
作者 | Dwarkesh Patel
OneFlow编译
翻译|杨婷、宛子琳
AGI何时会到来?
如果我们能不断扩展LLMs++的规模(并因此取得更好和更通用的性能),就有理由期望到2040年(或更早)出现强人工智能,它能够自动化大部分认知劳动并加速人工智能研究。然而,如果扩展(scaling)不起作用,那么实现AGI的道路则会变得更加漫长、棘手。
为全面探讨有关扩展的正反观点,我构造了两个虚构角色(正方和反方),以辩论的形式讨论问题。
1
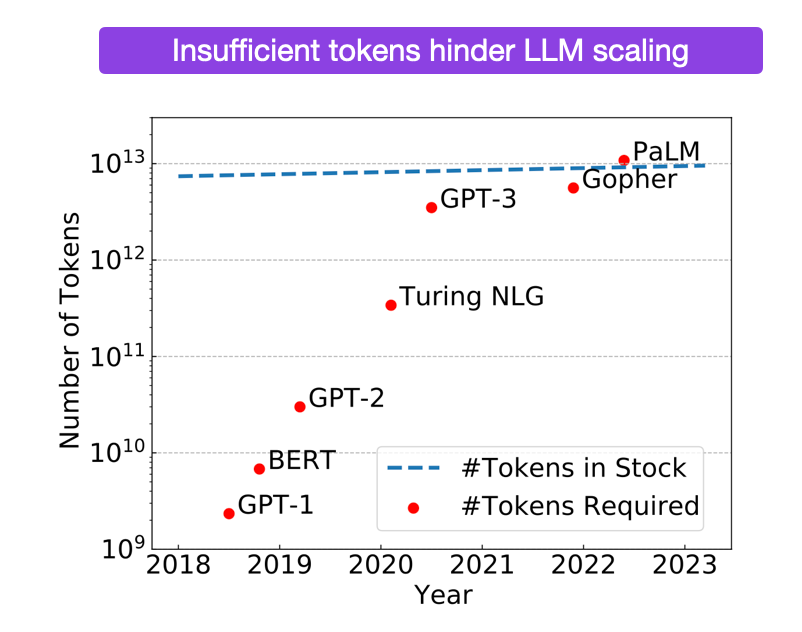
数据是否会用尽?
反方:
我们将在明年耗尽高质量语言数据(https://epochai.org/blog/will-we-run-out-of-ml-data-evidence-from-projecting-dataset)。
即便我们认真对待那些扩展曲线所暗示的趋势,也意味着我们需要1e35次浮点运算(FLOPs)才能让人工智能足够可靠和聪明,能够撰写科学论文(这是人工智能需要进一步自动化人工智能研究,并在无法扩展时能够继续推进所需的基本能力)[1]。这意味着我们需要的数据要比现有数据多5个数量级[2]。
人们可能对“5个数量级的差距”这一概念有所误解,认为当前的数据量只比我们实际需要的少5倍,所以我们只需在数据效率上取得多次2倍改进,问题就迎刃而解了,毕竟朋友之间差几个数量级也没什么大不了的。
可实际上,5个数量级的差距意味着当前数据量比实际需求少了100,000倍。尽管有一些可以提升数据效率的算法,而且多模态训练可以提供更多数据,另外我们可以在多个轮次上重复利用词元,并使用课程学习(Curriculum learning),但即使我们假设这些技术能够极大地提升数据效率,它们依然无法提供足够多的数据来应对规模扩展所需的指数级计算增长。
有人可能会说,我们可以设法让自我对弈(self-play)或合成数据发挥作用。但自我对弈面临以下两个难题。
评估:人们曾成功地将自我对弈运用于AlphaGo,因为该模型可以根据具体的获胜条件来评判自己的表现(如“我是否赢得了这局围棋?”)。但新颖的推理并没有具体的获胜条件,因此,正如你所期望的那样,LLM迄今无法纠正自己的推理能力。
计算:所有这些数学/编码方法往往会使用各种类型的树搜索,其中每个节点都需要运行LLM。AlphaGo在围棋这个相对狭窄的任务中的计算预算已经相当惊人了,我们可以试想一下,将其应用于搜索所有可能的人类思维空间所需要的计算资源将会有多么庞大。这些额外计算量还不包括已经要求扩展参数规模(计算=参数*数据)增加的巨大计算资源。达到人类水平思考所需的计算量估计约为1e35 FLOP,我们需要额外增加9个数量级的计算,以应对当前最大模型已有的计算量。我承认,通过更好的硬件和更先进的算法可能会有所改进,但我们真的能够实现相当于9个数量级的计算性能提升吗?
正方:
如果你对扩展有效性的主要质疑仅仅是出于担心数据不足,那么你的第一反应就不应该是“看起来我们本可以通过扩展Transformer++来实现通用人工智能,但在此之前我们会先耗尽数据”。
你的反应应该是:“如果互联网规模更大,扩展一个相对简单(仅用几百行Python代码就能编写其基本结构)的模型就可以创造出人类水平的智能,这是一个多么疯狂的世界啊,实现大规模计算智能化竟然如此简单。”
LLM表现出“低效”的样本主要来源于不相关的电子商务垃圾[3]。通过利用“预测下一个词元”进行训练,我们加剧了这一缺陷。这种损失函数在很大程度上与我们希望智能体在经济中执行的实际任务无关。尽管模型训练所使用的数据和损失函数与我们实际期望的能力之间的交集微乎其微,但我们只需微软年收入的0.03%,就能通过大规模爬取互联网制造出一个初级AGI(即GPT-4)。
人工智能的发展迄今为止都相对轻松和简单,因此合成数据也有可能奏效,毕竟模型天然具有学习愿望,这没什么好惊讶的。
目前,GPT-4已经问世八个月,其他人工智能实验室才刚刚获得自己的GPT-4级别模型。这意味着,所有研究人员现在才开始让当前一代模型进行自我对弈(看起来他们中的某些人可能已经成功了)。因此,虽然到目前为止,我们还没有公开证据表明合成数据取得了大规模成功,但这并不意味着它不可能成功。
毕竟,当你的基础模型足够强大,至少能在某些情况下得到正确答案时,强化学习才会更加可行(现在在100次尝试中,模型可以完成一次复杂的数学证明所需的思考过程,或者编写500行代码,以完成一个完整的pull request请求,这时候你可以对其进行奖励)。这样一开始1/100的成功率,可能逐渐增加到10/100,然后变成了90/100。成功率提升以后,就可以开始尝试更具挑战性的任务,比如处理1000行PR请求。随着训练的深入,基础模型有时不仅能够成功完成任务,还能够在失败时进行自我评价和纠正等。
事实上,合成数据引导训练在某种程度上与人类进化相似。最初,我们的灵长类祖先几乎没有表现出能够迅速洞察和应用新见解的能力。然而,人类发展出语言后,就迅速出现了基因/文化共进化现象,这与LLM的合成数据/自我对弈循环非常相似。在这个过程中,模型变得更加智能,以更好地理解相似副本的复杂符号输出。
自我对弈并不需要模型完美判断自己的推理过程。比起从头开始推理,它们只需要擅长判断自己的推理过程即可。(这显然已经成为了事实,可参考宪章AI(Constitutional AI)或简单使用GPT几分钟,你就会发现模型似乎更擅长解释用户所写内容的问题,而不擅长独立得出正确答案[4]。
我所接触的大型人工智能实验室的研究人员几乎都对自我对弈充满信心,但由于涉及保密问题,他们不能详细透露具体细节,只是提到在这个领域有很多可尝试的可能性。正如Dario Amodei (Anthropic首席执行官) 在我的播客中提到:
Dwarkesh Patel:你提到数据可能不会成为限制因素,为什么?
Dario Amodei:原因有很多,出于多方面考虑,我无法在此展开详细讨论,但世界上有多种数据源,生成数据的方法也很多。因此我认为数据不会成为阻碍。
相反,如果数据是瓶颈更好,但它不是。
反方:
宪章AI、RLHF和其他强化学习/自我对弈设置十分擅长挖掘模型的潜在能力(或在能力不足时将其抑制),但目前还没有人证明真正能够通过RL增强模型的基本能力。
如果某种自我对弈或合成数据的方法无法奏效,那就太糟糕了——除了数据瓶颈外别无选择。新架构几乎不太可能解决数据瓶颈问题。要解决当前问题,需要在样本效率上取得巨大突破,这一突破要比从LSTM(长短时记忆网络)到Transformer的跃迁更大。LSTM早在90年代就已经问世,在过去的20多年里,深度学习领域已经攻克了许多相对容易解决的问题,而我们需要在此取得更大的成就。
从那些在情感或利益驱使下希望看到LLM扩展的人那里得到的感觉,并不能代替我们完全缺乏证据表明强化学习能解决数据不足的问题。
进一步来说,语言大模型需要大量数据,但其表现出来的推理能力却十分平庸,这表明语言大模型的泛化能力可能存在问题。如果这些模型无法利用人类在20000年间积累的数据达到接近人类水平的性能表现,那么即使20亿年的数据对它们来说也可能不够。毕竟无论我们往飞机里添加多少喷气燃料,也无法让它到达月球。
2
目前为止,扩展是否依然有效?
正方:
这是毫无疑问的,因为模型在性能基准上的表现已经连续提升了8个数量级。即使在计算资源增加了百万倍的情况下,模型性能的损失也可以精确到小数点后的多位数字。
GPT-4的技术报告指出,他们能从使用相同方法训练的模型中预测出最终的GPT-4模型的性能,这些模型使用的计算资源最多可比GPT-4少10000倍。
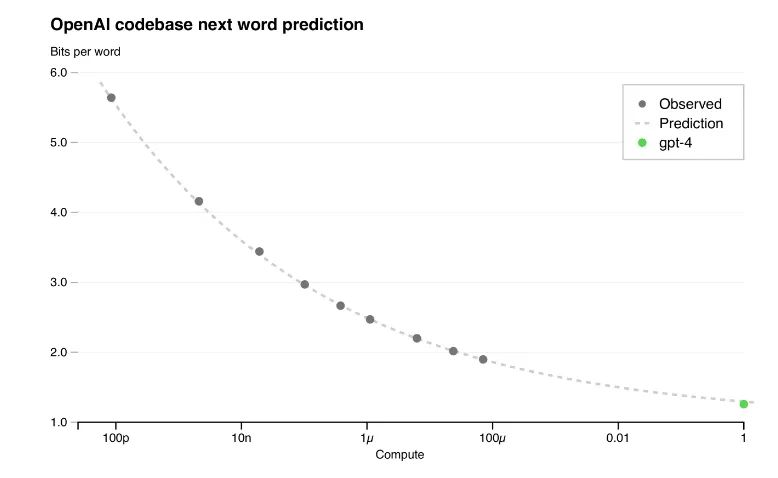
我们应该乐观地看待问题,过去连续8个数量级的成功也将在未来8个数量级上持续下去。进一步扩大8个数量级(或者考虑到算法和硬件进步带来的免费性能提升带来的任何相当于8个数量级的性能扩展)所能实现的性能很可能让模型具备足够的能力来加速人工智能研究。
反方:
实际上,我们并不是很关心模型在预测下一个词元上的表现。模型已经在这个损失函数上取得了超越人类的性能表现。我们想要弄清楚的是,这些在下一个词元预测任务上的性能提升是否意味着模型在泛化方面取得了真正的进展。
正方:
随着模型的扩展,在MMLU、BIG-bench和HumanEval等基准测试中,模型在各种任务中表现出了持续可靠的性能提升。
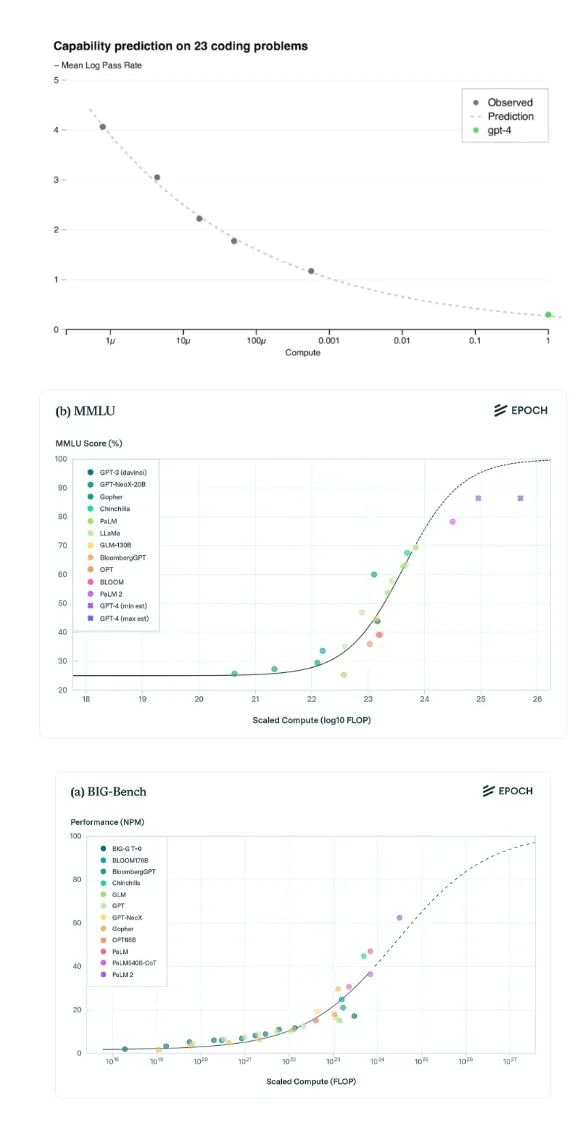
反方:
但查看MMLU和BigBench问题的随机样本,我们会发现这些样本几乎全是谷歌搜索首页的结果,这表明这些任务更像是在考察模型的记忆能力而非智能程度。下面是我从MMLU随机挑选的一些问题(都是多项选择题,模型只需从四个选项中选择正确答案):
问:根据Baier的理论,评估一个行为是否在道德上可接受的第二步是什么?
答:禁止该行为的道德准则是否本身就是一个真正的道德规则。
问:对于自发过程,始终成立的是哪一项?
答:系统与周围环境的总熵增加。
问:比尔·克林顿出生时的美国总统是谁?
答:哈里·杜鲁门
一个在充满各种随机事实的互联网文本上训练的模型偶然记住了许多随机事实,这为什么令人印象深刻?为什么这不能表明模型具有某种程度的智能和创造力?
即使在这些人为设计的、正交的基准测试中,模型的性能提升似乎也开始逐渐趋于平稳。据估计,谷歌新模型Gemini Ultra的计算资源几乎是GPT-4的5倍,但在MMLU、BIG-bench等其他标准基准测试上,Gemini Ultra的性能却几乎与GPT-4相当。
一般来说,常见基准测试并不能很好地评估模型在长期任务上的性能表现(例如,你能在一个月内完成一项任务吗?),而在这方面,通过下一个词元预测训练的语言大模型几乎没有足够的有效数据点进行学习。通过分析它们在SWE-bench上的表现(该基准测试衡量LLM是否能够自主完成pull request),可以看出它们在长期任务上整合复杂信息的能力相当糟糕。具体来说,GPT-4完成了1.7%,Claude 2的表现稍好一些,完成了4.8%。
我们似乎有两种基准测试标准:
第一类测试包括MMLU、BIG-bench和HumanEval,它们主要衡量模型的记忆、召回和插值能力。这类基准测试显示模型已经具备了能够匹敌甚至超越普通人类水平的性能。但这类基准测试并不能很好地测试模型的智能水平,因为目前即使是规模最大的模型也远远不及人类聪明。
第二类基准测试包括SWE-bench和ARC,它们真正衡量了模型在长时间跨度或复杂抽象环境中自主解决问题的能力。然而,这些模型在这类任务中的表现并不出色。
我们应该如何看待这样一个模型呢?这个模型在经过相当于2万年人类输入的训练之后,却仍然无法理解类似于“如果汤姆·克鲁斯的母亲是玛丽·李·菲佛,那么玛丽·李·菲佛的儿子就是汤姆·克鲁斯”等逻辑关系,或者我们应该如何看待一个回答严重依赖提问方式和顺序的模型呢?
因此,我认为讨论扩展是否会继续奏效等问题没有意义,因为我们甚至没有证据可以表明目前的扩展是有效的。
正方:
Gemini Ultra的性能发展不会停滞,相反,它会继续取得进展。GPT-4明显已经成功反驳了那些由怀疑者预先提出的关于连接主义和深度学习的批评[5]。相比GPT-4,Gemini的性能表现更可能是谷歌尚未完全赶上OpenAI在算法方面的进展所致。
如果在深度学习和LLM之间存在某种根本的硬性限制,我们难道不应该在它们发展出常识、早期推理和跨抽象思考能力之前就注意到了吗?我们有什么理由认为某些顽固限制只存在于中等推理和高级推理之间呢?
相对于GPT-3,GPT-4的性能扩展了100倍。听起来差距很大,但考虑到我们向这些模型投入的额外扩展,这一性能扩展其实并不大。只需花费不到1%的全球GDP(注:根据去年IMF公布的数据显示,2023年全球GDP总规模预计将达到99.67万亿美元。),我们就可以将GPT-4的规模进一步扩大10000倍(即达到GPT-6的水平)。而这还未考虑到预训练计算效率的提升(如MoE、flash attention等),新的后训练方法(RLAI,对思维链进行微调、自我对弈等),以及硬件改进等因素的影响。根据以往经验,以上每一项都为性能提升贡献了很多倍的量级。如果将这些因素综合起来,你就可能凭借全球1%的GDP构建一个GPT-8级别的模型。
为了解人类社会愿意在新的通用技术上投入多少资金,以下信息可供参考:
1847年是英国铁路投资的巅峰时期,其GDP占比高达7%。
“1996年《电信法案》生效后的五年间,电信公司获得了超5000亿美元(相当于如今的1万亿美元)的投资,用于铺设光纤电缆、添置新交换机以及架设无线网络。”
虽然GPT-8(即性能扩大100,000,000倍的GPT-4)可能只会略优于GPT-4,但这种期望过于悲观,因为我们已经看到模型能够在远小于这一规模的扩展中学会如何思考和理解世界。
接下来的情节就可以预知了:数百万个GPT-8的副本编写kernel改进,以找到更好的超参数,为自己提供大量高质量的反馈进行微调等等。这大大降低了开发GPT-9的成本和难度……最终将这一趋势推向奇点。
3
模型是否真正理解世界?
正方:
微软在其研究论文 Sparks of AGI 中提出了一个惊人发现:他们发现GPT-4能够编写LaTex代码绘制独角兽。对于这样的事情,我们已经司空见惯了,所以不会深思这一现象背后的含义。假设在LaTex中绘制动物图像并不是GPT-4训练语料库的一部分,然而,GPT-4已经建立起了独角兽的内部表征,并能够利用其在LaTex编程上的熟练程度来描绘它仅以语言形式遇到过的概念。显然,如果缺乏世界模型,GPT-4不可能具备这样的能力(如果它不理解独角兽是什么样子,它怎么能知道如何在LaTex中描绘独角兽呢)[6]。
要预测下一个词元,语言大模型必须自学世界的全部规律,以预测下一个词元。例如,预测书籍《自私的基因》(The Selfish Gene)需要理解基因在进化过程中的中心作用,预测短篇小说则需要理解人物心理等等。
通过代码训练LLM,能使其获得更好的语言推理性能。这一事实实在令人惊叹。这表明通过阅读大量代码,模型获得了更深刻的一般性思考能力——这不仅表示语言和代码之间存在一些共享的逻辑结构,还表明无监督梯度下降可以提取这种结构,并利用它更好地进行推理。
梯度下降试图找到最高效的数据压缩方式。最有效的压缩也是最深刻和最强大的。例如,对一本物理教科书的最有效压缩,就是能够帮助你预测书中被截断的论证将如何继续展开,这是一种对基础科学解释的深刻内化理解。
反方:
智能包括(除其他方面外)压缩能力。但压缩本身并不等同于智能。爱因斯坦之所以聪明,是因为他能提出相对论,但在我看来爱因斯坦+相对论并不能构成有意义的更智能的系统,就这相当于说柏拉图是一个笨蛋,因为他不理解现代生物学或物理学,这是毫无意义的。
所以,如果语言大模型只是由另一个过程(随机梯度下降)产生的压缩,那么我不知道这如何能告诉我们关于LLM自身进行压缩的能力(因此,也无法获得关于LLM智能的任何信息)[7]。
正方:
尽管我们没有一个严密的理论解释,说明为什么扩展必然会继续发挥作用,但这并不妨碍扩展将继续发挥作用。蒸汽机发明一个世纪后,我们才形成了对热力学的全面理解。技术史上的常见模式是发明先于理论,在我看来智能也是如此。
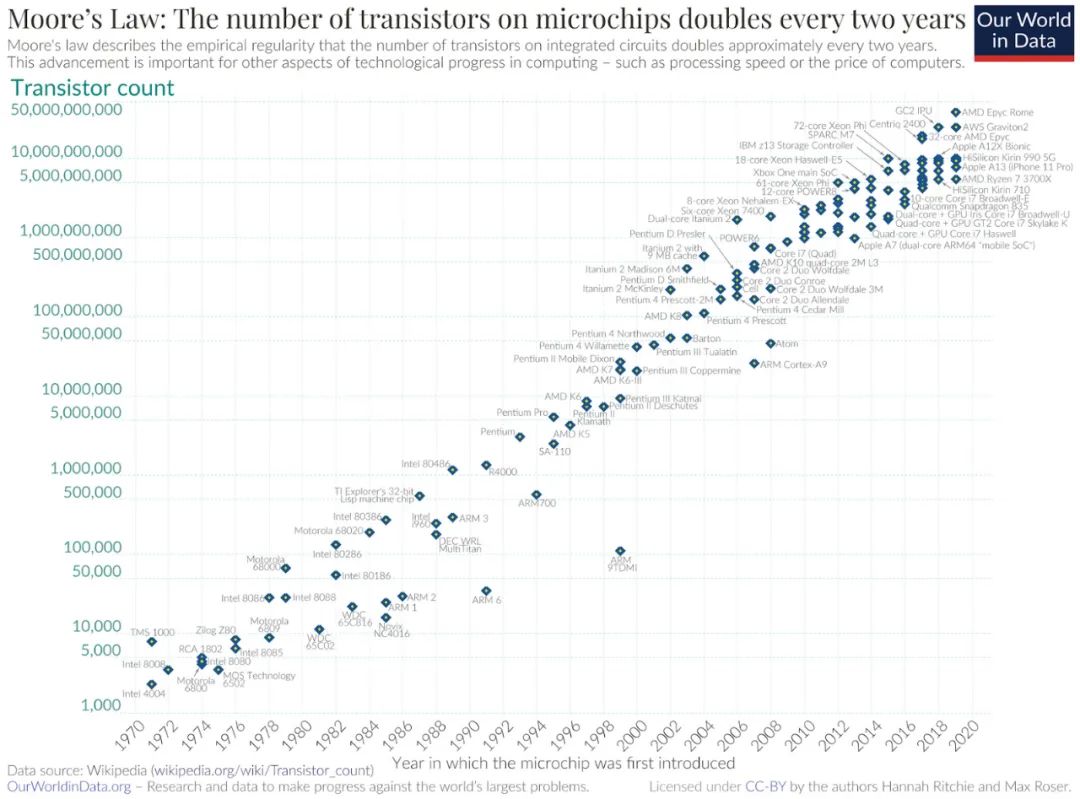
并不存在某种物理定律规定摩尔定律必须继续存在。事实上,总会出现新的实际障碍来预示摩尔定律的终结。然而,每隔几年,台积电、英特尔、AMD等的研究人员都能找到解决这些问题的方法,为这几十年摩尔定律的趋势增添新的生机。
你可以进行关于计算和数据瓶颈、智能真实本质以及基准的脆弱性等一系列复杂的思维活动。或者也可以直接看看下图中的曲线。
4
结论
两方的争论就此作罢。以下是我的个人观点。
在过去几年里,如果你相信扩展的作用,那么我们所见的进展会合理的多。有一种说法是,GPT-4的惊人性能可以解释为某种永远无法泛化的术语库或查询表。但这是怀疑者事先没有提到的说法。
举例来说,原本我要为反方提供的有力论据之一是,语言大模型至今未建立任何新连接,也没有得出任何新发现。如果一个人能够记住语言大模型所记住的海量内容,就算他本身很愚蠢,也可以做到这一点。说实话,我认为这是最令人信服的反方观点之一,很多人也这样认为。然而,就在几天前,谷歌宣布其FunSearch系统有了新的数学发现[8]。如果你赞同反方观点,可能已经一次又一次地经历过这种情况。
而对于坚定的信仰者(信仰技术进步)来说,像Ilya、Dario、Gwern等人早在12年前就大致阐述了由于规模扩展而导致的缓慢发展。
一定程度的规模扩展可以带领我们实现变革性的人工智能,这一点似乎相当明确。也就是说,如果你能够在这些规模曲线上实现不可降低的损失,就已经创造了一个足够智能的AI,可以自动化大部分的认知劳动(包括制造更智能的AI所需的劳动)。
但生活中大部分事都比理论更加困难,且许多在理论上可能的事会因为种种原因难以实现(如核聚变能源、飞行汽车、纳米技术等)。如果自我对弈/合成数据行不通,那么模型看起来就很失败,你永远不可能接近那种形而上的不可降低的损失。此外,期望规模扩展继续发挥作用的理论依据很模糊,而规模效应似乎会导致在基准测试中表现更好的性能,这些基准测试的普适性也存在争议。
因此,我个人初步的判断是:通过扩展+算法进步+硬件进步,有70%的可能性是我们将在2040年之前实现通用人工智能(AGI);30%的可能性是怀疑者是对的,语言大模型及其范畴内的任何产物都是失败的。
我可能遗漏了一些重要证据——人工智能实验室并未发布那么多研究,因为任何有关“人工智能科学”的见解都可能会泄露与构建AGI相关的想法。我有一位朋友是其中一个实验室的研究员,他说怀念本科时期阅读一堆论文来放松的习惯。而如今,几乎没有值得阅读的东西发表。因此,我不了解的证据可能会影响这一判断,并缩短上述的时间线。
5
附录
以下是一些补充。对于这些话题,我自认为理解的还不够透彻,没有完全理解它们对扩展的实际影响。
模型是否会具备基于洞察力的学习能力?
正方:
在更大的规模下,模型将自然地发展出更高效的元学习方法——只有在拥有大规模参数化模型的情况下,并且已经训练到对数据严重过拟合的程度,才会产生“领悟(grokking)”能力。领悟似乎与我们学习的方式非常相似。我们通过直觉和心智模型来归类新信息。随着时间的推移和新的观察,这些心智模型本身也会发生变化。在如此丰富多样的数据上进行梯度下降将选择最通用和最具外推能力的线路。因此我们获得了领悟——并最终获得基于洞察力的学习能力。
反方:
神经网络拥有“领悟”能力,但其效率远不及人类实际融合新的解释性见解的方式。比如,当你教一个孩子太阳在太阳系的中心时,会立即改变他对夜空的理解。但是,你不能简单地将哥白尼日心说的一份副本输入到一个未经过天文学数据训练的模型中,然后期望它会立即将这一见解整合到所有相关的未来输出中。令人费解的是,模型必须在许多不同的上下文中多次重复接收信息,才能完全理解基本概念。
不仅模型从未展示过具有洞察力的学习能力,而且我也不明白通过使用梯度下降训练神经网络的方式,这样的学习是否能够实现——我们通过每个示例给予一些微妙的暗示,希望足够多的暗示会慢慢将其引导至正确的方向。基于洞察力的学习就像是瞬间从海平面迅速跃升至珠穆朗玛峰峰顶。
灵长类进化是否证实了规模扩展?
正方:
我相信你可以找到许多在黑猩猩认知中远比逆转诅咒更加令人尴尬的弱点。这并不意味着灵长类大脑存在一些根本限制,这些限制不能通过3倍规模扩展和一些微调来解决。
事实上,正如Suzana Herculano-Houzel所展示的那样,人类大脑拥有与你期望的一个具有人类脑质量的按规模扩展的灵长类大脑一样多的神经元。啮齿动物和昆虫食性动物大脑的规模扩展则差得多。比如在啮齿目和食虫目动物中,大脑更大的物种的神经元数量远远少于仅根据其脑质量所期望的数量。
这表明与其他物种的大脑相比,灵长类动物存在一些真正可扩展的神经结构,类似于Transformer相比LSTM和RNN具有更好的扩展曲线(https://ar5iv.labs.arxiv.org/html/2001.08361)。进化在设计灵长类大脑时学到(或者至少是偶然发现)了苦涩的教训(http://www.incompleteideas.net/IncIdeas/BitterLesson.html),而灵长类动物所竞争的生态位强烈地奖励智力的边际增长(你必须理解来自你的双眼视觉、能使用工具的手,以及其他可以与你交谈的聪明猴子的所有这些数据)。
感谢Chris Painter,James Bradburry,Kipply,Jamie Sevilla,Tamay Besiroglu,Matthew Barnett,Agustin Lebron,Anil Varanasi和Sholto Douglas的评论与讨论。
注释
[1]这似乎是你需要的计算量,以便扩展当前的模型,使其足够优秀,能够生成与人类所写科学论文长度相媲美的输出。
[2]假设采用Chinchilla最优的扩展方式(这大致意味着为了高效地扩展计算,额外计算的一半应来自增加数据,一半应来自增加参数)。你可以尝试以非最优的方式训练Chinchilla,但这只能帮助你弥补轻微的数据不足,而不能弥补5 OOM的不足。这里的“5 OOM”指的是"Five Orders of Magnitude",即五个数量级的差距。
[3]支持者的观点(补充):相对于人类,LLM的样本利用效率确实较低(GPT-4看到的数据远远超过人类从出生到成年的数据量,但它比我们聪明得多)。但我们没有考虑已编码到我们基因组中的知识——这是通过数亿年的进化训练出的微小压缩的提炼,其中包含的数据比GPT-4曾经见过的数据还要多得多。
[4]实际上,对于这种自我对弈循环,评估者也许最好是智力与GPT-4相当的模型。在生成对抗网络(GAN)中,如果鉴别器比生成器强大得多,那么它将停止向生成器提供任何反馈,因为它无法提供有指导意义但不完美的反馈信号。
[5] 例如,Pinker在这里列出了一系列连接主义架构(如神经网络)在试图表示语言规则时必须屈服的限制。乍看之下(我强调仅仅是乍看之下),GPT-4摆脱了所有这些所谓的限制。Pinker也指出了ChatGPT常识的匮乏,而在GPT-4发布后的短短一个月内这一问题就被解决了。
[6]支持者的观点(补充):在我们有能力探究Transformer内部的玩具设置(toy settings)中,实际上可以看到它们开发的世界模型。研究人员训练了一个Transformer来预测名为奥赛罗(Othello)的象棋类棋盘游戏的下一步动作。模型完全没有接收关于游戏规则或棋盘结构的任何指令,只得到一堆游戏记录。所以你所做的就是给一个原始Transformer喂一堆游戏记录序列,比如“E3 D3...”。研究人员发现,通过阅读模型在接受游戏记录后的权重,你可以重构出棋盘的状态。这证明神经网络模型只需阅读一些原始记录,就能得出对该游戏的强大内部表征。
[7]反对者的观点(补充):智能=压缩这一框架似乎也不够细致,无法明显区分随机梯度下降找到语义规律,以及爱因斯坦找到相对论正确方程的差异。我不认为随机梯度下降能够找到后者相对论那样的“压缩”,也不可能以爱因斯坦那样聪明的方式变得聪明。
[8]你可以争辩说,针对数学和编程的FunSearch设置具有严密的反馈循环和具体的获胜条件,而其他领域不太可能享有这些条件,但这更多是我试图指出的复杂的思维活动。
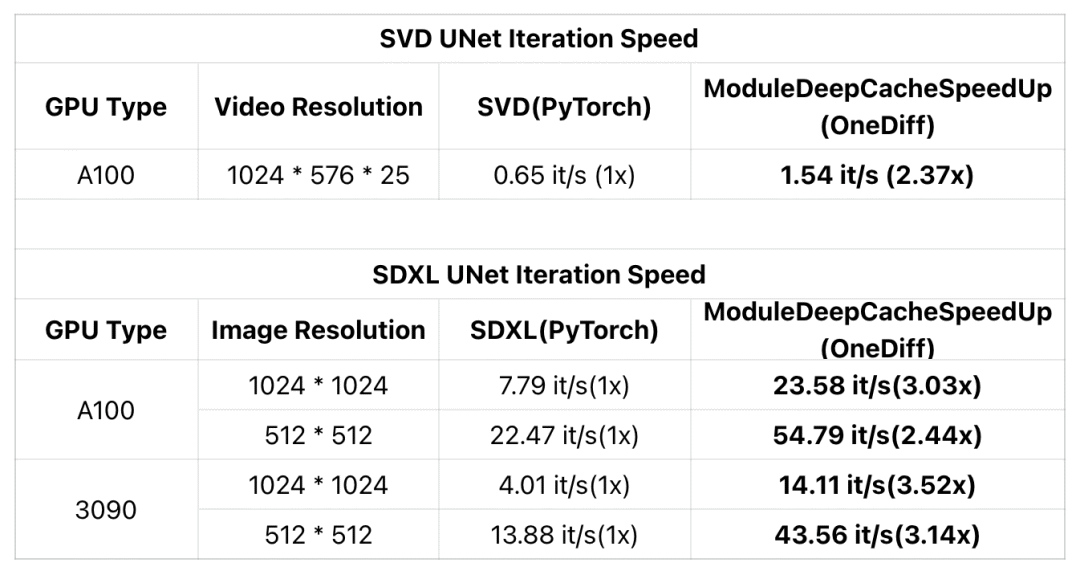
近期,DeepCache为加速扩散模型提供了一种新的免训练、几乎无损的范式。现在,OneDiff引入了一个名为ModuleDeepCacheSpeedup的新ComfyUI Node(已编译的DeepCache模块), 让SDXL在RTX 3090上的迭代速度提升3.5倍,在A100上提升3倍。
此外,OneDiff的ModuleDeepCacheSpeedup还支持SVD (Stable Video Diffusion)加速,确保视频质量几乎无损,并在A100上将迭代速度提高了2倍以上。
示例:
1. https://github.com/Oneflow-Inc/onediff/pull/426
2. https://github.com/Oneflow-Inc/onediff/pull/438
使用指南:https://github.com/Oneflow-Inc/onediff/tree/main/onediff_comfy_nodes#installation-guide
试用OneFlow: github.com/Oneflow-Inc/oneflow/

本文分享自微信公众号 - OneFlow(OneFlowTechnology)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。