1.HiveSQL的MR转换
众所周知,HiveSQL最终是要被转换成MR的(Hive On MapReduce),这里梳理下这个转换为MR的过程
1.1 不跑MapReduce的情况
在以下特殊场景,HiveSQL并不会启动MapReduce
简单查询
分区表查询
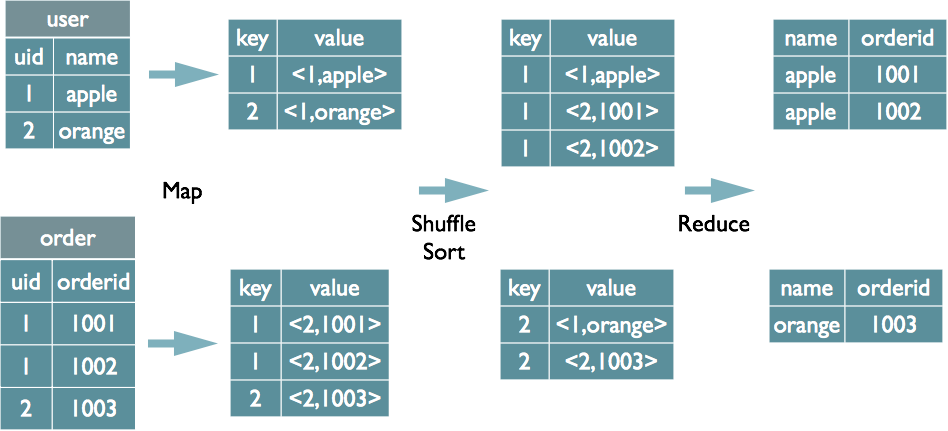
1.2 join
以join的字段进行map分组,在map的输出端设置tag以标记来源
Map排序后,在reduce端将Map相同的key合并,join完成.
1.3 group by
explain select city,sum(id) from dept_et group by city;
执行计划如下:
STAGE DEPENDENCIES: Stage-1 is a root stage Stage-0 depends on stages: Stage-1 STAGE PLANS: <!--stage定义,一个stage对应一个MapReduce--> Stage: Stage-1 <!--Map过程--> Map Reduce Map Operator Tree: TableScan //表扫描 alias: dept_et Statistics: Num rows: 3 Data size: 322 Basic stats: COMPLETE Column stats: NONE //表dept_et的统计数据预估 Select Operator //查询列裁剪,表示只需要 city (type: string), id (type: int) 两列 expressions: city (type: string), id (type: int) outputColumnNames: city, id Statistics: Num rows: 3 Data size: 322 Basic stats: COMPLETE Column stats: NONE <!--map操作定义 是以city (type: string)取hash作为key,执行函数sum(id),结果为_col0, _col1(hash(city),sum(id))--> Group By Operator aggregations: sum(id) //分组执行函数=>sum(id) keys: city (type: string) mode: hash outputColumnNames: _col0, _col1 Statistics: Num rows: 3 Data size: 322 Basic stats: COMPLETE Column stats: NONE <!--map端的输出--> Reduce Output Operator key expressions: _col0 (type: string) //Map端输出的Key是_col0(hash(city)) sort order: + Map-reduce partition columns: _col0 (type: string) Statistics: Num rows: 3 Data size: 322 Basic stats: COMPLETE Column stats: NONE value expressions: _col1 (type: bigint) //Map端输出的Value是_col1(sum(id)) <!--Reduce过程 合并多个Map的输出 以_col0(也就是map输出的hash(city))为key 执行sum(VALUE._col0(也就是map输出的sum(id))),执行结果也是_col0, _col1(hash(city),sum(sum(id)))--> Reduce Operator Tree: Group By Operator aggregations: sum(VALUE._col0 keys: KEY._col0 (type: string) mode: mergepartial //partial(多个map的输出)merge(合并) outputColumnNames: _col0, _col1 Statistics: Num rows: 1 Data size: 107 Basic stats: COMPLETE Column stats: NONE <!--Reduce端的输出 输出为一个临时文件,不压缩--> File Output Operator compressed: false Statistics: Num rows: 1 Data size: 107 Basic stats: COMPLETE Column stats: NONE table: input format: org.apache.hadoop.mapred.TextInputFormat output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe Stage: Stage-0 Fetch Operator limit: -1 Processor Tree: ListSink
1.4 distinct
1.4.1 distinct一个
select dealid, count(distinct uid) num from order group by dealid;
只有一个distinct,不考虑HashGroup的情况下,可以将group字段和distinct字段一起组合为Map的输出Key,然后把group字段作为Reduce的Key,在Reduce阶段保存LastKey
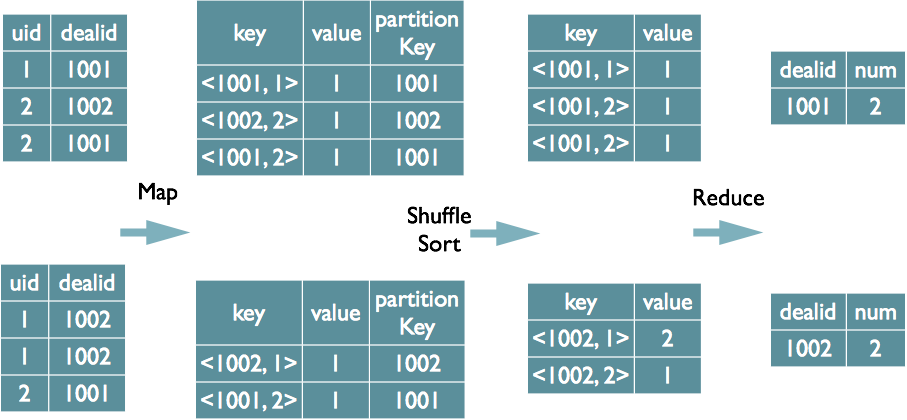
1.4.2 多个distinct字段
select dealid, count(distinct uid), count(distinct date) from order group by dealid;