在本文中,我们深入探讨了图像分类技术的发展历程、核心技术、实际代码实现以及通过MNIST和CIFAR-10数据集的案例实战。文章不仅提供了技术细节和实际操作的指南,还展望了图像分类技术未来的发展趋势和挑战。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
一、:图像分类的历史与进展

历史回顾
图像分类,作为计算机视觉的一个基础而关键的领域,其历史可以追溯到20世纪60年代。早期,图像分类的方法主要基于简单的图像处理技术,如边缘检测和颜色分析。这些方法依赖于手工提取的特征和线性分类器,如支持向量机(SVM)和决策树。这一时期,虽然技术相对原始,但为后来的发展奠定了基础。
随着时间的推移,2000年代初,随着机器学习的兴起,图像分类开始采用更复杂的特征提取方法,例如SIFT(尺度不变特征变换)和HOG(方向梯度直方图)。这些方法在一定程度上提高了分类的准确性,但仍受限于手工特征提取的局限性。
深度学习的革命
深度学习的出现,特别是卷积神经网络(CNN)的应用,彻底改变了图像分类的领域。2012年,AlexNet在ImageNet挑战中取得突破性成绩,标志着深度学习时代的来临。自此,CNN成为图像分类的主流方法。
之后,各种更加复杂和高效的CNN架构相继出现,如VGG、GoogLeNet、ResNet等。这些网络通过更深的层次、残差连接和注意力机制等创新,大幅提高了图像分类的准确率。
当前趋势
当前,图像分类技术正朝着更加自动化和智能化的方向发展。一方面,通过自动化的神经网络架构搜索(NAS)技术,研究者们正在探索更优的网络结构。另一方面,随着大数据和计算能力的增强,更大规模的数据集和模型正在被开发,进一步推动着图像分类技术的进步。
同时,为了解决深度学习模型的计算成本高、对数据量要求大等问题,轻量级模型和少样本学习也成为研究的热点。这些技术旨在让图像分类模型更加高效,适用于资源受限的环境。
未来展望
未来,我们可以预见,随着技术的不断进步,图像分类将更加精准、快速。结合其他AI技术,如自然语言处理和强化学习,图像分类有望实现更复杂的应用,如情感分析、自动化标注等。此外,随着隐私保护和伦理问题的日益重要,如何在保护用户隐私的前提下进行高效的图像分类,也将是未来研究的重点。
二:核心技术解析
图像预处理
图像预处理是图像分类的首要步骤,关乎模型性能的基石。它涉及的基本操作包括图像的缩放、裁剪、旋转和翻转。例如,考虑一个用于识别道路交通标志的分类系统。在这种情况下,不同尺寸、角度的交通标志需要被标准化,以确保模型能够有效地从中提取特征。
数据增强则是预处理的进阶版,通过随机变换扩展数据集的多样性。在现实世界中,我们可能遇到由于光照、天气或遮挡导致的图像变化,因此,通过模拟这些条件的变化,可以提高模型对新场景的适应性。例如,在处理户外摄像头捕获的图像时,模型需要能够在不同光照条件下准确分类。
神经网络基础
神经网络的构建是图像分类技术的核心。一个基础的神经网络由输入层、隐藏层和输出层组成。以人脸识别为例,网络需要从输入的像素中学习到与人脸相关的复杂特征。这个过程涉及权重和偏差的调整,通过反向传播算法进行优化。
卷积神经网络(CNN)
CNN是图像分类的关键。它通过卷积层、激活函数、池化层和全连接层的结合,有效地提取图像中的层次特征。以识别猫和狗为例,初级卷积层可能只识别边缘和简单纹理,而更深层次的卷积层能识别更复杂的特征,如面部结构或毛皮图案。
主流CNN架构,如VGG和ResNet,通过深层网络和残差连接,提高了图像分类的准确性和效率。以VGG为例,其通过多个连续的卷积层深化网络,有效地学习复杂图像特征;而ResNet则通过引入残差连接,解决了深层网络中的梯度消失问题。
深度学习框架
深度学习框架,如PyTorch,提供了构建和训练神经网络所需的工具和库。PyTorch以其动态计算图和易用性受到广泛欢迎。例如,在开发一个用于医学图像分类的模型时,PyTorch可以方便地实现模型的快速原型设计和调整。
选择合适的框架需要考虑多个因素,包括社区支持、文档质量、和易用性。PyTorch因其丰富的社区资源和直观的API,成为了许多研究者和开发者的首选。
第三部分:核心代码与实现
在这一部分,我们将通过PyTorch实现一个简单的图像分类模型。以一个经典的场景为例:使用MNIST手写数字数据集进行分类。MNIST数据集包含了0到9的手写数字图像,我们的目标是构建一个模型,能够准确识别这些数字。
环境搭建
首先,确保安装了Python和PyTorch。可以通过访问PyTorch的官方网站下载安装。
# 引入必要的库
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
数据加载和预处理
使用PyTorch提供的torchvision库来加载和预处理MNIST数据集。
# 数据预处理:转换为Tensor,并且标准化
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))])
# 训练数据集
trainset = torchvision.datasets.MNIST(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
# 测试数据集
testset = torchvision.datasets.MNIST(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
# 类别
classes = ('0', '1', '2', '3', '4', '5', '6', '7', '8', '9')
构建CNN模型
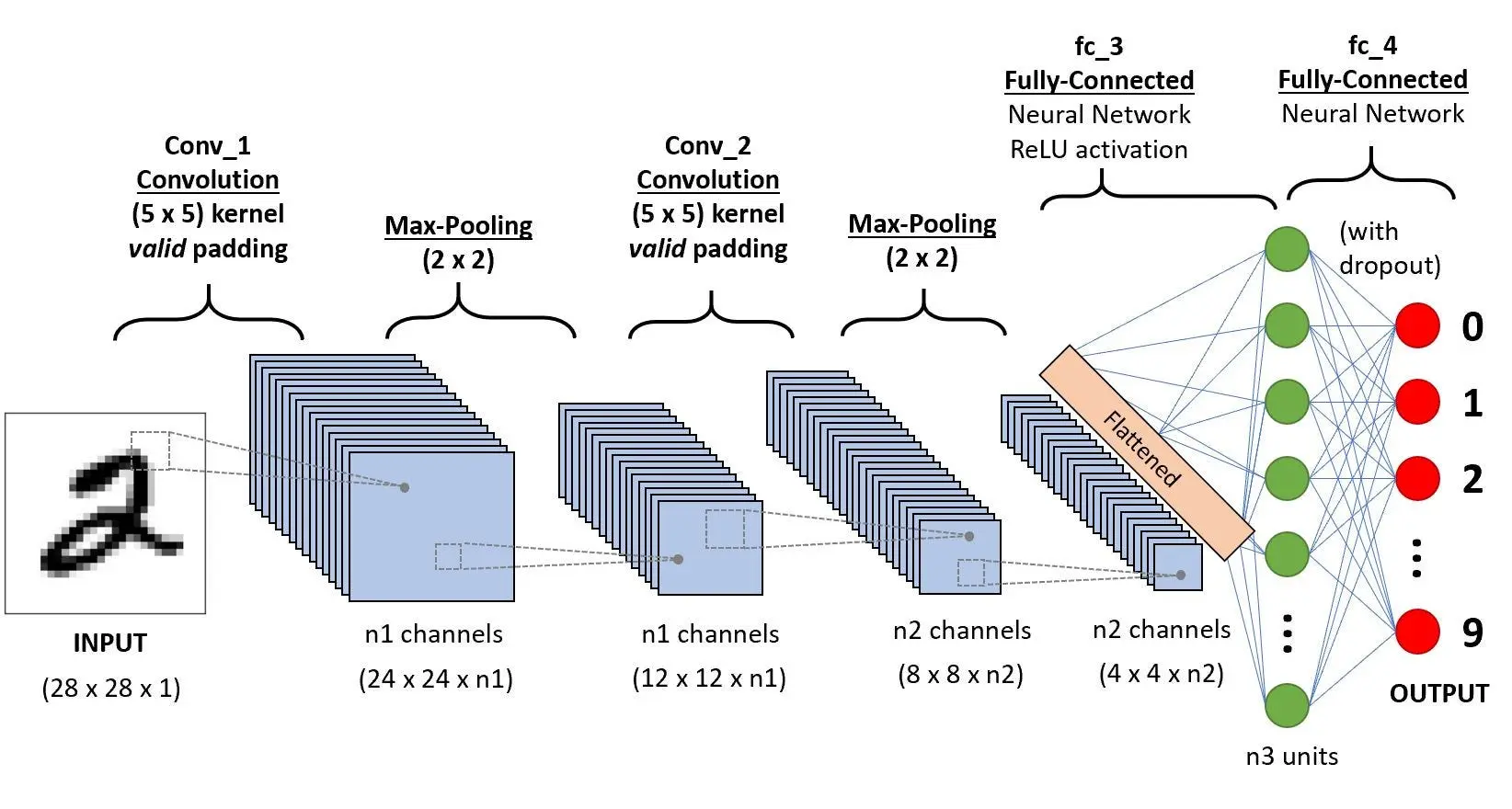
定义一个简单的卷积神经网络。网络包含两个卷积层和两个全连接层。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 第一个卷积层
self.conv1 = nn.Conv2d(1, 6, 5)
# 第二个卷积层
self.conv2 = nn.Conv2d(6, 16, 5)
# 全连接层:3层,最后一层有10个输出(对应10个类别)
self.fc1 = nn.Linear(16 * 4 * 4, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# 通过第一个卷积层后,应用ReLU激活函数和池化
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# 通过第二个卷积层
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
# 展平所有维度,除了批处理维度
x = torch.flatten(x, 1)
# 通过全连接层
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
模型训练
定义损失函数和优化器,然后进行模型训练。
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(2): # 多次循环遍历数据集
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# 获取输入;数据是一个[输入, 标签]列表
inputs, labels = data
# 梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 打印统计信息
running_loss += loss.item()
if i % 2000 == 1999: # 每2000批数据打印一次
print('[%d, %5d] loss: %.3f' %
(epoch + 1
, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
模型测试
最后,使用测试数据集来检查网络的性能。
correct = 0
total = 0
# 测试时不需要计算梯度
with torch.no_grad():
for data in testloader:
images, labels = data
# 计算图片在网络中的输出
outputs = net(images)
# 获取最大可能性的分类
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
这个简单的CNN模型虽然基础,但足以作为图像分类入门的一个良好示例。通过这个过程,我们可以理解如何使用PyTorch构建和训练一个图像分类模型,并对其性能进行测试。
四:案例实战
在本部分,我们将通过两个实战案例来展示图像分类的应用。首先,我们将使用MNIST数据集来构建一个基本的手写数字识别模型。其次,我们将使用更复杂的CIFAR-10数据集来构建一个能够识别不同物体(如汽车、鸟等)的模型。 
实战案例:MNIST手写数字识别
MNIST数据集是机器学习中最常用的数据集之一,包含了大量的手写数字图片。
数据加载和预处理
我们将使用PyTorch提供的工具来加载MNIST数据集,并对其进行预处理。
# 引入必要的库
import torch
import torchvision
import torchvision.transforms as transforms
# 数据预处理
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))])
# 加载MNIST数据集
trainset = torchvision.datasets.MNIST(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64,
shuffle=True)
testset = torchvision.datasets.MNIST(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=64,
shuffle=False)
模型构建
接下来,我们将构建一个简单的CNN模型来进行分类。
# 引入必要的库
import torch.nn as nn
import torch.nn.functional as F
# 定义CNN模型
class MNISTNet(nn.Module):
def __init__(self):
super(MNISTNet, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2(x), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x, dim=1)
net = MNISTNet()
训练和测试
我们将使用相同的训练和测试流程,如之前在核心代码与实现部分所述。
实战案例:CIFAR-10物体分类
CIFAR-10数据集包含10个类别的60000张32x32彩色图像。
数据加载和预处理
与MNIST类似,我们将加载和预处理CIFAR-10数据集。
# 数据预处理
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 加载CIFAR-10数据集
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64,
shuffle=True)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=64,
shuffle=False)
模型构建
CIFAR-10的模型需要处理更复杂的图像,因此我们将构建一个更深的网络。
# 定义CIFAR-10的CNN模型
class CIFAR10Net(nn.Module):
# ...(类似的网络结构,但适用于更复杂的图像)
net = CIFAR10Net()
训练和测试
同样地,我们将训练并测试这个模型,观察其在CIFAR-10数据集上的性能。通过这两个案例,读者可以深入理解如何针对不同复杂度的图像分类问题构建、训练和测试模型。这不仅展示了理论知识的实际应用,也提供了一个实际操作的参考框架。
总结
通过本文的探索和实践,我们深入了解了图像分类在人工智能领域的核心技术和应用。从图像分类的历史发展到当今深度学习时代的最新进展,我们见证了技术的演变和创新。核心技术解析部分为我们揭示了图像预处理、神经网络基础、CNN架构以及深度学习框架的细节,而核心代码与实现部分则提供了这些概念在实际编程中的具体应用。
实战案例更是将理论与实践完美结合,通过MNIST和CIFAR-10数据集的应用,我们不仅学习了如何构建和优化模型,还体验了实际操作中的挑战和乐趣。这些案例不仅加深了我们对图像分类技术的理解,也为未来的研究和开发工作提供了宝贵的经验。
在技术领域,图像分类作为深度学习和计算机视觉的一个基础而重要的应用,其发展速度和广度预示着人工智能领域的未来趋势。随着技术的发展,我们可以预见到更加复杂和智能化的图像分类系统,这些系统不仅能够处理更高维度的数据,还能够在更多的应用场景中发挥作用,如自动驾驶、医疗诊断、安防监控等。此外,随着隐私保护和伦理问题的日益重要,未来的图像分类技术将更加注重数据安全和用户隐私,这将是一个新的挑战,也是一个新的发展方向。
最后,值得强调的是,无论技术如何进步,创新的思维和对基础知识的深入理解始终是推动科技发展的关键。正如本系列文章所展示的,通过深入探索和实践,我们可以更好地理解和利用现有的技术,同时为未来的创新奠定坚实的基础。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
Tauri v2 支持 Android 和 iOS,跨平台开发新选择 FastGateway:一个可以用于代替 Nginx 的网关 PostgreSQL 90% 的新代码仅由 50 人完成,拓数派荣占一席 联想 2024 年将发布全新 AI OS 操作系统 微软为 Windows 11 引入原生 Sudo 命令支持 Redox OS 计划移植更多 Linux 软件 10 年前的今天 —— Vue.js 正式问世 谷歌向 Rust 基金会捐赠 100 万美元,改进 Rust 与 C++ 的互操作性 曾被 Mozilla 放弃的 Web 引擎项目“Servo”在 2024 年迎来重生 Zig 编程语言 2024 年全新路线图发布如有帮助,请多关注 TeahLead KrisChang,10+年的互联网和人工智能从业经验,10年+技术和业务团队管理经验,同济软件工程本科,复旦工程管理硕士,阿里云认证云服务资深架构师,上亿营收AI产品业务负责人。