件仅作用于两表连接产生临时表的过程,而where是在连接完成生成临时表之后进行条件筛选。如果用好on,可以在连接过程筛掉大部分不符合要求的元组,这样效率更高。
select * from College join Student
on College.cid = Student.cid;
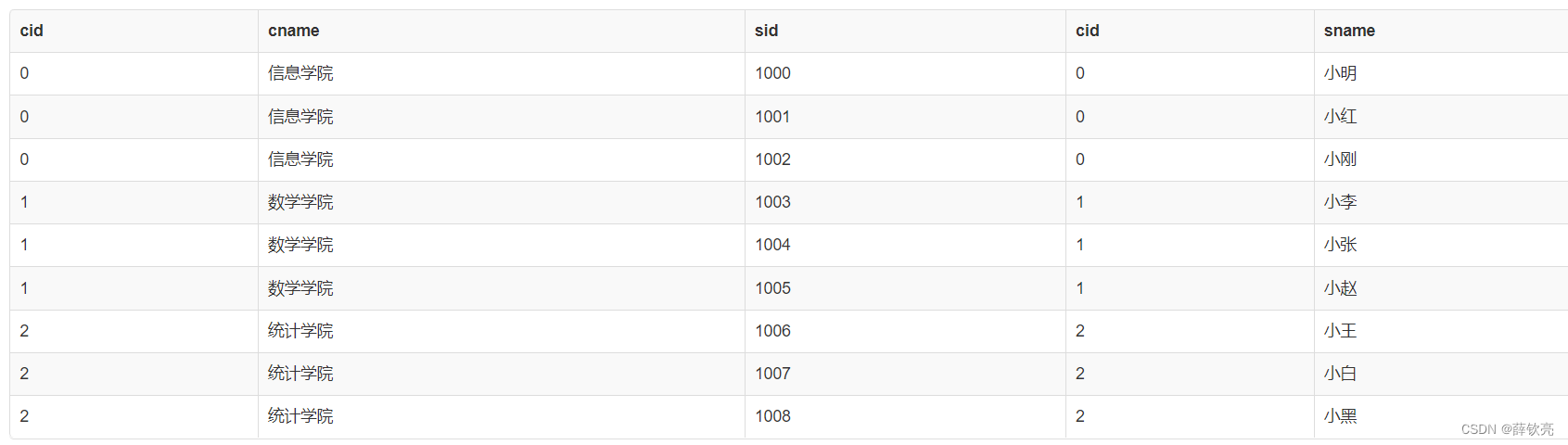
我们再试一下左连接和右连接,会发现多了一些东西:
select * from College left join Student using(cid);
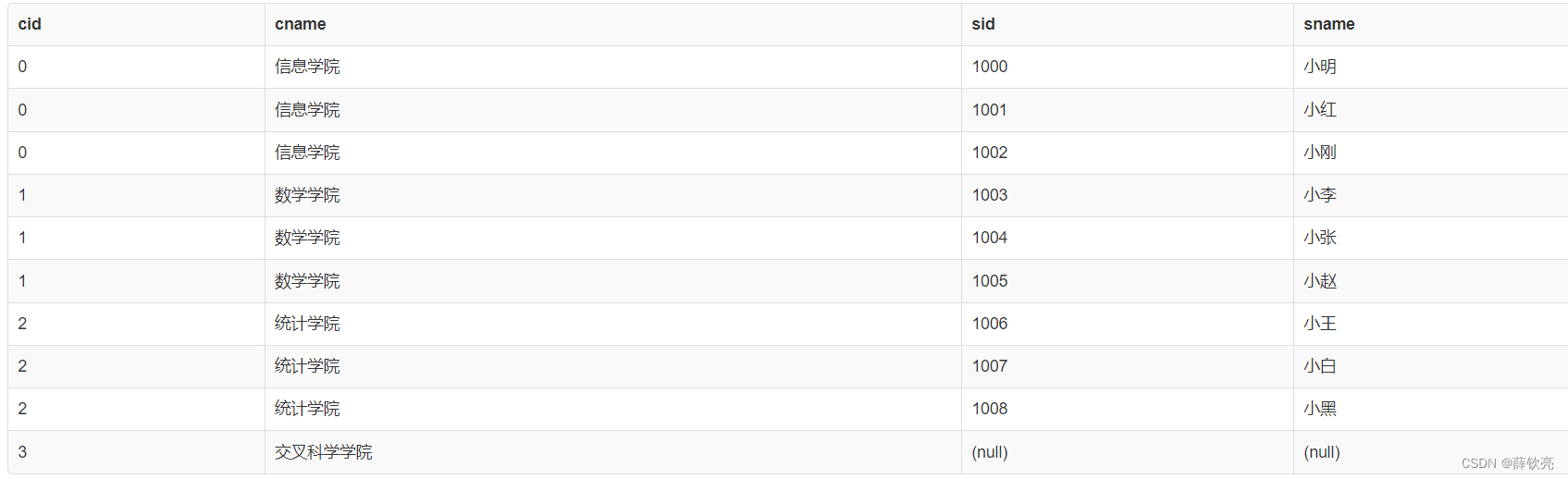
select * from College right join Student using(cid);
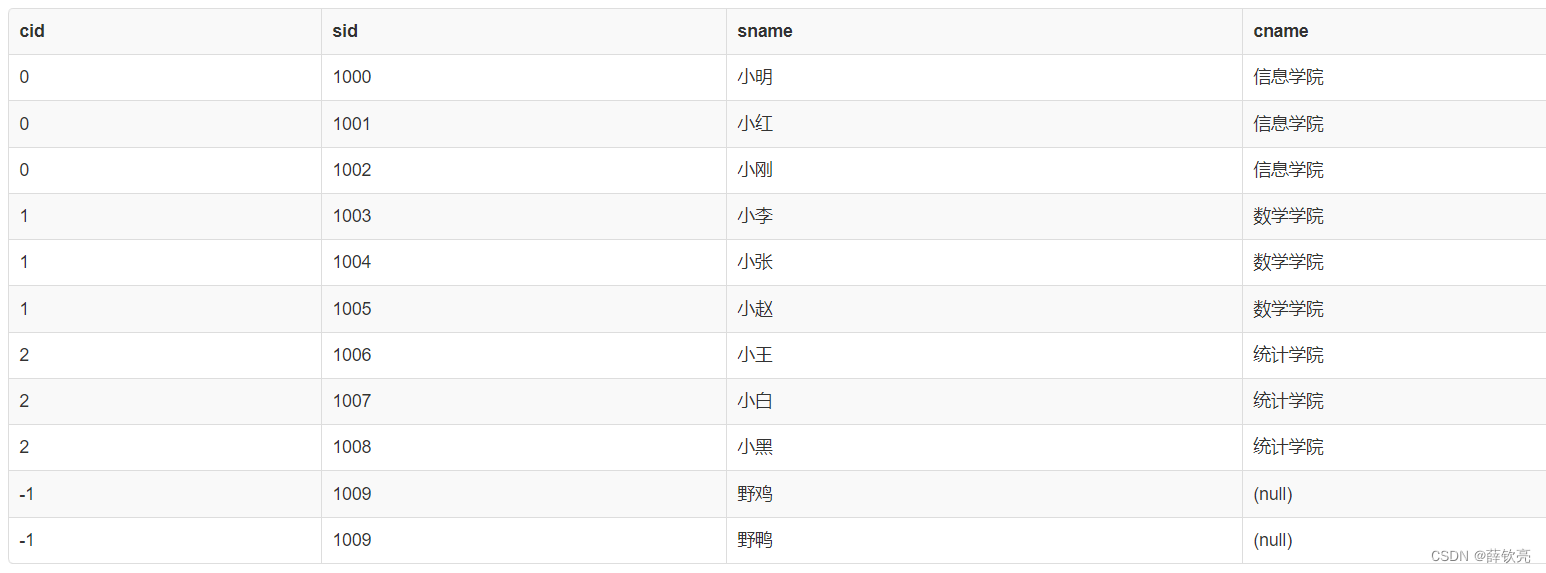
3. 例子2(自连接,嵌套查询+等值连接)
实际上,除了两表相连以外,自己与自己也可以做连接。这里不得不再次搬出上面成绩单的例子来说明:
create table ScoreTable(
name char(20),
subject char(20),
score float
);
insert into ScoreTable values
('小明', '数学', 89),
('小明', '语文', 70),
('小明', '英语', 95),
('小红', '数学', 93),
('小红', '语文', 99),
('小红', '英语', 85),
('小刚', '数学', 80),
('小刚', '语文', 60),
('小刚', '英语', 56);
如果我们要查询:数学成绩高于语文成绩的同学的名字及他们的数学和语文成绩,那连接语句可以这样写:
#投影
select S1.name as 姓名, S1.score as 数学成绩, S2.score as 语文成绩
#连接
from ScoreTable as S1 join ScoreTable as S2
on S1.name = S2.name
#选择
where S1.subject = '数学' and S2.subject = '语文'
and S1.score > S2.score;

这种自连接不可以用natural join,因为natural join会去除重复列,但自连接正是需要重复列。
为了区分name到底是哪个表的name,这种有歧义的属性需要用表名加点再加属性名来区分。
再举一个例子,我们可以用连接操作去给出之前一个问题的另一种解法:
查询每个学生超过他自己所学课程平均成绩的课程。
select x.name, x.subject from ScoreTable as x
join
# 子查询可以构成一个临时表
(select name, avg(score) as avg_score
from ScoreTable group by name) as y
on x.name = y.name
where x.score > y.avg_score;
这种解法相较于之前的方法效率更高,因为这里只一次查询就得到了所有的平均值,并且生成了一个临时表。而之前的语句,则对每一个人都要进行一次查询才能得到他们的平均值用于比较。
4. 小练习
考研录取常见场景:查找总分大于250分、且没有单科低于60的同学的名字和总分。
如果要查询正确答案,可以关注公众号,发送sql2。
(未完待续)
顺便宣传一波自己的个人公众号,会同步更新数据库科普专栏,以及个人作为党员的一些所思所想。