


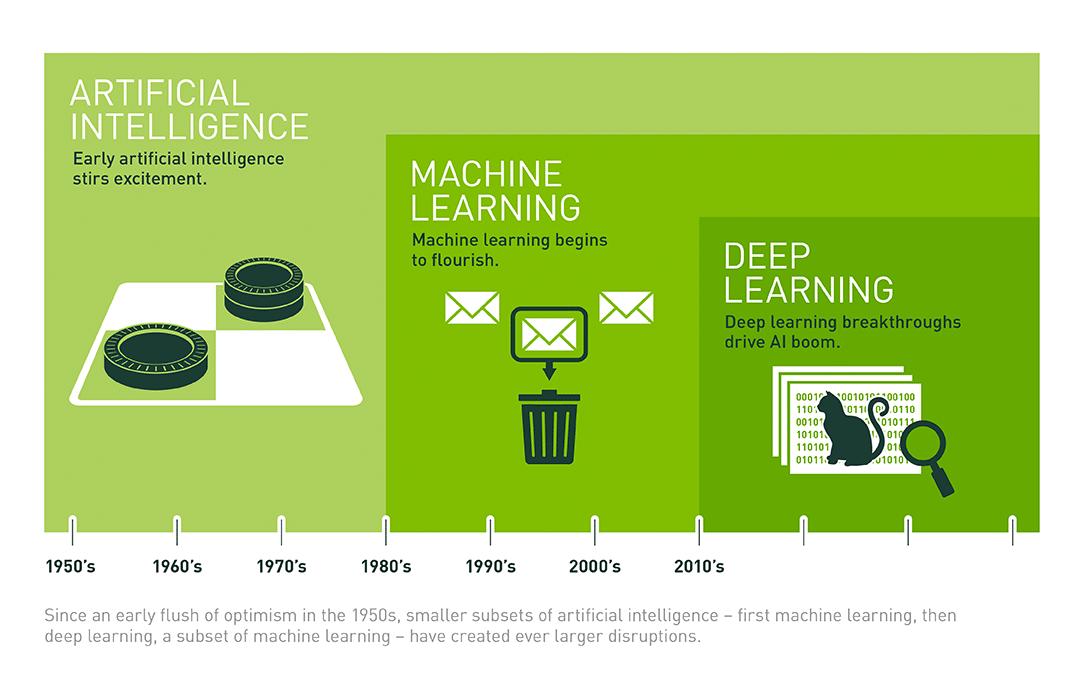
图1:人工智能(AI)、机器学习(ML)和深度学习(DL)之间的关系
机器学习算法有多种分类方法[2][3],从机器学习任务来分主要有分类、回归、聚类和降维等方法,本文从一个机器学习的经典任务“鸢尾花分类”为例,来介绍一些常见的数据分析方法和工具的使用。

图2:机器学习的多种分类方法

在使用算法之前,我们先用统计和可视化工具对数据进行初步分析,这样便于直观理解数据的统计值、分布和相关性等信息。
工具:pandas、seaborn
方法:描述性统计、数据分布、相关性分析等
目的:从统计和视觉角度分析数据的基本情况
▐ 数据集简介
鸢尾花包含很多种类,这个数据集包含 3 种:“山鸢尾”(Setosa),“杂色鸢尾”(Versicolor)和“维吉尼亚鸢尾”(Virginica)[1]。三种花在花萼(sepal)长度和宽度以及花瓣(petal)的长度和宽度上有非常明显的区别,详见下图所示:

图3:三种鸢尾花的花萼(sepal)以及花瓣(petal)的长度和宽度
这三个分类标签就是我们想要预测的分类,即因变量。其中,每个物种有50条数据,每条数据包含4个变量,我们把它称为自变量(或特征):花瓣长度、花瓣宽度、花萼长度、花萼宽度。花萼是由叶子演化而来,起到保护花蕾的作用。我们可以用pandas读取csv文件(读取为二维表格格式的DataFrame对象),然后看下前10条数据。
import pandas as pdiris = pd.read_csv('./iris.csv',names=['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'class'])print(iris.head(10))
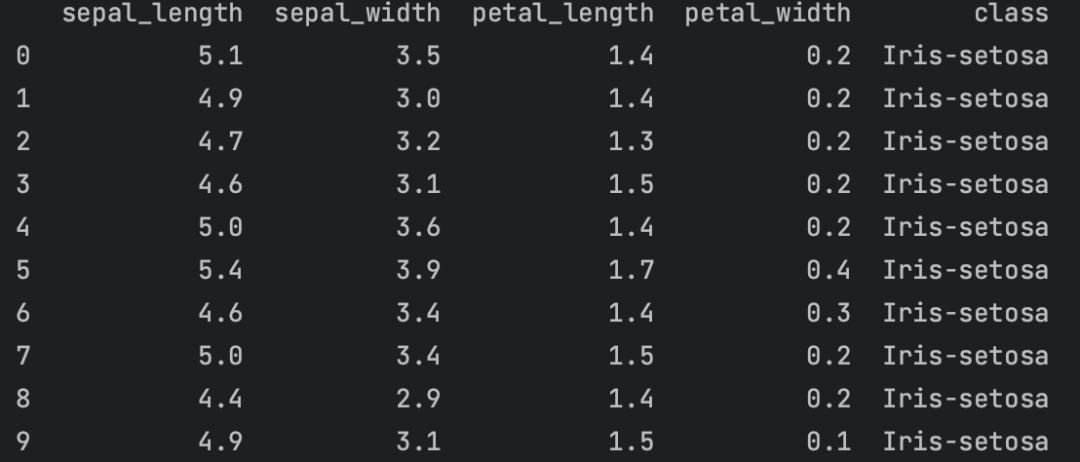
图4:鸢尾花数据集的前10条数据
可以用图形展示三个类别的数据(数据中0-50条,51~100条,101~150条是同一个类别未打散,正好可以看出三类数据的区别)。
iris.plot.line(stacked=False)
图5:三种类别鸢尾花的四个字段的真实值
使用pandas DataFrame的describe方法打印描述性统计信息。从中可以看出四个特征字段的各个统计值,如均值、方差、四分位数等。
iris.describe()
图6:鸢尾花数据集的描述性统计
结合numpy分组聚合方法打印不同鸢尾花类别的几个特征字段的均值。可以看出三类鸢尾花的花萼长宽、花瓣长宽等特征值有显著的区分。
import numpy as np# 读取csv略过print(iris.groupby(['class']).agg({'sepal_length': np.mean,'sepal_width': np.mean,'petal_length': np.mean,'petal_width': np.mean}))
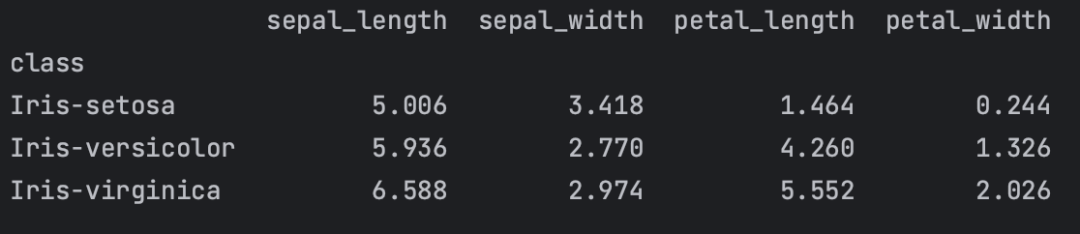
图7:三种类别鸢尾花的字段均值
▐ 数据分布
直方图
iris.plot(kind='hist', subplots=True, layout=(2, 2), figsize=(10, 10))
图8:鸢尾花四个属性的直方图(分箱频数)
核密度估计(KDE)
我们使用微分思想,将频率直方图的组距一步步减小,随着组距的减小,矩形宽度越来越小,因此,在极限情况下频率直方图就会变成一条曲线,而这条曲线即为概率密度曲线。核密度估计(kernel density estimation,简称 KDE)是一种用于估计这条曲线的概率密度函数(probability density function,PDF)的统计方法[14]。它通过对样本点周围使用内核函数(kernel function)加权平均来得到密度估计值。
核函数是一种用于估计概率密度函数的函数形式。通俗来说,核函数就是一个用来描述数据点附近密度的函数。核函数通常是一个关于距离的函数,它衡量了一个数据点附近的其他数据点对该位置的贡献。核密度估计的思想是将每个数据点作为中心,通过核函数来计算该位置附近的密度贡献值,然后将所有数据点的贡献值加起来得到整体的概率密度估计。常见的核函数有高斯核函数(也叫正态核函数)和Epanechnikov核函数。
通过概率密度曲线可以看出更细致的取值概率。
iris.plot(kind='kde')
图9:鸢尾花数据集四个变量的KDE曲线
当然,再加上各个鸢尾花类别,可以看2维KDE的分布。
'Iris-setosa']virginica = iris.loc[iris['class'] == 'Iris-virginica']versicolor = iris.loc[iris['class'] == 'Iris-versicolor']sns.kdeplot(x=setosa.sepal_width, y=setosa.sepal_length, shade=True, alpha=0.7, color='blue', linewidth=2.5)sns.kdeplot(x=virginica.sepal_width, y=virginica.sepal_length, shade=True, alpha=0.7, color='red', linewidth=2.5)sns.kdeplot(x=versicolor.sepal_width, y=versicolor.sepal_length, shade=True, alpha=0.7, color='green', linewidth=2.5)
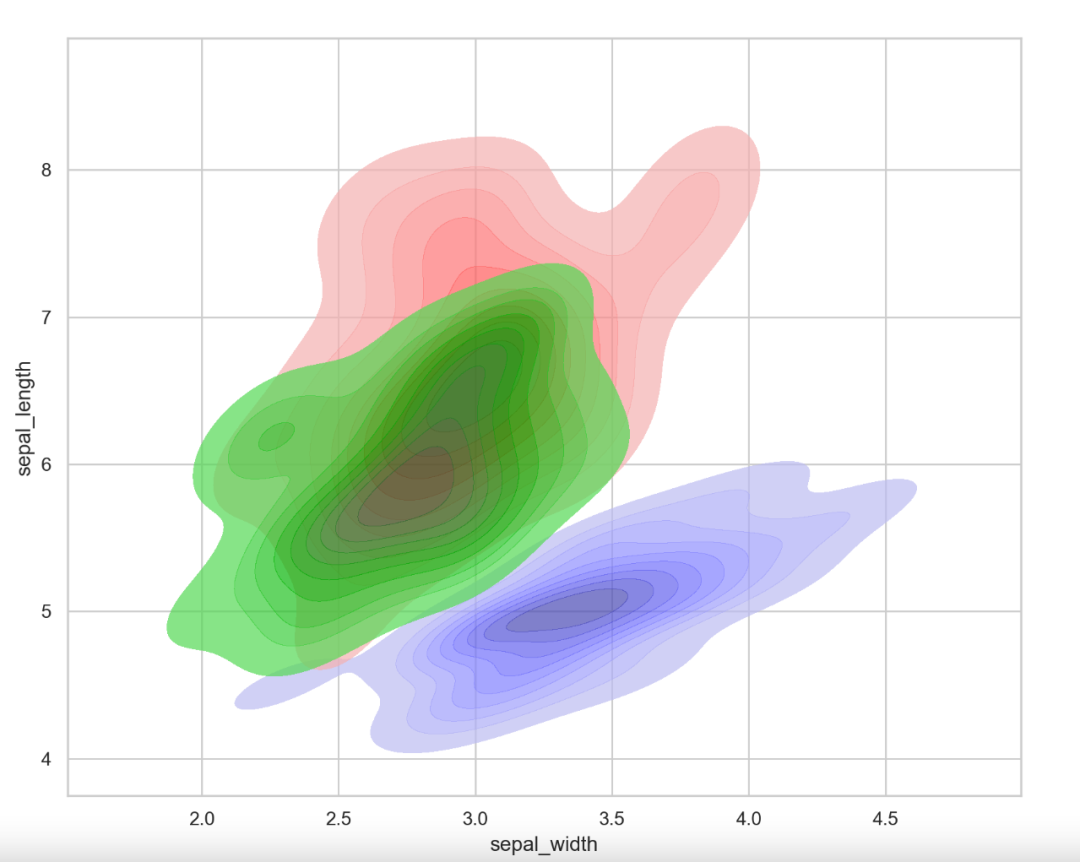
图9:鸢尾花数据集3种类别2个特征的二维KDE曲线
除此之外也有一些其他方法可以查看数据的分布,例如:箱线图、小提琴图、六边形分箱图等,本文不做过多介绍。
▐ 相关性
相关性系数
皮尔逊相关性系数(Pearson Correlation)是衡量向量相似度的一种方法。输出范围为-1到+1, 0代表无相关性,负值为负相关,正值为正相关。数值越接近1越相关。

iris.iloc[:, :4].corr()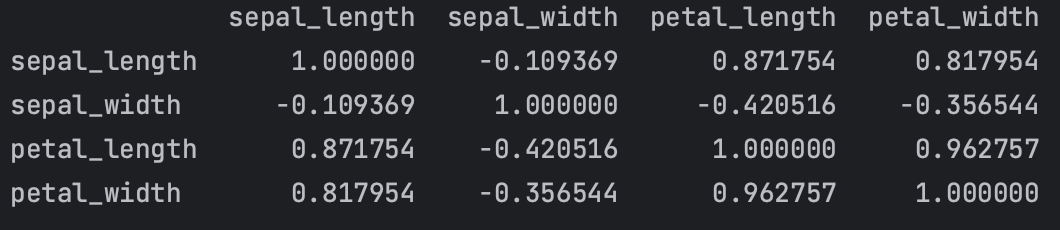
图10:鸢尾花数据集4个特征的相关性系数
将皮尔逊相关性系数矩阵绘制成热力图可以清楚地看出变量之间的相关关系:花萼长度和宽度没有相关性,而花瓣长度和宽度的相关性很明显。
sns.heatmap(iris.iloc[:, :4].corr(), annot=True, cmap='YlGnBu')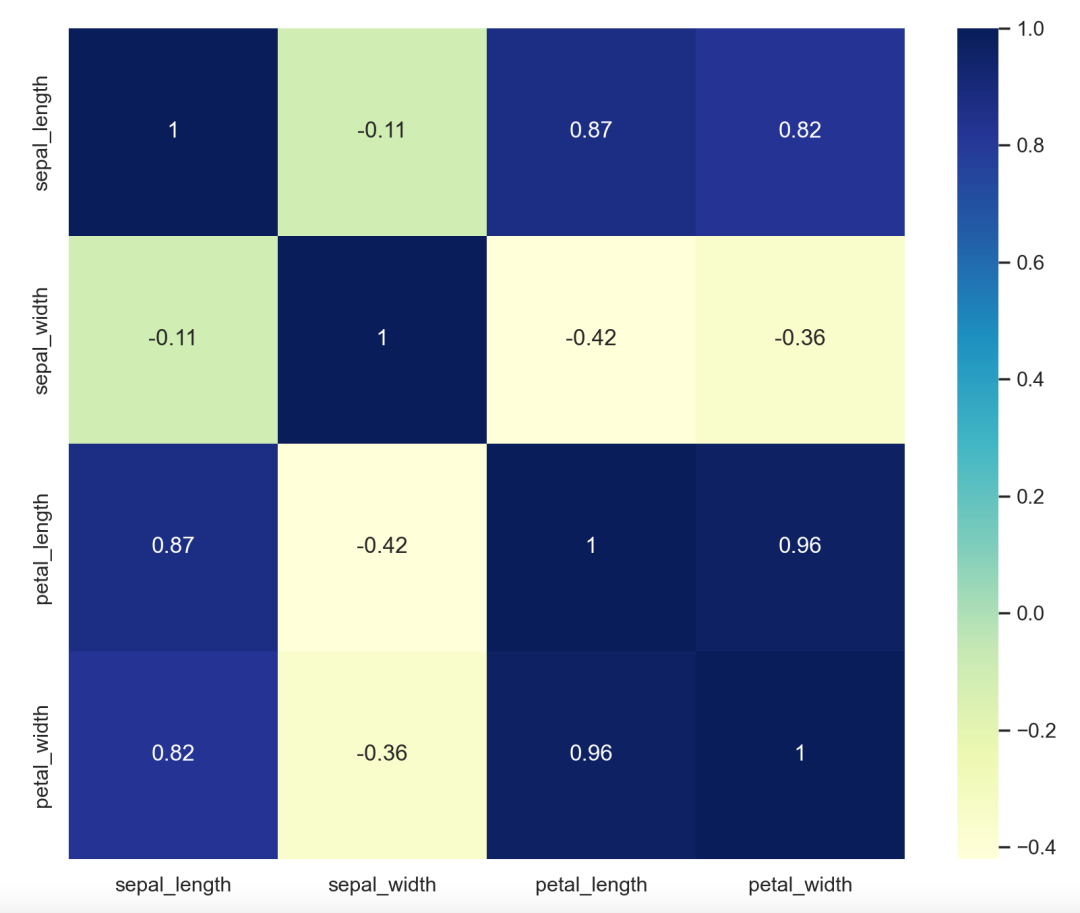
图11:鸢尾花数据集4个特征的相关性系数热力图
散点矩阵
可以用seaborn绘制出三种花的各个属性的散点矩阵。用于查看数据的相关性和概率密度分布。
import seaborn as sns# 其他代码略过sns.pairplot(iris, hue='class', diag_kind='kde')

图12:鸢尾花数据集4个特征的散点矩阵

分类算法
有了对数据的初步认知,从视觉上已经很容易分出类别来了,那么接下来就研究下通过各种分类算法自动进行分类。
工具:sklearn、graphviz、matplotlib
方法:决策树(CART)、逻辑回归(LR)、支持向量机(SVM)、K邻近(KNN)
目的:熟悉常见分类方法
▐ 决策树(CART)
原理介绍
决策树本质是一颗If-Then规则的集合树。基于二元划分(类似于二叉树)得到分类树,结构上由根结点和有向边组成。而其中的结点也可分为两种类型,一是内部节点,二是叶节点。决策树的优点是算法比较简单;理论易于理解;对噪声数据有很好的健壮性。简单的说来,决策树[3]可以分为三大类:如ID3/C4.5/CART这类基础树;集成学习中的Bagging;集成学习中的Boosting(如比较实用的GBDT、XGBoost等)。本文只介绍CART决策树。

决策树学习的关键是如何选择最优划分属性。一般来说,我们希望划分后分支节点所包含的样本尽量属于同一个类别,即节点的纯度(purity)越来越高。这里先介绍一些指标概念:

ID3算法:以信息增益为准选择决策树的属性。
C4.5算法:使用增益率选择最优划分属性。
CART:使用基尼指数划分属性。
模型训练
先对类别数据进行预处理转换为0、1、2这样的数字。并划分测试集和训练集。然后,从sklearn的树模型中选择DecisionTreeClassifier进行数据拟合。
from sklearn import preprocessingfrom sklearn.model_selection import train_test_splitfrom sklearn import treefrom common import *iris = read_iris()data = iris.iloc[:, :4].to_numpy()label_encoder = preprocessing.LabelEncoder()target = label_encoder.fit_transform(iris['class'])# 训练-测试数据切分X_train, X_test, y_train, y_test = train_test_split(data,target,test_size=0.2,random_state=42)x = data[:, 2:4] # 花瓣长宽y = targetclf = tree.DecisionTreeClassifier(max_depth=4)clf.fit(X_train, y_train)for feature_name, importance in zip(feature_names, clf.feature_importances_):print(f'{feature_name}: {importance}')
然后拟合数据并打印关键特征,可见花瓣宽度和花瓣长度是更重要的特征。
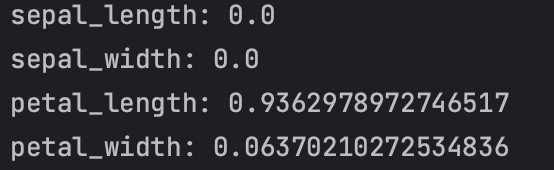
图14:模型特征重要性
模型解释
brew install graphviz修改~/.bash_profileexport PATH="/usr/local/bin:/usr/local/sbin:~/bin:$PATH"
import pydotplusdot_data = tree.export_graphviz(clf,out_file=None,feature_names=feature_names,class_names=iris['class'].unique(),filled=True,rounded=True)graph = pydotplus.graph_from_dot_data(dot_data)graph.write_png("data/decision_tree.png")

图15:决策树可视化
这个图中,黄绿紫分别代表三种鸢尾花。颜色越深代表gini指数越小,类别越纯。使用决策树我们希望找到纯度高并且层级少的分支。
只用花瓣长宽来绘制决策边界。如下图,可以看出决策边界与决策树是能够一一对应的。
x_min, x_max = x[:, 0].min() - 0.5, x[:, 0].max() + 0.5y_min, y_max = x[:, 1].min() - 0.5, x[:, 1].max() + 0.5camp_list = ListedColormap(['#e58139', '#4de98e', '#853ee6'])h = 0.02xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) # 用花瓣长宽属性值生成网格clf2 = tree.DecisionTreeClassifier(max_depth=4)clf2.fit(x, y)graph = pydotplus.graph_from_dot_data(tree.export_graphviz(clf2,out_file=None,feature_names=names[2:4],class_names=iris['class'].unique(),filled=True,rounded=True))graph.write_png("data/decision_tree2.png")Z = clf2.predict(np.c_[xx.ravel(), yy.ravel()])Z = Z.reshape(xx.shape)plt.figure()plt.pcolormesh(xx, yy, Z, cmap=camp_list)plt.scatter(x[:, 0], x[:, 1], c=y)plt.xlim(xx.min(), xx.max())plt.ylim(yy.min(), yy.max())plt.xlabel('petal_length')plt.ylabel('petal_width')plt.show()
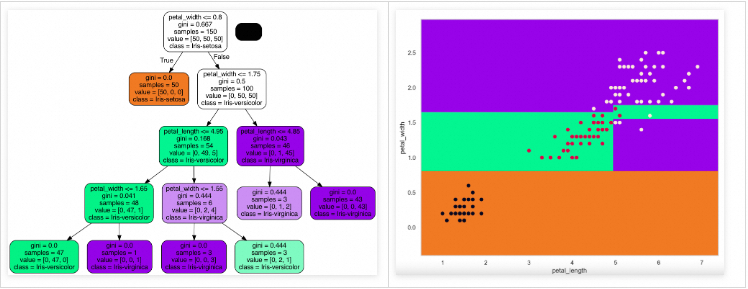
图16:仅用花瓣长宽特征的决策树决策边界
预测和评估
a = np.array([6,2,4,1]).reshape(1, -1)pa = clf.predict(pd.DataFrame(a, columns=feature_names))print(pa) # [1]
b = np.row_stack((data[10], data[20], data[40], data[80], data[140]))pb = clf.predict(pd.DataFrame(b, columns=feature_names))print(pb) # [0 0 0 1 2]
经过模型评估,可以看到准确性为100%。
accuracy = clf.score(X_test, y_test)print("Accuracy:", accuracy) # Accuracy: 1.0
补充下精度、召回率、F1
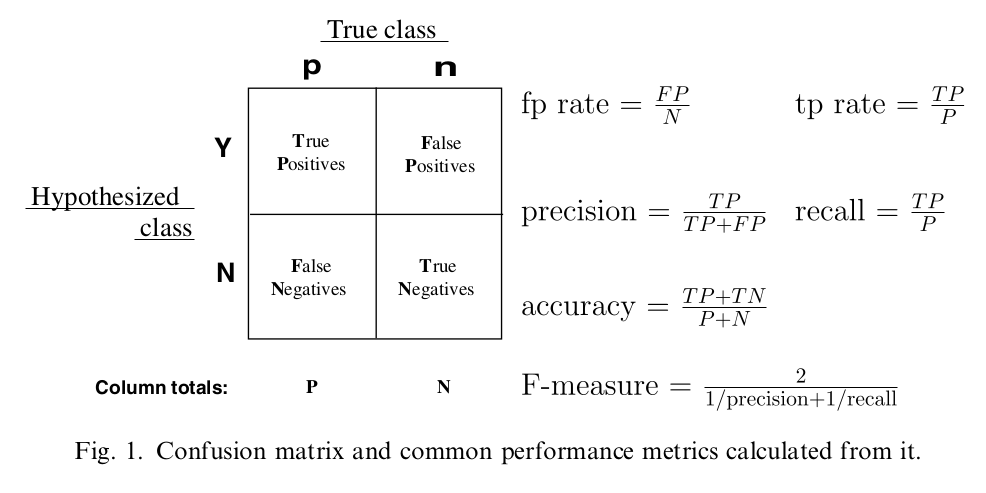
-
真正例 - 预测为正样本且实际为正样本的样本数称为真正例(True Positive,TP)。 -
假正例 - 预测为正样本但实际为负样本的样本数称为假正例(False Positive,FP)。 -
真负例 - 预测为负样本且实际为负样本的样本数称为真负例(True Negative,TN)。 -
假负例 - 预测为负样本但实际为正样本的样本数称为假负例(False Negative,FN)。 -
精度 - 评估预测得准不准,精度 = TP / (TP + FP),即:预测为正样本且实际为正样本的样本数 / 预测为正样本的样本数。 -
召回率 - 评估预测得全不全,召回率 = TP / (TP + FN),即:预测为正样本且实际为正样本的样本数 / 所有实际为正样本的样本数。 -
F1指标 - 精度和召回率的调和平均数,F1 = 2 * (精度 * 召回率) / (精度 + 召回率)。
▐ 逻辑回归(LR)
-
原理介绍
-
sigmoid函数: 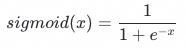
如图,是一种S型曲线。导数是先增后减。当输入值接近正无穷大时,Sigmoid函数趋近于1;当输入值接近负无穷大时,Sigmoid函数趋近于0。

图18:sigmoid函数及其导数
logistic回归:

其中,hθ(x)表示预测值,sigmoid()表示Sigmoid函数,θ为模型参数向量,x为输入特征向量。模型参数向量θ包括截距项(intercept)和各个特征的系数。
softmax回归:
softmax逻辑回归模型是logistic回归模型在多分类问题上的推广,在多分类问题中,类标签y可以取两个以上的值。
预测和评估
在scikit-learn中,LogisticRegression类默认使用一对多(One-vs-Rest)策略来进行多分类任务的处理。该策略将多分类问题转化为多个二分类子问题。对于k个类别的多分类问题,LogisticRegression会训练k个二分类模型,每个模型都是将一个类别与其他所有类别进行区分。
model = LogisticRegression()model.fit(X_train, y_train)y_pred = model.predict(X_test)accuracy = metrics.accuracy_score(y_test, y_pred)recall = metrics.recall_score(y_test, y_pred, average='weighted')print("Accuracy:", accuracy) # 1.0print("Recall:", recall) # 1.0confusion_matrix_result = metrics.confusion_matrix(y_test, y_pred)print('confusion matrix:\n', confusion_matrix_result) # [[10, 0, 0], [0, 9, 0], [0, 0, 11]]## 利用热力图对于结果进行可视化,画混淆矩阵plt.figure(figsize=(8, 6))sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues')plt.xlabel('Predicted label')plt.ylabel('True label')plt.show()

▐ 支持向量机(SVM)
原理介绍
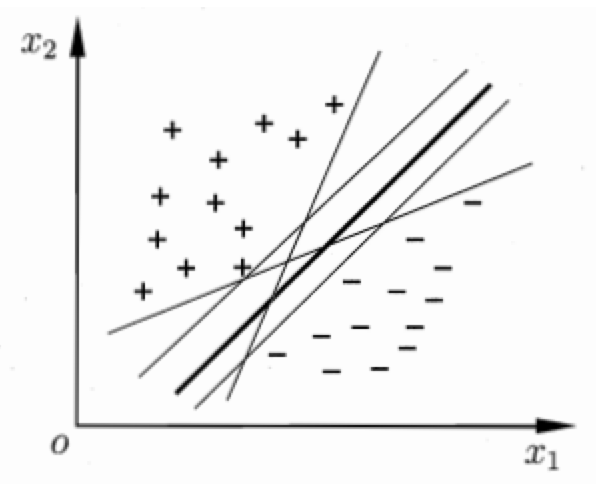
图20:SVM的最优决策边界
支持向量[10]:在决定最佳超平面时只有支持向量起作用,而其他数据点并不起作用。

图20:SVM的支持向量、超平面
核技巧。用于处理非线性可分的场景,核技巧的基本思路分为两步:使用一个变换将原空间的数据映射到新空间(例如更高维甚至无穷维的空间);然后在新空间里用线性方法从训练数据中学习得到模型。常用的核函数有线性核函数、高斯核函数、多项式核函数、拉普拉斯核函数、Sigmoid核函数等。
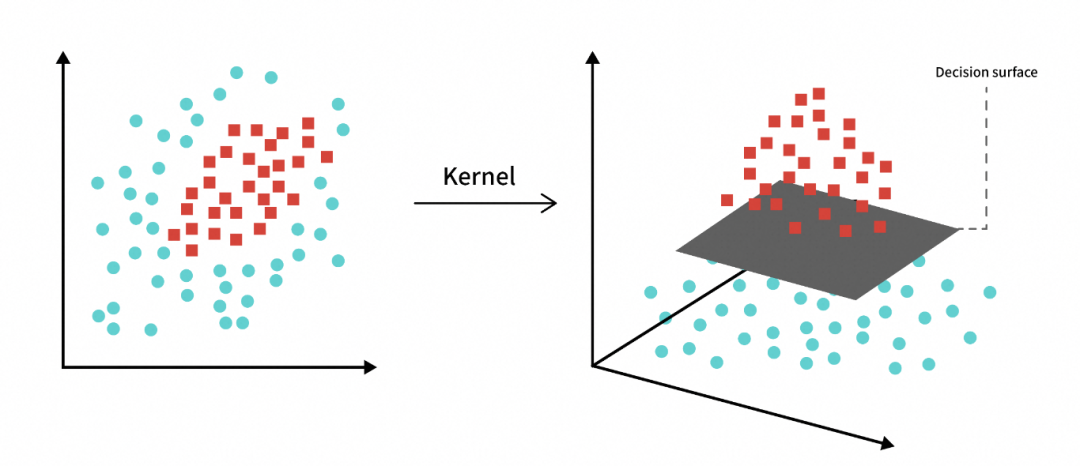
图21:使用核函数升维后线性可分[15]
预测和可视化
使用sklearn中的svm函数非常简单,与之前的方法类似。先将数据集按照训练集和测试集切分;然后只使用花瓣长宽两个特征,并进行标准化处理;接下来使用svm.SVC分类模型拟合数据;最后再用可视化的方式呈现分类的决策边界。
# 挑选特征x = data[:, 2:4]y = targetX_train2, X_test2, y_train2, y_test2 = train_test_split(x, y, test_size=0.2, random_state=42)# 特征值标准化standard_scaler = preprocessing.StandardScaler()standard_scaler.fit(X_train2)X_train_std = standard_scaler.transform(X_train2)X_test_std = standard_scaler.transform(X_test2)# 合并标准化后的数据集X_combined_std = np.vstack((X_train_std, X_test_std))y_combined = np.hstack((y_train, y_test))# 拟合数据model = svm.SVC(kernel='rbf', random_state=0, gamma=10, C=10.0)model.fit(X_train_std, y_train)# 可视化决策边界def plot_decision_regions(X, y, classifier, test_idx=None, resolution=0.02):# 定义颜色和标记符号,通过颜色列图表生成颜色示例图marker = ('o', 'x', 's', 'v', '^')colors = ('lightgreen', 'blue', 'red', 'cyan', 'gray')cmap = ListedColormap(colors[:len(np.unique(y))])# 可视化决策边界x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),np.arange(x2_min, x2_max, resolution))to_predict = np.c_[xx1.ravel(), xx2.ravel()]Z = classifier.predict(to_predict)Z = Z.reshape(xx1.shape)print('to_predict', Z)plt.contourf(xx1, xx2, Z, alpha=0.4, cmap=cmap)plt.xlim(xx1.min(), xx1.max())plt.ylim(xx2.min(), xx2.max())# 绘制所有的样本点for idx, cl in enumerate(np.unique(y)):plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1], alpha=0.8,color=cmap(idx), marker=marker[idx], s=73, label=cl)# 使用小圆圈高亮显示测试集的样本if test_idx:X_test, y_test = X[test_idx, :], y[test_idx]plt.scatter(X_test[:, 0], X_test[:, 1], color=cmap(y_test), alpha=1.0, linewidth=1,edgecolors='black', marker='o', s=135, label='test set')## 可视化plt.figure(figsize=(12, 7))plot_decision_regions(X_combined_std, y_combined, classifier=model,test_idx=range(120, 150))plt.title('decision region', fontsize=19, color='w')plt.xlabel('standard petal length', fontsize=15)plt.ylabel('standard petal width', fontsize=15)plt.legend(loc=2, scatterpoints=2)plt.show()
核函数为径向基函数(Radial Basis Function),也称为高斯核函数。gamma参数调整为10,会有较小的边界,可视化后的效果如下。
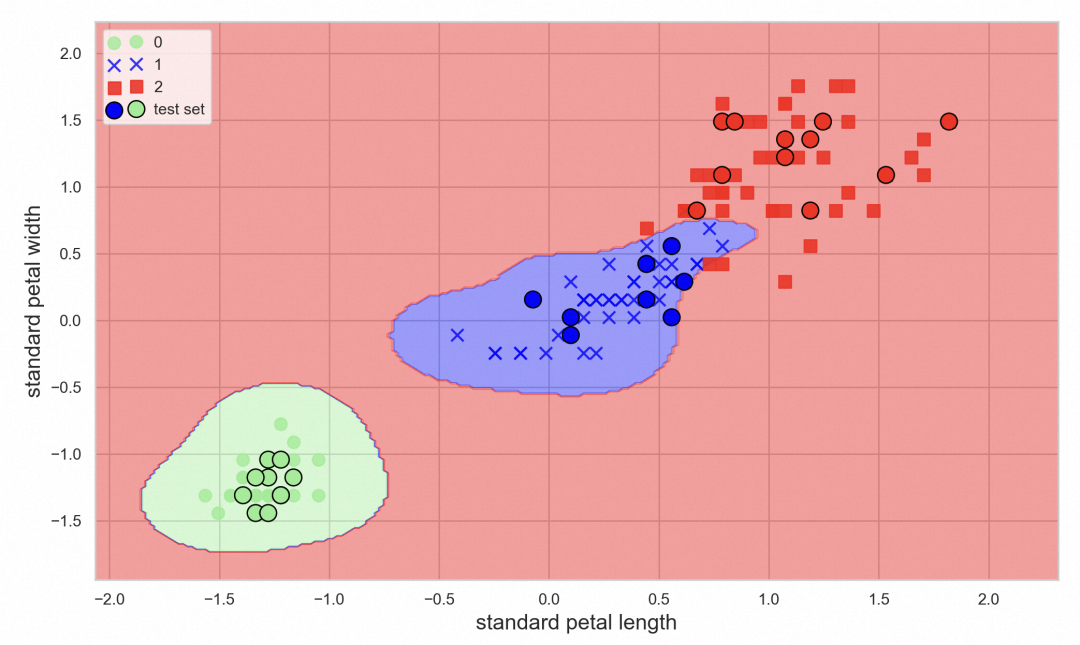
图22:SVM分类效果
▐ K邻近(KNN)
原理介绍
KNN(K- Nearest Neighbor)法即K最邻近法[6][11],最初由 Cover和Hart于1968年提出,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。KNN是一种非参数、有监督的分类算法,它使用邻近度对单个数据点的分组进行分类或预测。 通常用于分类算法,也可以用于回归。
KNN算法的步骤可以描述如下:
选择一个合适的距离度量方法,常用的有欧式距离(Euclidean distance)、曼哈顿距离(Manhattan distance)等。
对于一个新样本点x,计算其与训练集中所有样本点的距离。
选取与新样本点x距离最近的K个训练样本点,这些样本点构成了x的K个最近邻。
对于分类问题,采用投票法确定x的类别。即,统计K个最近邻中每个类别出现的次数,将出现次数最多的类别作为x的预测类别。
对于回归问题,采用平均法确定x的预测值。即,将K个最近邻的数值标签进行平均,得到x的预测值。

图23:KNN算法原理
KNN算法默认使用的距离度量公式是欧式距离,距离在度量相似度方面非常重要,很多算法如k-NN、UMAP、HDBSCAN都会用到。这里补充下常见的距离公式[12]。
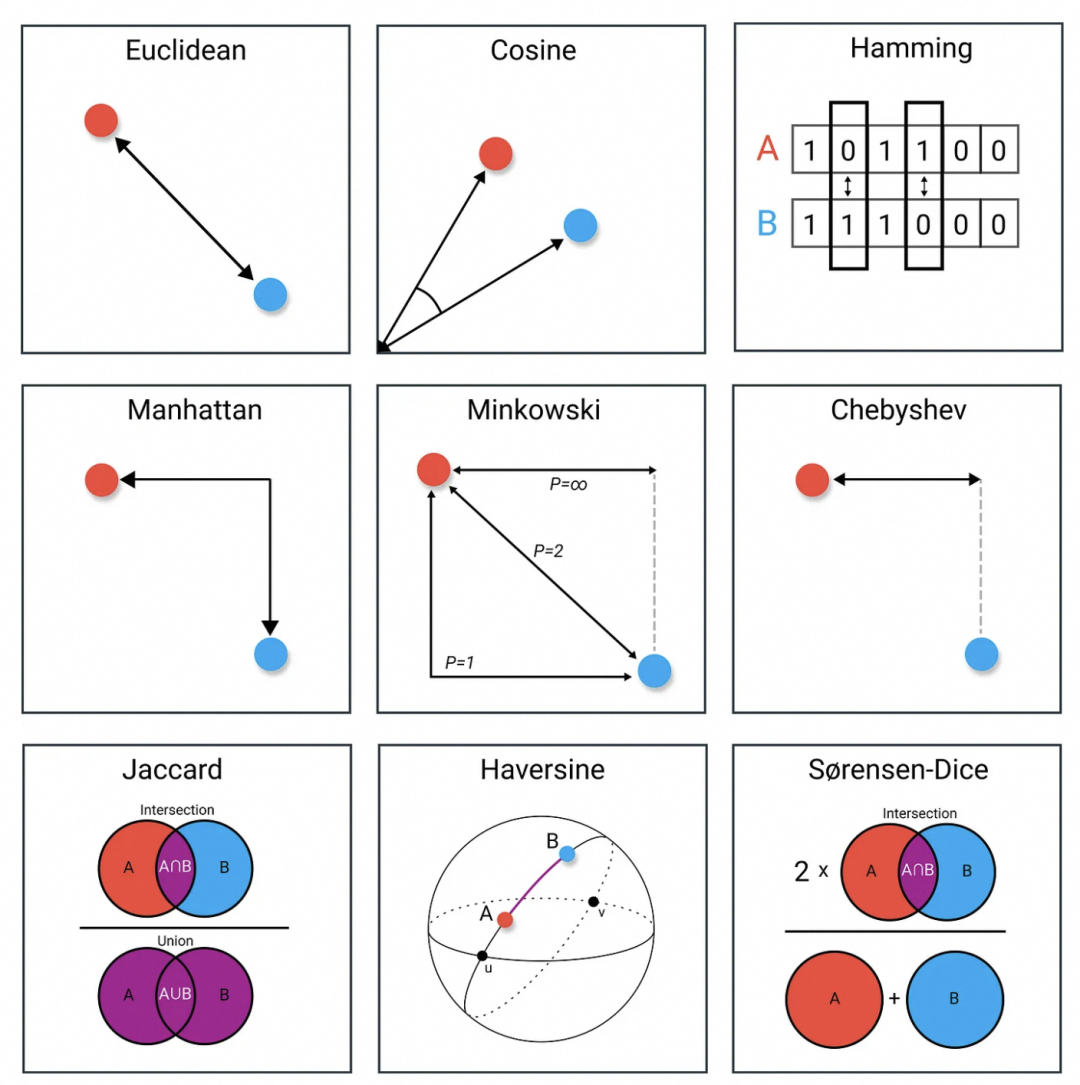
图24:9种常用距离公式
欧几里得距离是连接两点的线段的长度。
余弦相似性是两个向量之间的角度的余弦。
Hamming距离是两个向量之间不同的值的数量。它通常用于比较两个等长的二进制字符串。
曼哈顿距离,通常称为出租车距离或城市街区距离,计算实值向量之间的距离。
切比雪夫距离被定义为两个向量之间沿任何坐标维度的最大差异。
Haversine距离是指球体上两点之间的距离。
-
雅卡德指数(或交集大于联盟)是一个用于计算样本集的相似性和多样性的指标。
预测和展示
在sklearn中KNeighborsClassifier方法实现了KNN算法。使用方法与上文类似,这已经是一个模板化流程了:先对数据进行标准化等预处理;然后切分为训练集和测试集;再配置对应的算法的参数;接下来拟合训练数据并预测测试数据;最后进行指标或可视化评估。借助上文提到的标准化后的数据以及决策边界可视化方法来进行预测和展示。
def k_neighbors_classifier():model = KNeighborsClassifier(n_neighbors=2, p=2, metric="minkowski")model.fit(X_train_std, y_train)plot_decision_regions(X_combined_std, y_combined, classifier=model, resolution=0.02)plt.xlabel('petal length [standardized]', fontsize=15)plt.ylabel('petal width [standardized]', fontsize=15)plt.legend(loc='upper left', scatterpoints=2)plt.show()
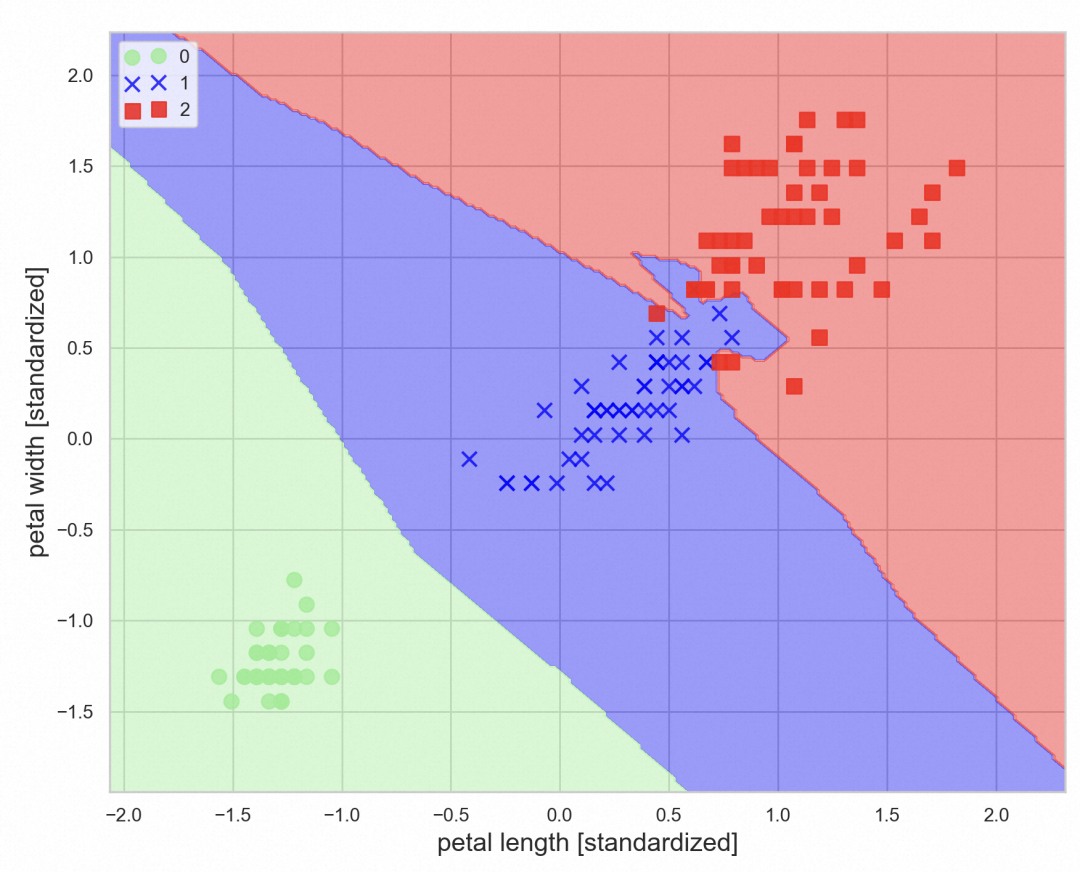
图25:KNN分类

本文以机器学习领域中著名的鸢尾花分类数据集为起点,首先对其进行了多种数据探索。此阶段,我们运用了描述性统计分析这一强有力的工具,通过对数据内在规律的抽丝剥茧;同时辅以直方图、KDE密度估计图等可视化手段,生动地勾勒出各类变量的概率分布形态;并使用皮尔逊相关系数和散点矩阵的方式分析了鸢尾花各个字段的相关性。使得我们能够建立起对鸢尾花数据的直观而感性的认知。透过这些视觉化的呈现,我们可以清晰洞察到数据内在的类别划分,即三个各具特色的鸢尾花品种。
随后,依托这份富含信息的数据宝库,我们依次展开了决策树、逻辑回归、支持向量机以及K近邻这四种经典分类算法的实践之旅。在阐述每种算法原理的过程中,我们力求深入浅出,使其初露端倪的智慧内核得以揭示;同时,遵循机器学习的标准流程,我们演示了一套完整且规范的建模过程,从而让理论知识与实际操作紧密结合。尤为值得一提的是,我们巧妙地借助于可视化技术,将各类算法的分类效果栩栩如生地展现出来,使人仿佛置身于一场科学与艺术交织的盛宴之中。
总的来说,这篇文章旨在引导读者深入理解并掌握机器学习分类任务的分析方法,并期待这种洞见能够在广大读者各自的专业实践中绽放异彩,助力解决现实世界中的复杂问题。

参考资料
[1] AL、ML、DL之间的关系 https://blogs.nvidia.com/blog/whats-difference-artificial-intelligence-machine-learning-deep-learning-ai/
[2] 机器学习的分类 https://c.biancheng.net/view/9in9o7.html
[3] 选择机器学习算法 https://feisky.xyz/machine-learning/basic.html
[2] PCA主成分分析可视化 https://projector.tensorflow.org/
[3] 决策树介绍 https://zhuanlan.zhihu.com/p/560962641
[4] 切换brew镜像安装graphviz https://blog.51cto.com/u_15127504/3819701
[5] svm分类以及可视化 https://www.cnblogs.com/shanger/articles/11858205.html
[6] KNN分类 https://zhuanlan.zhihu.com/p/173945775
[10] svm原理 https://zhuanlan.zhihu.com/p/49331510
[11] knn算法 https://www.ibm.com/cn-zh/topics/knn
[12] 距离公式 https://towardsdatascience.com/9-distance-measures-in-data-science-918109d069fa
[13] 机器学习算法分类大图 https://static.coggle.it/diagram/WHeBqDIrJRk-kDDY/t/categories-of-algorithms-non-exhaustive?from=timeline&isappinstalled=0
[14] 核密度估计 https://lotabout.me/2018/kernel-density-estimation/
[15] 核函数的作用 https://blog.naver.com/PostView.naver?blogId=nhncloud_official&logNo=223186847311&redirect=Dlog&widgetTypeCall=true

我们是淘天集团猫超&食品生鲜技术团队,负责面向猫超&食品生鲜技术的B、C端业务。团队致力于持续创新和突破核心技术,以优化平台用户体验和业务价值。持续关注且投入消费者行为、机器学习、LLM、AIGC等相关前沿技术的研究与实践,并通过新技术服务团队和业务创新。
目前团队招聘中,欢迎聪明靠谱的小伙伴加入(社招、校招、实习生),有兴趣可将简历发送至[email protected]。
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。