一、论文简述
1. 第一作者:Kunming Luo
2. 发表年份:2021
3. 发表期刊:CVPR
4. 关键词:光流,上采样金字塔,无监督,深度学习
5. 探索动机:关于金字塔学习有两个主要问题,称为自底向上和自顶向下的问题。自底向上问题指的是金字塔中的上采样模块。现有方法通常采用简单的双线性或双三次上采样,插值交叉的边缘,导致预测光流中出现模糊伪影。当尺度变得更精细时,这些误差将被传播和聚集。自上而下的问题是指金字塔式监督。以往领先的无监督方法通常只在网络的最终输出上增加指导损失,而中间金字塔层没有指导。在这种情况下,由于缺乏训练指导,较粗层次的估计误差会累积并破坏较细层次的估计。
6. 工作目标:解决上述问题。
7. 核心思想:为此,提出了一种改进的无监督光流估计金字塔学习框架。
- We propose a self-guided upsampling module to tackle the interpolation problem in the pyramid network, which can generate the sharp motion edges.
- We propose a pyramid distillation loss to enable robust supervision for unsupervised learning of coarse pyramid levels.
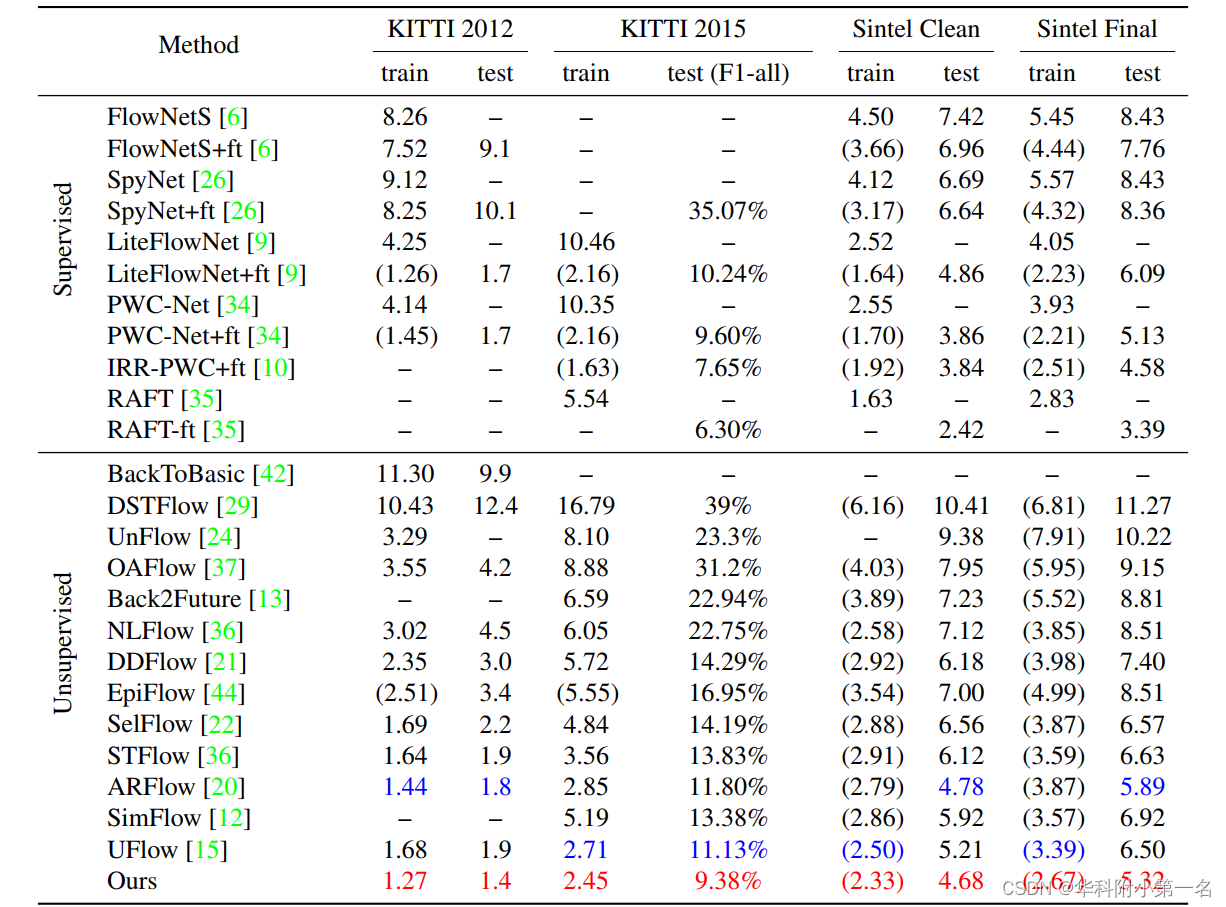
8. 实验结果:
We achieve superior performance over the state-of-theart unsupervised methods with a relatively large margin, validated on multiple leading benchmarks.
9.论文及代码下载:
https://github.com/coolbeam/UPFlow_pytorch
二、实现过程
1. 多视角和单目线索的特点
网络管道如图所示。网络可以分为两个阶段:金字塔编码和金字塔解码。
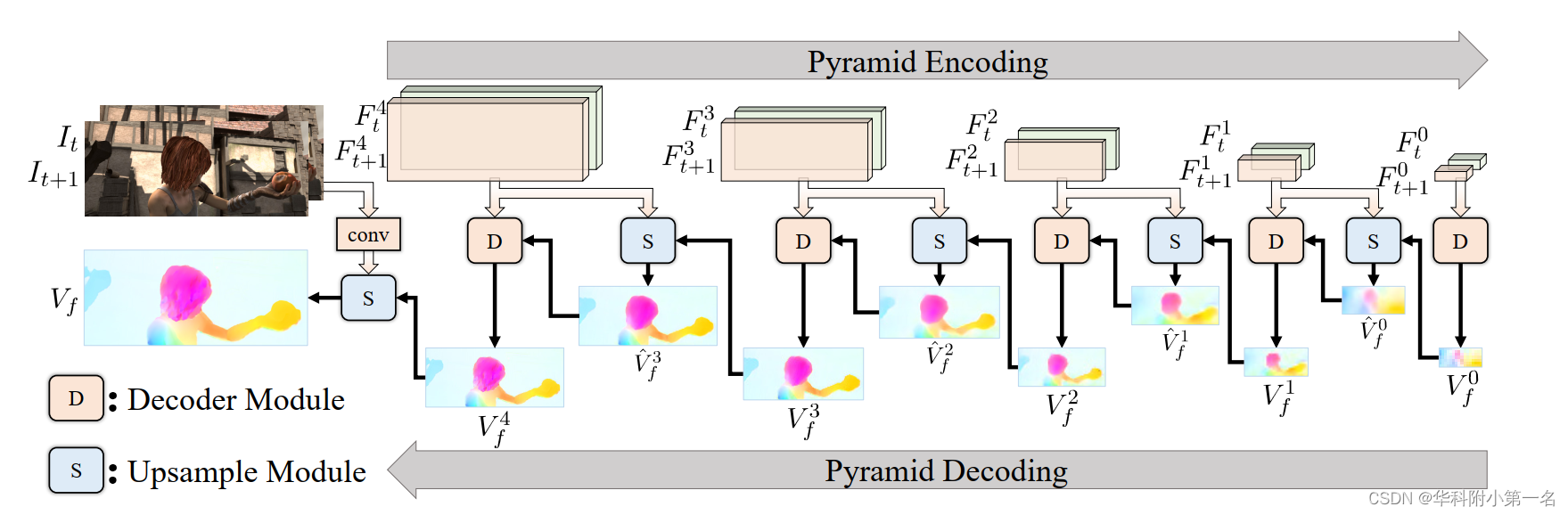
在第一阶段,通过卷积层从输入图像中提取不同尺度的特征对。在第二阶段,使用解码器模块D和上采样模块S↑以粗到精的方式估计光流。解码器模块D的结构与UFlow相同,包含特征warp、通过相关层构建代价体、代价体归一化、全卷积层光流解码。D和S↑的参数在所有金字塔水平上共享。综上所述,金字塔解码阶段可以表述为:
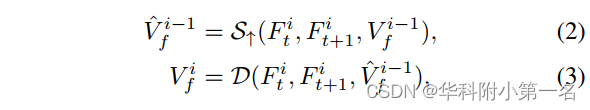
式中I∈{0,1,…, N}为各金字塔层的指数,越小者越粗,Fti和Fit+1为第i层从It和It+1中提取的特征,V`fi−1为第i−1层的上采样流。在实践中,考虑到准确性和效率,通常将N设置为4。最后的光流结果是通过直接对最后一个金字塔级的输出进行上采样获得的。特别是在式2中,以前的方法通常使用双线性插值对光流场进行上采样,这可能会在物体边界处产生噪声或模糊结果。本文提出了一个自引导的上采样模块来解决这个问题。
2. 自引导上采样模块
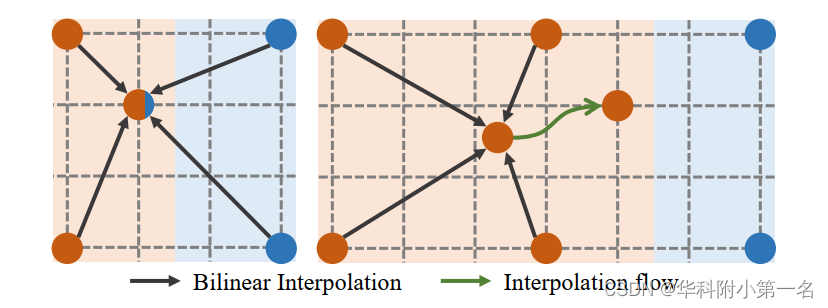
在图左,双线性插值的情况。显示了4个点,代表4个流向量,属于两个运动源,分别标记为红色和蓝色。然后在没有语义指导的情况下对缺失区域进行双线性插值。因此,在红色运动区域产生混合插值结果,从而产生交叉边缘插值。为了缓解这一问题,提出了一种自引导的上采样模块(SGU)通过插值流更改插值源点。SGU的主要思想如图右所示。首先通过一个点的封闭红色运动进行插值,然后使用学习到的插值流程将结果带到目标位置(图3,绿色箭头)。从而避免了混合插补问题。
在设计中,为了保持平面区域的插值不被改变,并且使插值流只应用于运动边界区域,学习了一个逐像素权重图来指示应该禁用插值流的位置。因此,SGU的上采样过程是双线性上采样流与用插值流warp上采样流得到的修正流的加权组合。SGU模块的详细结构如图所示。
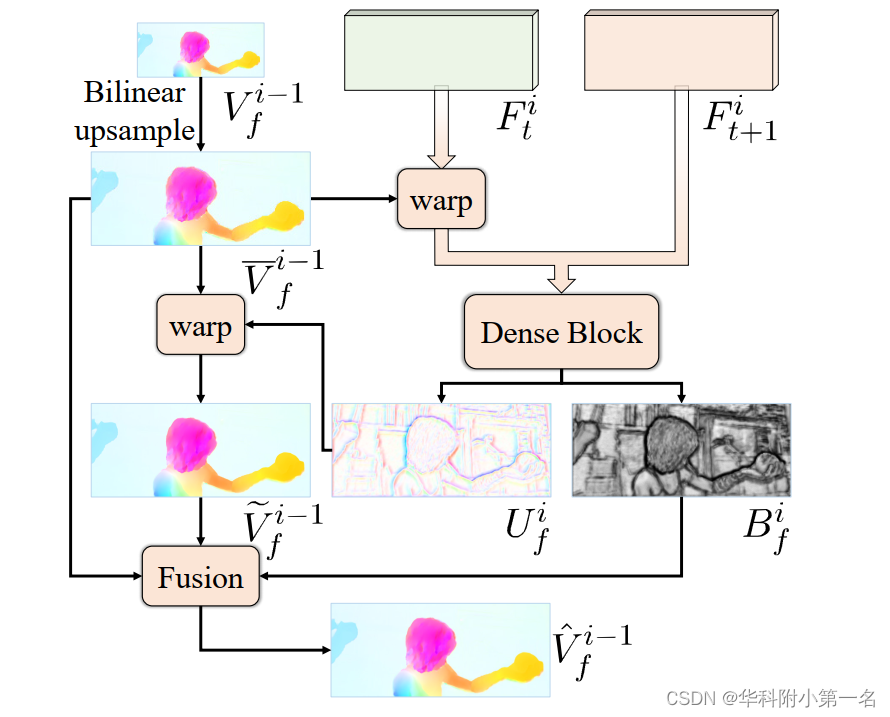
给定从i−1层的低分辨率流Vfi−1,首先通过双线性插值生成更高分辨率的初始流v~if−1:
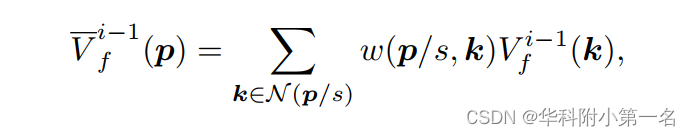
式中,p为更高分辨率的像素坐标,s为尺度放大倍数,N为相邻4个像素,w(p/s, k)为双线性插值权值。然后,从特征Fti和特征Fit+1计算插值流Ufi通过warp改变V-i−1f的插值:
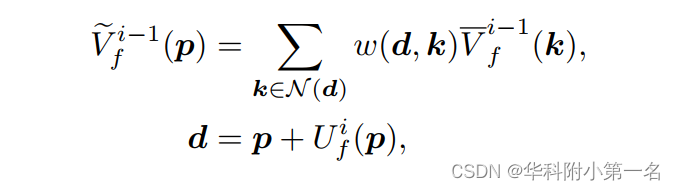
其中V~i−1f为插值流Ui f对V-i f−1进行扭曲的结果。由于插值模糊只发生在物体边缘区域,因此无需学习平坦区域的插值流。因此,使用插值图Bfi来明确地强制模型仅在运动边界区域学习插值流。最终的上样结果是V~i−1f和V-i f−1的融合:

其中V是模块的输出,⊙是元素乘法器。
为了生成插值流Ufi和插值图Bfi,使用了一个具有5个卷积层的密集块。具体来说,将特征图Fti和warp的特征图Fti+1连接起来作为密集块的输入。密集块中每个卷积层的核数分别为32、32、32、16、8。密集块的输出是一个具有3个通道的张量图。使用张量图的前两个通道作为插值流,使用最后一个通道通过sigmoid层形成插值图。注意,对于插值流和插值图的学习没有引入监督。下图显示了一个来自MPISintel Final数据集的示例,与双线性方法相比,SGU在对象边界产生了更清晰、更清晰的结果。有趣的是,自学习插值图几乎是一个边缘图,插值流也集中在目标边缘区域。

3. 金字塔水平的损失指导
使用几种损失来训练金字塔网络:最终输出流的无监督光流损失和不同金字塔层的中间流的金字塔蒸馏损失。
3.1 无监督光流损失
为了学习无监督设置下的流估计模型H,使用基于光度恒定假设的光度损失Lm,其中相同的物体在It和It+1一定有相似的强度。然而,有些区域可能会被移动的物体遮挡,从而使其对应的区域在另一幅图像中不存在。由于光度损失不能在这些区域工作,只添加Lm在未遮挡区域。光度损失可表示为:
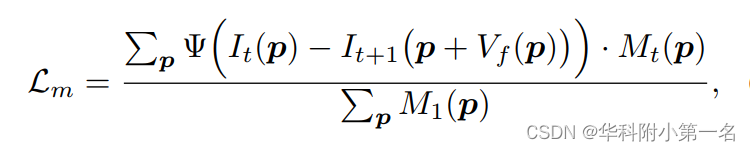
其中Mt为遮挡掩模,Ψ为鲁棒惩罚函数:Ψ(x) = (|x| + ω)q,其中q为0.4,ω为0.01。在前后向检查估计的遮挡掩码Mt中,1表示其中未遮挡的像素,0表示被遮挡的像素。
为了提高性能,还加入了一些以前有效的无监督分量,包括平滑损Ls、普查损失Lc、增强正则化损失La和边界空洞warp损失Lb。为简单起见,省略了这些组件的解释。
3.2 金字塔蒸馏损失
为了学习每个金字塔层的中间流,建议通过金字塔蒸馏损失Ld将最好的输出流蒸馏到中间流。直观地说,这相当于计算每个中间输出上的所有无监督损失。然而,光度一致性测量对于低分辨率下的光流学习不够精确[。因此,在中间阶层,特别是在金字塔的下层,实施无监督的损失是不合适的。因此,建议使用最好的输出流作为伪标签,并为中间输出添加监督损失而不是无监督损失。
为了计算Ld,直接对最终输出流进行下采样,并评估其与中间流的差异。由于Lm中没有遮挡区域,遮挡区域的流量估计是有噪声的。为了消除伪标签中这些噪声区域的影响,还对遮挡蒙版Mt进行下采样,并从Ld中排除遮挡区域。因此,金字塔蒸馏损失可以表示为:
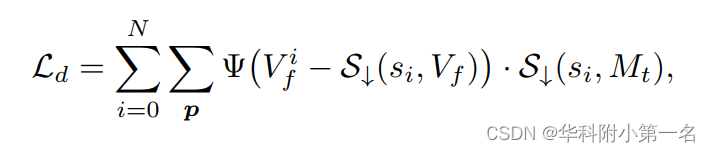
其中si是金字塔第i层的尺度放大倍数,S↓为下采样函数。最终,训练损失L表示为:
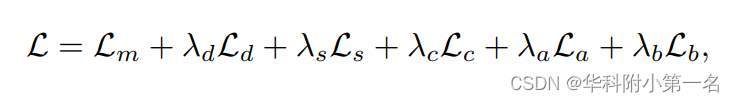
其中λd、λs、λc、λa、λb为超参数,设λd = 0.01、λs = 0.05、λc = 1、λa = 0.5、λb = 1。
4. 实验
4.1. 与先进技术的比较