整理自炼数成金
源码连接:
1 . 线程池的基本使用1.1. 为什么需要线程池
假设一个服务器完成一项任务所需时间为:T1 创建线程时间,T2 在线程中执行任务的时间,T3 销毁线程时间。
如果:T1 + T3 远大于 T2,则可以采用线程池,以提高服务器性能。
1.1.1. 假设一个服务器完成一项任务所需时间为:T1 创建线程时间,T2 在线程中执行任务的时间,T3 销毁线程时间, T1 + T3 远大于 T2。
采用线程池减少了创建和销毁线程的次数,每个工作线程都可以被重复利用,可执行多个任务。
1.1.2.可以根据系统的承受能力,调整线程池中工作线线程的数目,防止因为消耗过多的内存,而把服务器累趴下(每个线程需要大约1MB内存,线程开的越多,消耗的内存也就越大,最后死机).
1.2.JDK为我们提供了哪些支持
1.2.1. 内置线程池
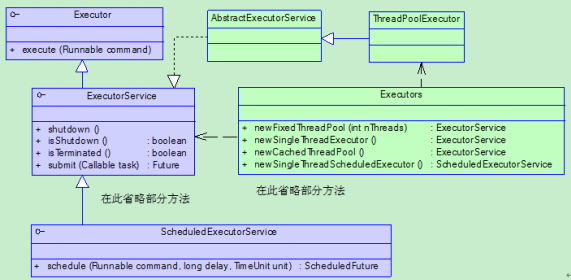
1.3.线程池的使用
1.3.1. 线程池的种类
newFixedThreadPool
创建固定大小的线程池。每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小。线程池的大小一旦达到最大值就会保持不变,如果某个线程因为执行异常而结束,那么线程池会补充一个新线程。
newSingleThreadExecutor
创建一个单线程的线程池。这个线程池只有一个线程在工作,也就是相当于单线程串行执行所有任务。如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它。此线程池保证所有任务的执行顺序按照任务的提交顺序执行。
newCachedThreadPool
创建一个可缓存的线程池。如果线程池的大小超过了处理任务所需要的线程,那么就会回收部分空闲(60秒不执行任务)的线程,当任务数增加时,此线程池又可以智能的添加新线程来处理任务。此线程池不会对线程池大小做限制,线程池大小完全依赖于操作系统(或者说JVM)能够创建的最大线程大小。
newScheduledThreadPool
创建一个大小无限的线程池。此线程池支持定时以及周期性执行任务的需求。
1.3.2. 不同线程池的共同性
在下面线程池及其核心代码分析一节中会有所体现。
1.4. 线程池使用的小例子
1.4.1. 简单线程池
- public class fixedThreadExecutorTest{
- public static void main(String[] args) {
- // TODO Auto-generated method stub
- //创建一个可重用固定线程数的线程池
- ExecutorService pool=Executors.newFixedThreadPool(2);
- //创建实现了Runnable接口对象,Thread对象当然也实现了Runnable接口;
- Thread t1=new TestThread();
- Thread t2=new TestThread();
- Thread t3=new TestThread();
- Thread t4=new TestThread();
- //将线程放到池中执行;
- pool.execute(t1);
- pool.execute(t2);
- pool.execute(t3);
- pool.execute(t4);
- }
- }
3.4.2. ScheduledThreadPool
- public class scheduledThreadExecutorTest{
- public static void main(String[] args) {
- // TODO Auto-generated method stub
- ScheduledThreadPoolExecutor exec =new ScheduledThreadPoolExecutor(1);
- exec.scheduleAtFixedRate(new Runnable(){//每隔一段时间就触发异常
- @Override
- public void run() {
- // TODO Auto-generated method stub
- //throw new RuntimeException();
- System.out.println("===================");
- }}, 1000, 5000, TimeUnit.MILLISECONDS);
- exec.scheduleAtFixedRate(new Runnable(){//每隔一段时间打印系统时间,证明两者是互不影响的
- @Override
- public void run() {
- // TODO Auto-generated method stub
- System.out.println(System.nanoTime());
- }}, 1000, 2000, TimeUnit.MILLISECONDS);
- }
- }
1.5. 线程池及其核心代码分析
ThreadPoolExecutor的完整构造方法的签名是:
ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) .
corePoolSize - 池中所保存的线程数,包括空闲线程。
maximumPoolSize-池中允许的最大线程数。
keepAliveTime - 当线程数大于核心时,此为终止前多余的空闲线程等待新任务的最长时间。
unit - keepAliveTime 参数的时间单位。
workQueue - 执行前用于保持任务的队列。此队列仅保持由 execute方法提交的 Runnable任务。
threadFactory - 执行程序创建新线程时使用的工厂。
handler - 由于超出线程范围和队列容量而使执行被阻塞时所使用的处理程序。
BlockingQueue的三种类型:
直接提交策略,也即SynchronousQueue。
它将任务直接提交给线程而不保持它们。在此,如果不存在可用于立即运行任务的线程,则试图把任务加入队列将失败,因此会构造一个新的线程。此策略可以避免在处理可能具有内部依赖性的请求集时出现锁。直接提交通常要求无界 maximumPoolSizes 以避免拒绝新提交的任务。当命令以超过队列所能处理的平均数连续到达时,此策略允许无界线程具有增长的可能性。
无界队列策略,即LinkedBlockingQueue
使用无界队列(例如,不具有预定义容量的 LinkedBlockingQueue)将导致在所有corePoolSize 线程都忙时新任务在队列中等待。这样,创建的线程就不会超过 corePoolSize。(因此,maximumPoolSize的值也就无效了。)当每个任务完全独立于其他任务,即任务执行互不影响时,适合于使用无界队列;例如,在 Web页服务器中。这种排队可用于处理瞬态突发请求,当命令以超过队列所能处理的平均数连续到达时,此策略允许无界线程具有增长的可能性。
有界队列,使用ArrayBlockingQueue
当使用有限的 maximumPoolSizes时,有界队列(如 ArrayBlockingQueue)有助于防止资源耗尽,但是可能较难调整和控制。队列大小和最大池大小可能需要相互折衷:使用大型队列和小型池可以最大限度地降低 CPU 使用率、操作系统资源和上下文切换开销,但是可能导致人工降低吞吐量。如果任务频繁阻塞(例如,如果它们是 I/O边界),则系统可能为超过您许可的更多线程安排时间。使用小型队列通常要求较大的池大小,CPU使用率较高,但是可能遇到不可接受的调度开销,这样也会降低吞吐量。
JDK中4个内置线程池的代码:
newFixedThreadPool (int nThreads):固定大小线程池
- public static ExecutorService newFixedThreadPool(int nThreads) {
- return new ThreadPoolExecutor(nThreads, nThreads,
- 0L, TimeUnit.MILLISECONDS,
- new LinkedBlockingQueue<Runnable>());
- }
newSingleThreadExecutor():单线程
- public static ExecutorService newSingleThreadExecutor() {
- return new FinalizableDelegatedExecutorService
- (new ThreadPoolExecutor(1, 1,
- 0L, TimeUnit.MILLISECONDS,
- new LinkedBlockingQueue<Runnable>()));
- }
newCachedThreadPool():无界线程池,可以进行自动线程回收
- public static ExecutorService newCachedThreadPool() {
- return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
- 60L, TimeUnit.SECONDS,
- new SynchronousQueue<Runnable>());
- }
newScheduledThreadPool ():定时任务线程池
- //预定执行而构建的固定线程池
- public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
- return new ScheduledThreadPoolExecutor(corePoolSize);
- }
1.6.扩展和增强线程池
1.6.1.回调接口
ThreadPoolExecutor对以下方法进行了空实现,所以需要开发者继承ThreadPoolExecutor并且重写实现以下方法。
protected void beforeExecute(Thread t, Runnable r) { }
protected void afterExecute(Runnable r, Throwable t) { }
protected void terminated() { }
1.6.2. 拒绝策略
RejectedExecutionHandler接口提供了对于拒绝任务的处理的自定方法的机会。在ThreadPoolExecutor中已经默认包含了4中策略。
CallerRunsPolicy:线程调用运行该任务的 execute 本身。此策略提供简单的反馈控制机制,能够减缓新任务的提交速度。
AbortPolicy:处理程序遭到拒绝将抛出运行时RejectedExecutionException。
DiscardPolicy:不能执行的任务将被删除
DiscardOldestPolicy:如果执行程序尚未关闭,则位于工作队列头部的任务将被删除,然后重试执行程序(如果再次失败,则重复此过程)
使用内置策略代码示例:
- ThreadPoolExecutor e=new ThreadPoolExecutor( 2, 3, 30, TimeUnit.SECONDS,
- new SynchronousQueue<Runnable>(),
- Executors.defaultThreadFactory() ,
- //传入要使用的策略
- new ThreadPoolExecutor.CallerRunsPolicy());
使用自定义策略代码示例:
- ThreadPoolExecutor e= new ThreadPoolExecutor( 2, 3, 30, TimeUnit.SECONDS,
- new SynchronousQueue<Runnable>(),
- Executors.defaultThreadFactory() ,
- new RejectedExecutionHandler(){
- public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
- //do something
- }
- }
- );
1.6.3.自定义ThreadFactory
- public class CustomThreadFactory implements ThreadFactory
- {
- private int counter;
- private String name;
- private List<String> stats;
- public CustomThreadFactory(String name)
- {
- counter = 1;
- this.name = name;
- stats = new ArrayList<String>();
- }
- @Override
- public Thread newThread(Runnable runnable)
- {
- Thread t = new Thread(runnable, name + "-Thread_" + counter);
- counter++;
- stats.add(String.format("Created thread %d with name %s on %s \n", t.getId(), t.getName(), new Date()));
- return t;
- }
- public String getStats()
- {
- StringBuffer buffer = new StringBuffer();
- Iterator<String> it = stats.iterator();
- while (it.hasNext())
- {
- buffer.append(it.next());
- }
- return buffer.toString();
- }
- }