HDFS的块比磁盘块大,目的是为了最小化寻址开销。如果块设置的足够大,从磁盘传输数据的时间可以明显大于定位这个块开始位置所需要的时间。这样,传输一个由多个块组成的文件的时间取决于磁盘传输速率。
寻址时间10ms左右,HDFS使让块寻址时间占用读取时间的1%,以传输速率100MB/s为例,设置块大小为128MB。
但是该参数也不会设置得过大。MapReduce中的map任务通常一次处理一个块中的数据,因此如果任务数太少(少于集群中的节点数量),作业的运行速度就会比较慢。
与其他文件系统不一样,HDFS中小于一个块大小的文件不会占据整个块的空间。对分布式文件系统的块进行抽象会带来很多好处。第一个明显的好处是,一个文件的大小可以大于网络中任意一个磁盘的容量。文件的所有块并不需要存储在同一个磁盘上,因此他们可以利用集群上的任意一个磁盘进行存储。
1.从下图可以看出,当文件小于一个块的时候,不会分块存储,但在多个datanode上都有块的副本。

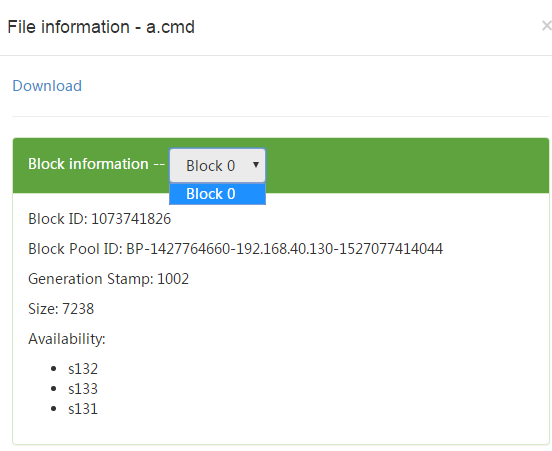
2.当上传的是一个大于单块大小的文件时如下图,被分成了多块,所有块在所有datanode上都有副本。
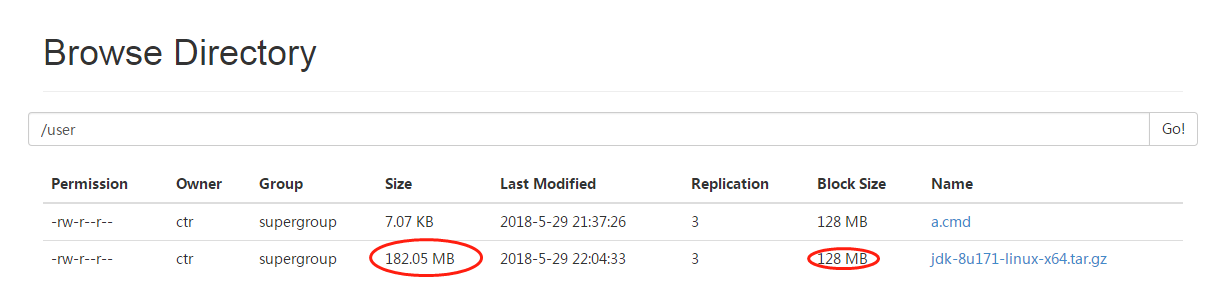

其中
block-0,Size: 134217728,Block ID: 1073741829
block-1,Size: Size: 56672394,Block ID: 1073741830
在namenode上进入Hadoop_tmp_dir:
$ cd /home/ctr/soft/hadoop-2.7.3/tmp/ //这里被自己修改过,默认应该为/tmp
$cd dfs/name/current
$ls

上图中的fsimage*为文件系统镜像,edit*为编辑日志(记录对HDFS的操作),在每次启动hadoop集群时都会加载,见下图。
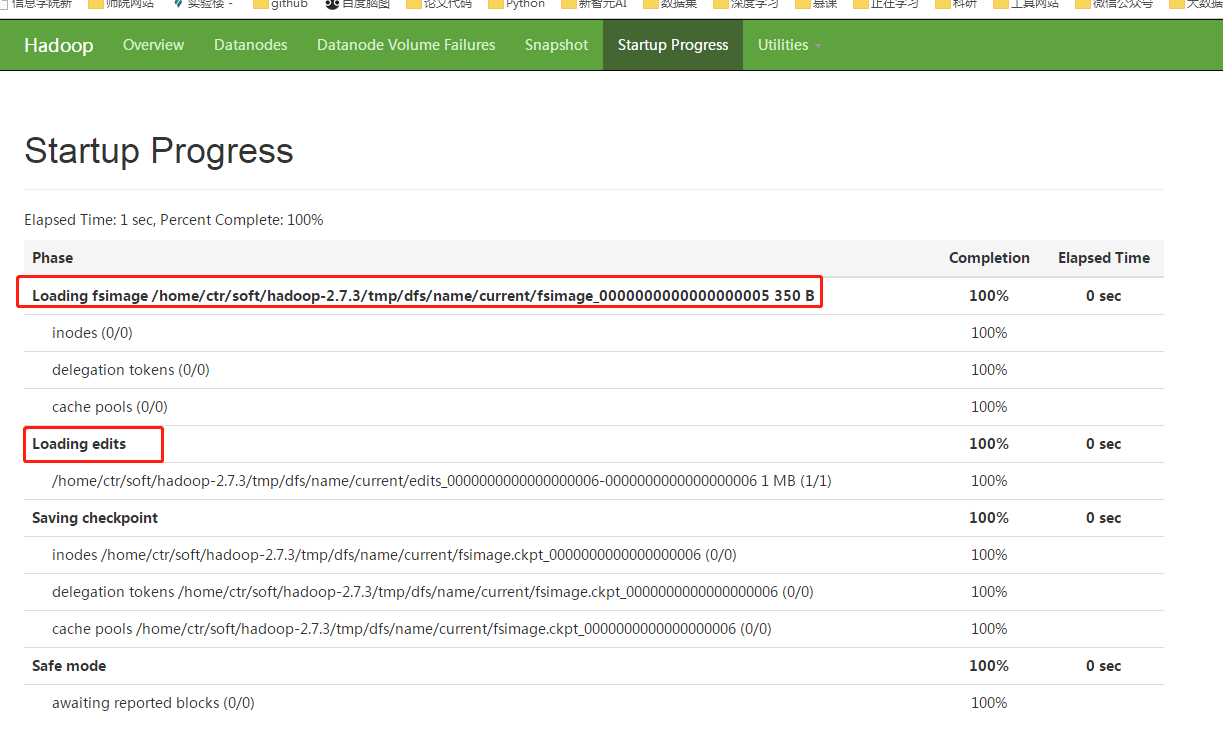
在datanode上
$cd /tmp/hadoop-ctr/dfs/data/current

继续多次cd…
/tmp/hadoop-ctr/dfs/data/current/BP-1427764660-192.168.40.130-1527077414044/current/finalized/subdir0/subdir0
可以看到块ID和块大小,和Web端看到的一样。

3.小实验
将这两个块文件分别拷贝到~/Download目录下,并切换到Download下:
将830块追加到829块后并改名
$ catblk_1073741830 >> blk_1073741829
$ mvblk_1073741829 blk_1073741829.tar.gz
$tar -xjzf blk_1073741829.tar.gz
解包后发现就是上传到HDFS中的JDK文件,所以HDFS分块其实和JAVA分包机制一样,没有什么新意。
4.HDFS不适合的情况
(1)低延迟要求的数据访问选用HBase更好。
(2)大量的小文件存储不适合,应先将大量小文件归档处理。namenode将文件系统的元数据存储在内存中,因此该文件系统所能存储的文件总数受限于namenode的内存容量。每个文件、目录和数据块的存储信息大约占150字节,可以由此估算可以存储的文件数。
(3)多用户写入,任意修改文件。HDFS只能有一个写操作者,且写操作总是将数据添加在文件的末尾。(用hdfs dfs –appendToFile 源 目的可以测试)
5.namenode上只保存块列表信息,不保存具体数据。DataNode启动后要向namenode报告状态,完成namenode块列表到Datanode的名称映射。
6.HA(HighAvailability,高可用性,用几个9衡量—99.999%),SPOF(Single Point Of Failure,单点故障)。为了预防单点故障,namenode通过配置secondary Namenode实现。