public static void main(String[] args) {
// TODO 自动生成的方法存根
String str = "abcaaaefdabbhg";
//count(str);
HashMap<String, Integer> map = new HashMap<String, Integer>();
map.put("语文", 1);
map.put("数学", 2);
map.put("英语", 3);
map.put("历史", 4);
map.put("政治", 5);
map.put("地理", 6);
map.put("生物", 7);
map.put("化学", 8);
map.put("是的", 1);
map.put("我玩的", 2);
map.put("我的", 3);
map.put("社区为", 4);
map.put("仍然", 5);
map.put("前期", 6);
map.put("已有", 7);
map.put("以让法", 8);
for (String key : map.keySet()) {
int value=map.get(key);
System.out.println(key+" "+value);
}
}
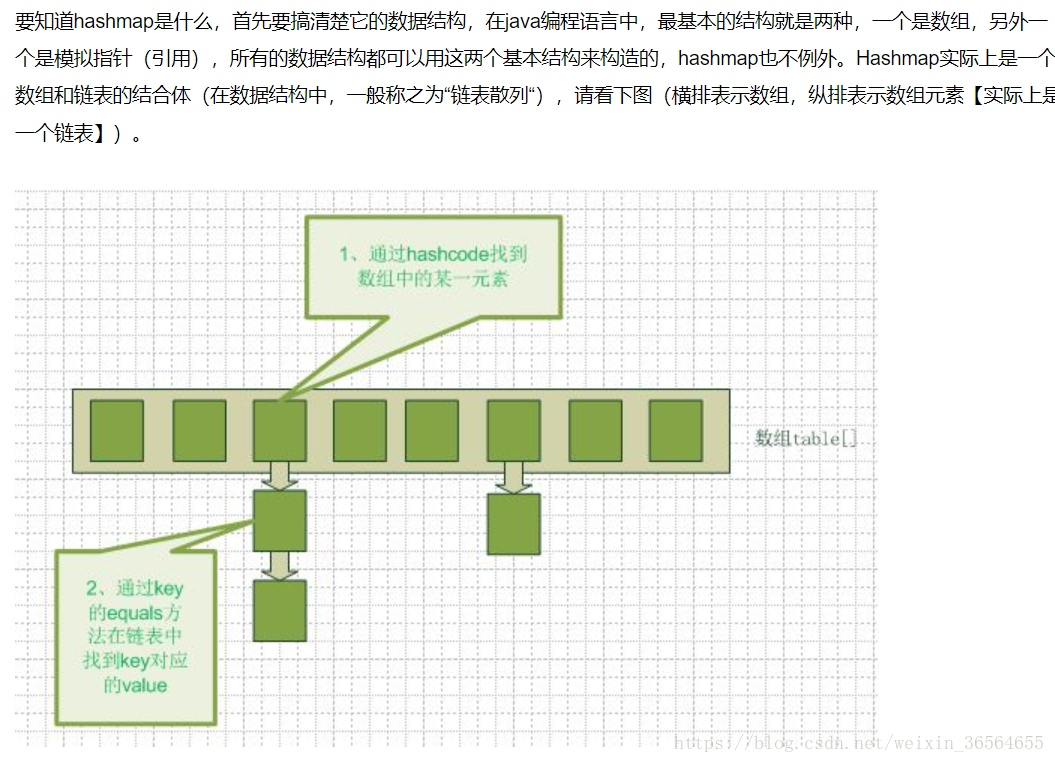
当我们往hashmap中put元素的时候,先根据key的hash值得到这个元素在数组中的位置(即下标),然后就可以把这个元素放到对应的位置中了。如果这个元素所在的位子上已经存放有其他元素了,那么在同一个位子上的元素将以链表的形式存放,新加入的放在链头,最先加入的放在链尾。从hashmap中get元素时,首先计算key的hashcode,找到数组中对应位置的某一元素,然后通过key的equals方法在对应位置的链表中找到需要的元素。从这里我们可以想象得到,如果每个位置上的链表只有一个元素,那么hashmap的get效率将是最高的,但是理想总是美好的,现实总是有困难需要我们去克服
put函数大致的思路为:
- 对key的hashCode()做hash,然后再计算要存储下标:i=(n-1)&hash
- 如果没碰撞直接放到bucket里;(table[i])
- 如果碰撞了,以链表的形式存在buckets后;
- 如果碰撞导致链表过长(大于等于TREEIFY_THRESHOLD),就把链表转换成红黑树;
- 如果节点已经存在就替换old value(保证key的唯一性)
- 如果bucket满了(超过load factor*current capacity),就要resize。