机器学习西瓜书要点归纳
第2章 模型评估与选择
2.1 经验误差与过拟合
错误率(error rate):分类错误的样本数占样本总数的比例。
精度(accuracy):1-错误率
误差(error):学习器的实际预测输出与样本的真实输出的差异。
训练误差(training error)/经验误差(empirical error):学习器在训练集上的误差。
泛化误差(generalization error):学习器在新样本上的误差。
过拟合(overfitting):把只是训练样本的特点当做所有样本的一般性质,泛化性能下降。
欠拟合(underfitting):训练样本的一般性质还没学好。
模型选择(model selection):选用学习算法和参数配置的问题。

2.2 评估方法
测试集(testing set):用于测试学习器对新样本的判别能力。
测试误差(testing error):泛化误差的近似。
一些从数据集D处理以产生训练集S和测试集T的方法:
2.2.1 留出法
D=S∪T,S∩T=Ø
2.2.2 交叉验证法
k折交叉验证:把样本均分为k份,做k次训练和测试,第i次用第i个做T,其他做S。
10次10折交叉验证是100次,100次留出法也是100次。
留一法:k=样本个数m,这时训练样本尽可能多,模型效果尽可能和m个全部训练相同。
2.2.3 自助法
样本个数m,对D进行m次有放回抽样得到D’,S=D’,T=D\D’。
这样子有m个样本做训练S,且有 m ∗ ( 1 − 1 / m ) m = m / e m*(1-1/m)^m=m/e m∗(1−1/m)m=m/e(当m趋于无穷)个样本做T。
好处:1数据集小有用2能产生不同训练集集成学习。
坏处:改变数据集分布,引入估计偏差。
(S信息量还是 m ( 1 − 1 / e ) m(1-1/e) m(1−1/e),数量到了m自欺欺人)
2.2.4 调参与最终模型
调参(parameter tuning):对参数设定。
验证集(validation set):用于模型评估测试的数据集。
2.3 性能度量
性能度量(performance measure):衡量模型泛化能力的评价标准。
均方误差(mean squared error):回归任务最常用的性能度量:
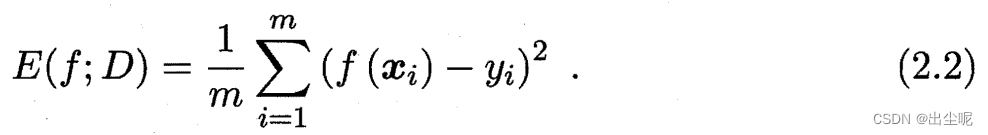
当不是离散样本而是连续分布的一般形式:
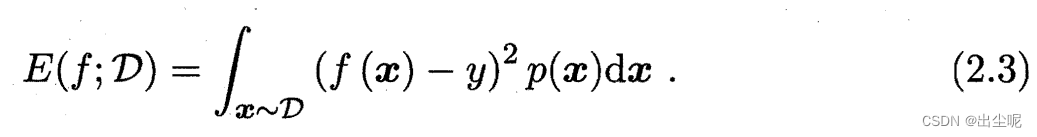
2.3.1 错误率与精度
错误率与精度:分类任务的性能度量
错误率:
精度:
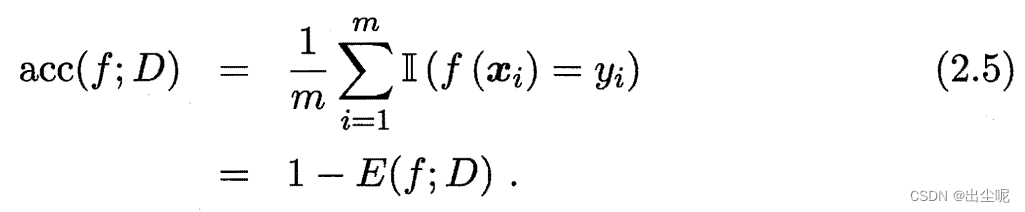
当不是离散样本而是连续分布的一般形式,类似于MSE。
2.3.2 查准率、查全率与F1
混淆矩阵(confusion matrix):

真(true)假(false)表示预测的和真实的是否一致;
正(positive)反(negative)表示预测的值。
连在一起读就是真实情况。
查准率(precision,准):
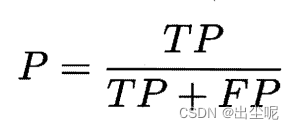
查全率(recall):
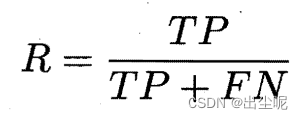
P-R曲线:
按是正例可能性从大到小把样本排序,按顺序逐个把样本作为正例预测,可描点作图:
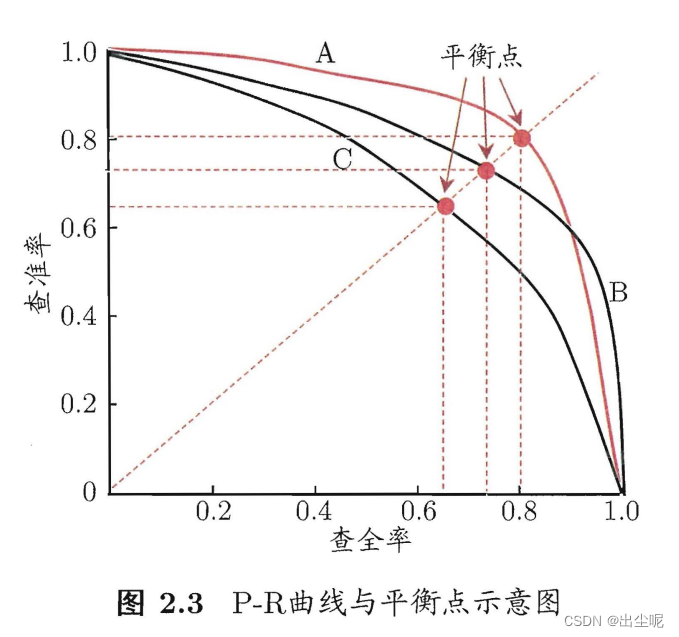
现实的P-R曲线未必单调,比如先纳入了几个错误的,再纳入了几个正确的,此时同时增加了查准率查全率。
判断学习器性能:
- A的P-R被B的P-R完全包住:B优于A,一定。
- A的P-R下方面积小于B:B优于A,合理。
- 平衡点A小于B:B优于A,过于简化了。
平衡点(Break-Even Point,BEP):P=R时的取值 - F1度量A小于B:B优于A,相同重视时合理。
F1度量:P和R的调和平均:
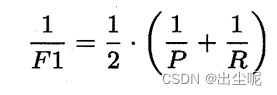
- Fβ度量A小于B:B优于A,对查全率R有β重视时合理。
Fβ度量:P和R的加权调和平均: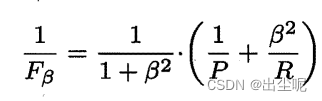
F1,当一个变量固定,另一个变量呈log形式。
即“调和平均更重视较小值”
那么加权调和平均即,加权后,越重视某一方,某一方较小时,调和平均小的比另一方越明显。
- 当有n个二分类时,可用 宏(macro)或 微(micro)在不同粒度上做平均,以推断性能:
宏是n个P-R算出来后平均,宏F1用宏P-R算。
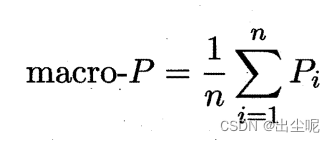
微是n个TF+PN平均后算P-R,微F1用微P-R算。
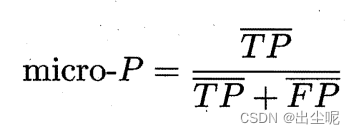
以上大小关系不确定。
例如有100个样本的二分类和有1个样本的二分类,
P值前者1后者0,和后者1前者0,分别是micro-P和macro-P大。
2.3.3 ROC与AUC
分类阈值(threshold):预测值大于阈值为正,小于为负。
截断点(cut point):按预测值从大到小排序,截断点将样本分为两部分。
真正例率(True Positive Rate,TPR):真阳性在真正阳性的比例。
假正例率(False Positive Rate,FPR):假阳性在真正阴性的比例。

ROC(Receiver Operating Characteristic,受试者工作特征):纵轴为TPR,横轴为FPR的曲线。
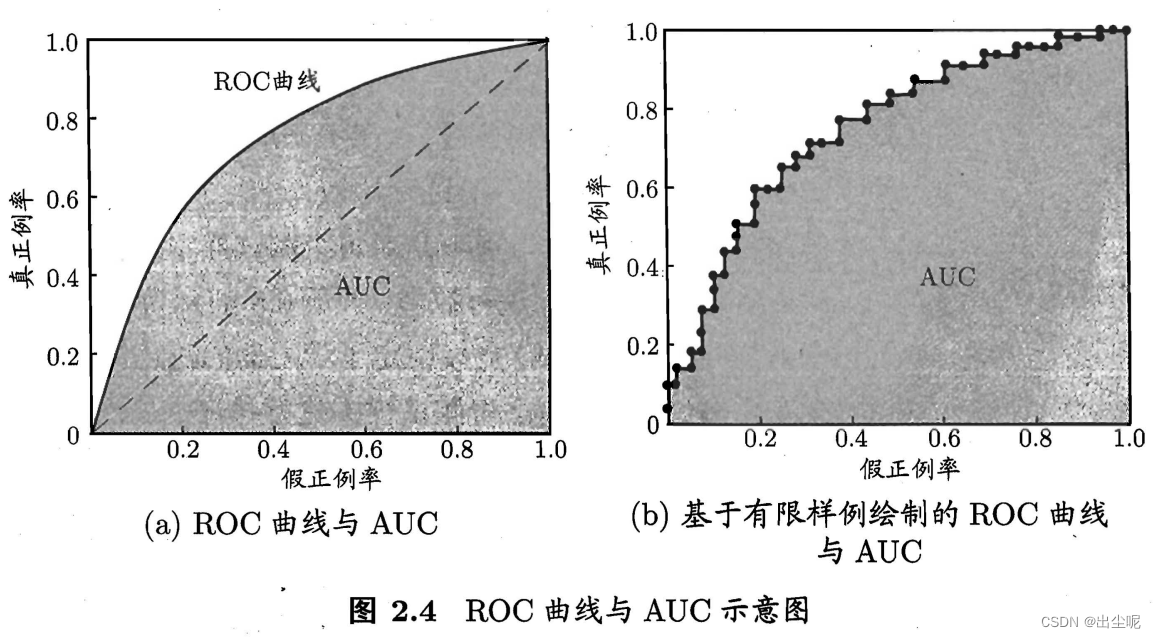
一定是单调递增的,因为越来越宽松,阳性越来越多。
判断好坏:
- ROC曲线A被B包住,则B好于A——正确。
- AUC值A比B小,则B 好于A——合理。
AUC(Area Under ROC Curve):ROC曲线下的面积。
实际情况AUC可算(和P-R曲线下面积不一样),用梯形积分法即可: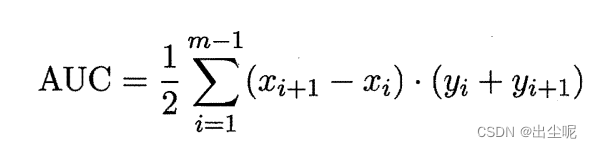
l r a n k l_{rank} lrank是
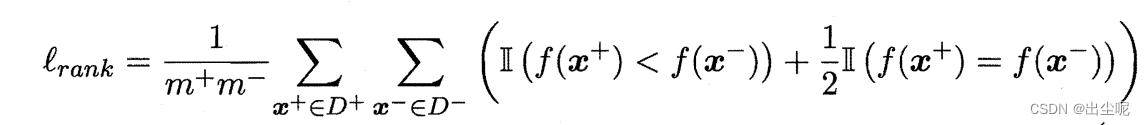
把ROC图分为 m + ∗ m − m^+*m^- m+∗m−的小方格,不难看出有 l r a n k = 1 − A U C l_{rank}=1-AUC lrank=1−AUC
2.3.4 代价敏感错误率与代价曲线
非均等代价(unequal cost):权衡不同类型错误造成的不同损失。
代价矩阵(cost matrix):把真实i类分到j类的代价是 c o s t i j cost_{ij} costij。
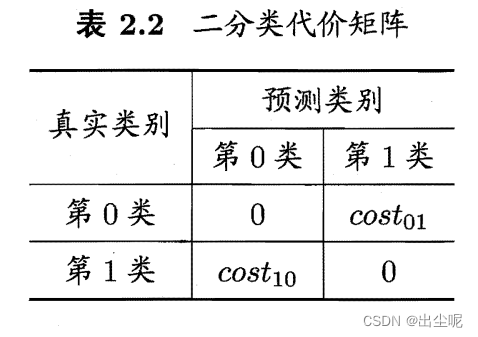
总体代价(total cost):非均等代价下,要最小化的目标。
代价敏感(cost-sensitive)错误率:
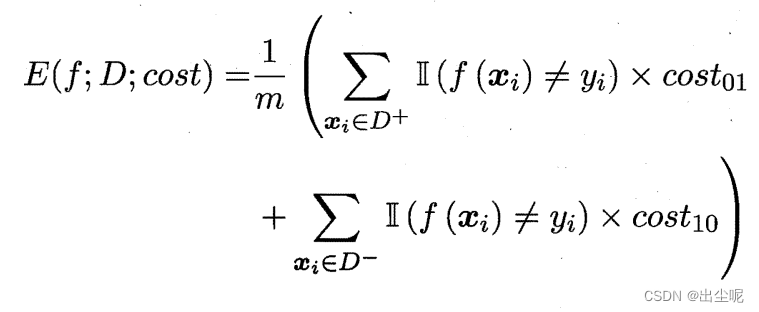
(显然这也不再在 [ 0 , 1 ] [0,1] [0,1]之间了。)
代价曲线(cost curve):可以反映学习器的期望总体代价大小(ROC不能)
以p为样例为正例的概率,
横轴是正例概率代价 P ( + ) c o s t P(+)cost P(+)cost
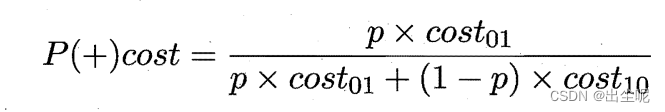
纵轴是归一化代价:
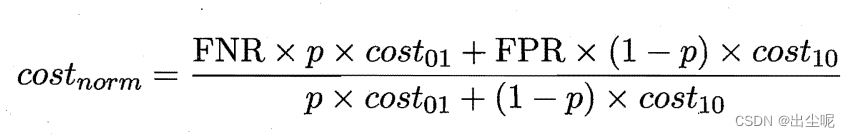
优点:作图简单:
c o s t n o r m = F N R ( P ( + ) c o s t ) + F P R ( 1 − P ( + ) c o s t ) cost_{norm}=FNR(P(+)cost)+FPR(1-P(+)cost) costnorm=FNR(P(+)cost)+FPR(1−P(+)cost)
是一条直线,过(0,FPR),(1,FNR)
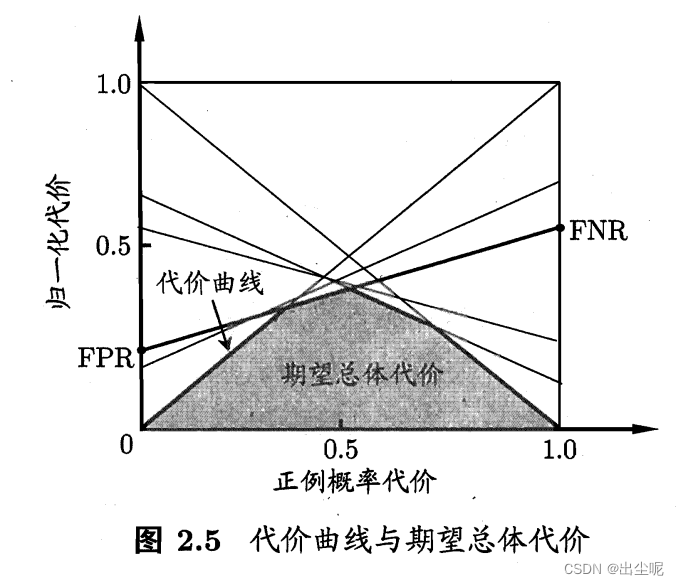
期望总体代价的注意点:
1.只看面积,和代价无关。
2.但是cost不均能带来P倾向于大或者小,自变量P和因变量归一化代价有关:
当 c o s t 10 = 0 cost_{10}=0 cost10=0,应该重视类0分为1的代价,降低FNR,
此时 p − P ( + ) c o s t p-P(+)cost p−P(+)cost关系图:
P ( + ) c o s t P(+)cost P(+)cost作为错误率停留在较大的范围较密集,关注这一块,此时归一化代价最小的直线就是FNR最小的,这就是被选取的。
更多理解可参考该链接的高赞回答。
2.4 比较检验
统计假设检验(hypothesis test):从样本推导出有一般结论的可能性多大。
具体来说,测试集效果(样本)离学习器泛化性能(一般结论)还有一定的随机性,统计假设检验可以用于此,看看A比B好的结论的把握有多大。
2.4.1 假设检验
假设:对学习器泛化错误率分布的某种判断或猜想。
举例1:
设真实错误率 ϵ \epsilon ϵ而测试集错误率 ϵ ^ \hat{\epsilon} ϵ^,
测试集错误的样本个数 ϵ ^ × m \hat{\epsilon} \times m ϵ^×m,以及 ϵ ^ \hat{\epsilon} ϵ^符合二项分布。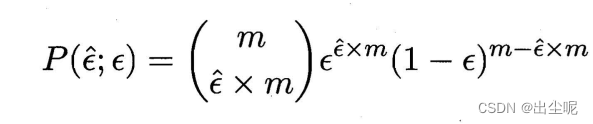
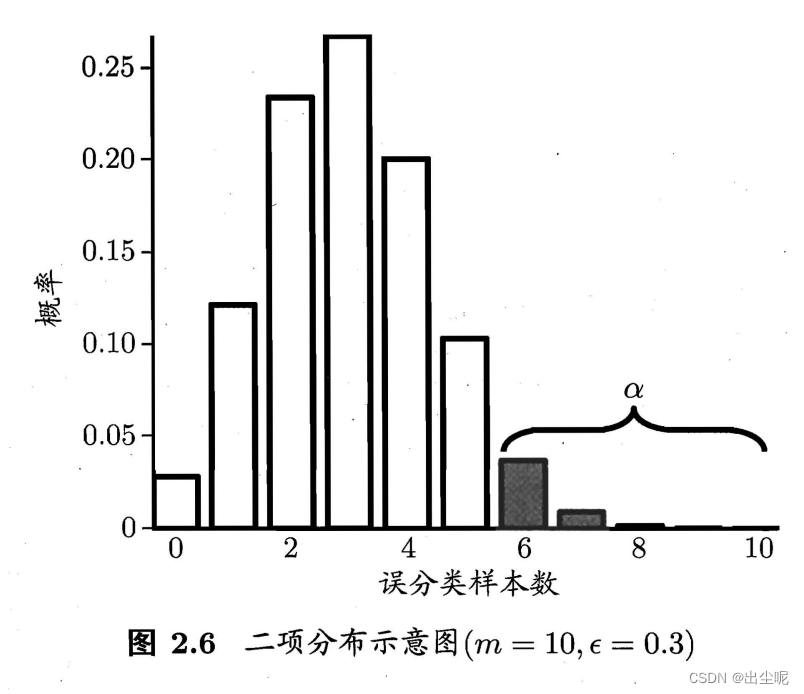
那么对于假设 ϵ ≤ ϵ 0 \epsilon\le\epsilon_0 ϵ≤ϵ0,当有 1 − α 1-\alpha 1−α的置信度可相信它是真,且 α \alpha α在右边(如图阴影部分)时,最大可观测的错误率为:
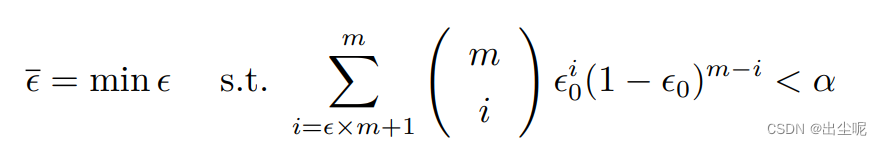
由南瓜书的勘误。
当 ϵ = ϵ 0 \epsilon=\epsilon_0 ϵ=ϵ0时得到。
注意公式里的 ϵ \epsilon ϵ是变量而不是真实错误率。
举例2:
当有k个测试错误率,这是一个t分布。
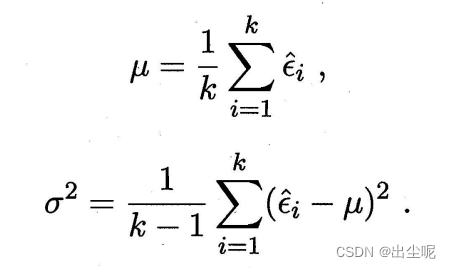
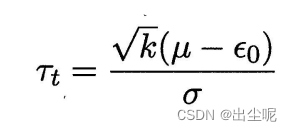
概率论知识,
测试错误率均值 μ \mu μ,泛化错误率 ϵ 0 \epsilon_0 ϵ0,
假设 μ = ϵ 0 \mu=\epsilon_0 μ=ϵ0,
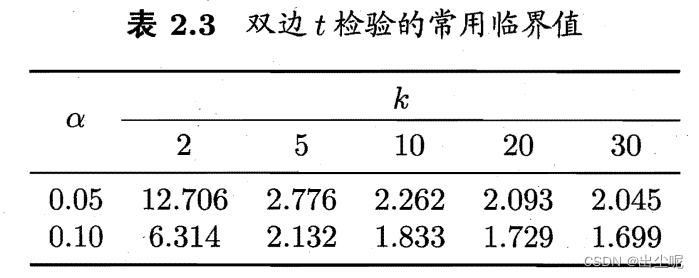
当在 1 − α 1-\alpha 1−α置信度成立且 α \alpha α在两边各一半,
要求实际观察的 μ − ϵ 0 \mu-\epsilon_0 μ−ϵ0在 [ t − α / 2 , t α / 2 ] [t_{-\alpha/2},t_{\alpha/2}] [t−α/2,tα/2]内
查表得值。
2.4.2 交叉验证 t t t检验
用于对比两个学习器AB的性能。
做K折数据集,在AB上有K个A的错误率和K个B的错误率,作差值得到K个差值,作t检验。
做法:
假设是“AB性能相同”,当在 1 − α 1-\alpha 1−α置信度成立且 α \alpha α在两边各一半,当差的值平均来说在 [ t − α / 2 , t α / 2 ] [t_{-\alpha/2},t_{\alpha/2}] [t−α/2,tα/2]内,不能被拒绝,否则,就可以说一个比另一个性能有显著差别。
改进:
以上方法违背了前提:k折,k>2时,两两共用部分训练集,导致这两次更加接近,导致方差有变,所以有误。
期望均值E1 < E2 时,
当有E1对比E2,标准差E2-E1,这是违背
但是真实情况当E1+1 E1-1 E1+1 E1-1 对比E2+1 E2-1 E2-1 E2+1, 2 ( E 2 − E 1 ) 2 + ( E 2 − E 1 − 2 ) 2 + ( E 2 − E 1 + 2 ) 2 = 4 ( E 2 − E 1 ) 2 + 8 2(E2-E1)^2+(E2-E1-2)^2+(E2-E1+2)^2=4(E2-E1)^2+8 2(E2−E1)2+(E2−E1−2)2+(E2−E1+2)2=4(E2−E1)2+8,大于了应该的4(E2-E1)2,标准差变大。
所以我认为是这种做法比真实情况假设更不容易成立。
感觉书上说反了。(请读者评价指正)
提出5x2 交叉验证(书可能有误),
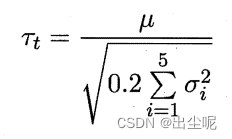
服从自由度为5的t分布,其中:

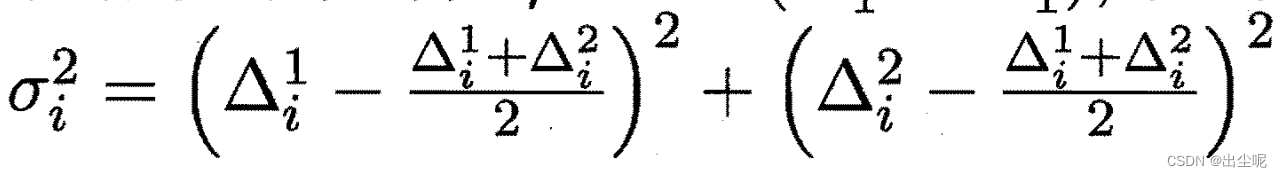
以上也可能错了,挺魔幻的,不可尽信西瓜书。
参考链接
想想看,自由度肯定比4还小。
此外,有人说,这样子方差也会有重叠不独立的,所以有问题。
2.4.3 McNemar 检验

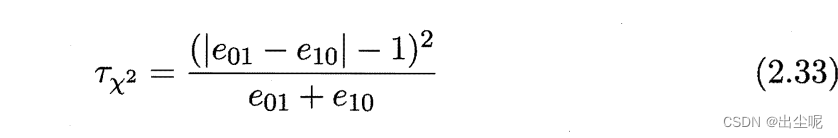
假设AB性能相同,则服从卡方分布(正态分布的平方),可以卡方检验。
2.4.4 Friedman 检验与 Nemenyi 后续检验
Friedman检验用于:多个算法的比较。
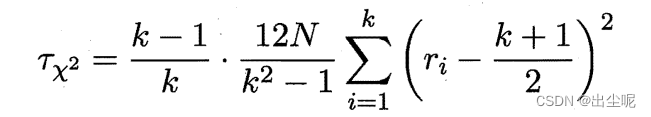

可以理解。
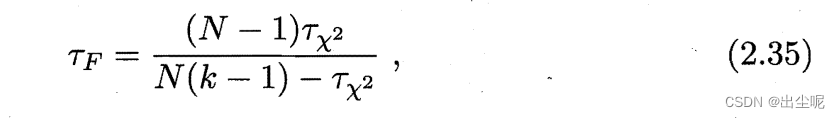
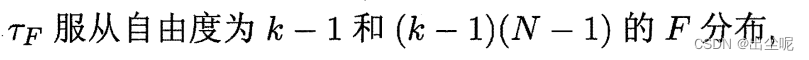
当假设不成立,也就是两两算法性能要比较了,
这里又介绍了Nemenyi 后续检验方法,
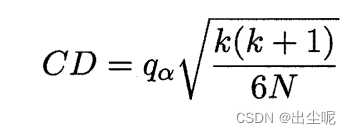
q α q_{\alpha} qα是查表的。
当两个差距小于CD,就不能在 α \alpha α置信度下推翻“两个算法相同”的假设,否则可以说两个算法性能有显著差异。
可以画图直观看出来:
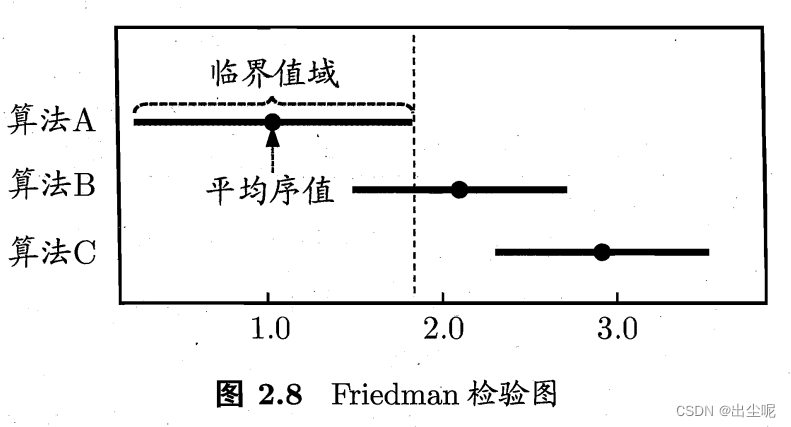
2.5 偏差与方差
这套推导是理论基础:

偏差-方差窘境:
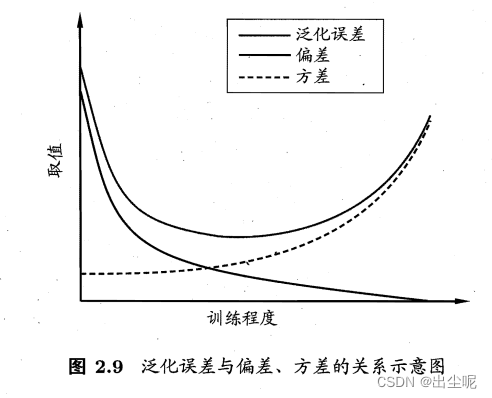
2.6 阅读材料
习题

分情况看,
不考虑平衡,1000个选300个的方式
注意,实际上考虑类别个数平衡,是500个选150个的方式

凭感觉,期望是1/2
但是实际上要去算:
10折,每个90个,是45:45的期望,是1/2(且考虑实际情况要平衡,就确实是1/2)
但是留一,每个99个,是44:45的期望,一定是错了,是1
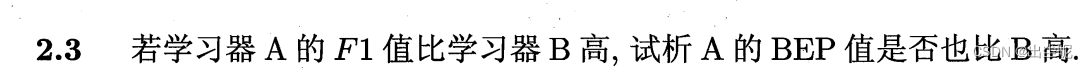
1 / F 1 = 1 / P + 1 / R 1/F1=1/P+1/R 1/F1=1/P+1/R
F 1 A > F 1 B 恒成立则 F1A>F1B恒成立则 F1A>F1B恒成立则
1 / P A + 1 / R A < 1 / P B + 1 / R B 1/PA+1/RA<1/PB+1/RB 1/PA+1/RA<1/PB+1/RB
令 P A = R A , P B = R B 令PA=RA,PB=RB 令PA=RA,PB=RB
P A > P B PA>PB PA>PB
是。
但是,如果只是有一个F1A>F1B,则不能说明问题。

TPR=TP/(TP+FN)
FPR=FP/(FP+TN)
P=TP/(TP+FP)
R=TP/(TP+FN)
则TPR=R
其他的无明显联系,但是都是相关的。

笔记写过了原因。

ROC的横轴是FPR,纵轴是TPR。
TPR=TP/(TP+FN)
FPR=FP/(FP+TN)
错误率是(FP+FN)/(TP+TN+FP+FN)
FPR越小,TPR越大,错误率越小。
每一个ROC曲线的点都对应一个错误率。

根据作图方法构造可得。

2.43的优点:
能保证数据在x’min,x’max范围。2.44做不到。
这样子就可灵活设置归一化后的区间。
2.44的优点:
能保证数据的均值固定为0,标准差固定为1。2.43做不到。
这样子更不会被离群点干扰。

1.求出服从卡方分布的值
2.查表
3.若值在区间内,则假设成立,否则,假设不成立

上面的没考虑不同数据集的方差,在样本量较小的情况下,式1计算结果明显偏离卡方分布,下面的考虑了。
参考这个和这个