最近发现许多JMeter的使用用户在利用正则表达式提取器作为“关联”方法时,仍然对Java正则表达式的理解上有所偏差,导致很多时候属于“撞大运”式的进行不断试错来完成正确的提取器配置项设置,从而得到正确的关联结果。本文为大家重新梳理一下Java正则表达式和正则表达式提取器的一些基本特性以及正则表达式的配置方法,使大家可以比较顺畅的完成基于正则表达式提取器的关联操作。
Mock环境准备
首先,我们来准备一个用于实验的模拟环境。通过NodeJS准备Mock环境,编写一个js 脚本提供HTTP服务,在关联方法的选择中如果是标签语言文本(html或xml)更建议使用CSS/JQuery Extractor”或“XPath Extractor”来进行处理,因此,本文的Mock环境我们使其返回一串JSON文本,脚本server.js参考如下代码片段:
var http = require('http');
var server = http.createServer(function(request, response){
try {
var out = "{FBI:[{name:\"rose\",age:\"25\"},{name:\"jack\",age:\"23\"}],NBA:[{name:\"tom\",sex:\"man\"},{name:\"lily\",sex:\"women\"}]}";
response.end(out);
} catch (err) {
response.end(err.toString());
}
});
server.listen(80);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
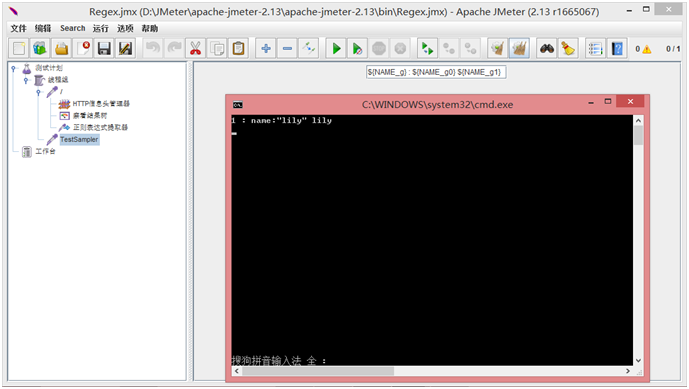
通过node server.js命令运行脚本,使用浏览器进行访问:
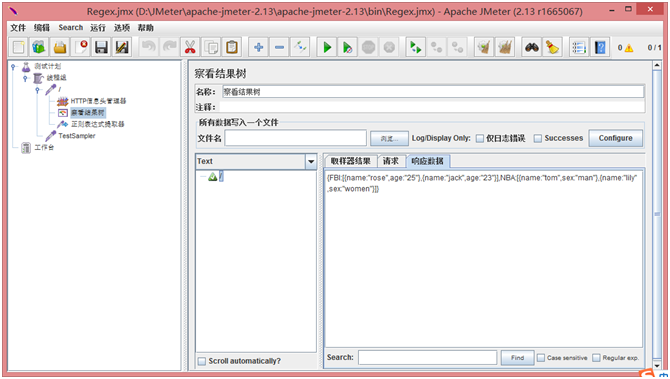
可以看到,我们通过Mock的HTTP服务返回了一个JSON串作为我们实践正则表达式提取器的应用数据已经可以正常访问。使用JMeter的HTTPSampler测试:

Java正则表达式方法
这里就不对Java正则表达式的使用做基础学习了,下面列出了我们在进行“关联”操作时,需要掌握的基本元字符:
( ) :将 () 之间括起来的表达式定义为“组”(group),并且将匹配这个表达式的字符保存到一个临时区域,我们主要就是利用这个元字符配合所指定的字符串匹配规则来进行匹配信息的提取;
.+: 一个以上的任意字符,通过Greediness(贪婪型)匹配策略进行表达式模板的匹配(最大匹配);
.+?:通过?元字符表示一个非贪婪模式匹配,即通过 Reluctant(勉强型)匹配策略进行表达式模板的匹配(最小匹配);
另外,还包括.*,.*?,\d,\D,\w,\W等。
下面我们可以看一段典型的Java正则表达式应用代码,来对我们准备的JSON串进行内容匹配:
public static void main(String[] args){
Pattern pattern = Pattern.compile("age:\"(.+?)\"", Pattern.DOTALL);
Matcher matcher = pattern.matcher("{FBI:[{name:\"rose\",age:\"25\"},{name:\"jack\",age:\"23\"}],NBA:[{name:\"tom\",sex:\"man\"},{name:\"lily \",sex:\"women\"}]}");
int matchNum = 0;
while(matcher.find()) {
int groupCount = matcher.groupCount();
for(int i = 0; i <= groupCount; i++){
System.out.println("MatchNum: " + matchNum + " Template: " + i + " MatchResult:"+matcher.group(i));
System.out.println("------------------------------------");
}
matchNum++;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
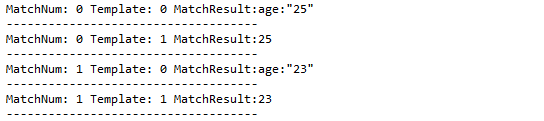
我们使用正则表达式age:”(.+?)”对JSON串的匹配结果输出如下:
正则表达式提取器对应设置方法
我们来对照一下JMeter的正则表达式提取器GUI配置界面的相关配置项就会一目了然: 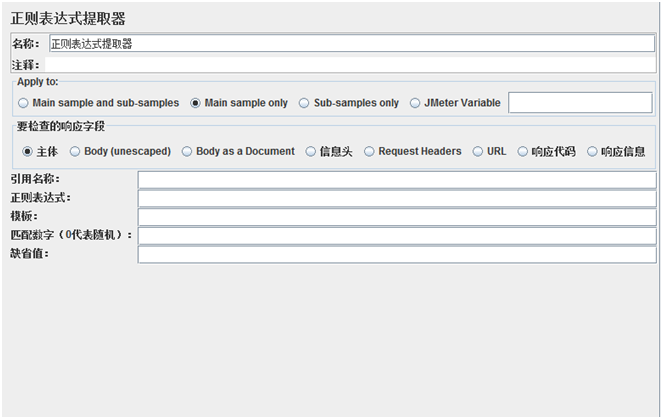
“正则表达式”项设置为age:”(.+?)”;
“模板”项对应程序输出中的Template,比如需要设置模板为1,在JMeter中使用$1$来表示;
“匹配数字”项对应程序输出中的MatchNum,可以理解为匹配到结果所出现的次数,比如需要设置匹配数字为1,在JMeter中使用1来表示。
按照这种方式设置,应该对应此行输出结果: 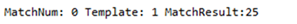
与Java程序中的输出是一致的,这下我们就明白JMeter正则表达式提取器各个配置项的主要含义了。
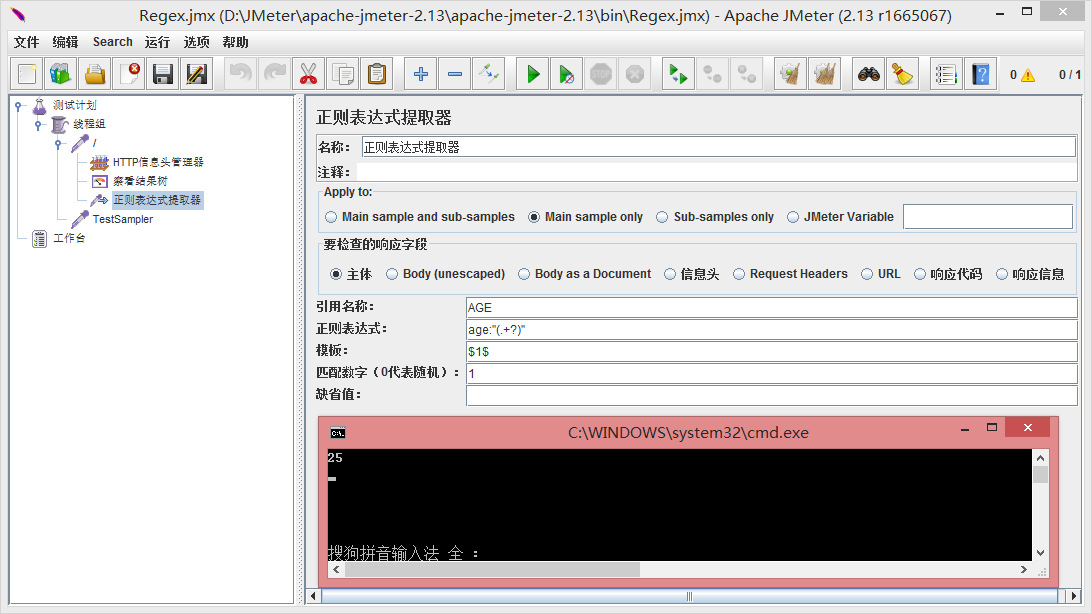
比如,现在想要匹配lily,看一下JSON串,如果正则表达式是这样设置的name:”(.+?)”,我们发现是第4次匹配到的,就设置匹配数字为4,模板仍然为$1$,设置后,看一下结果:
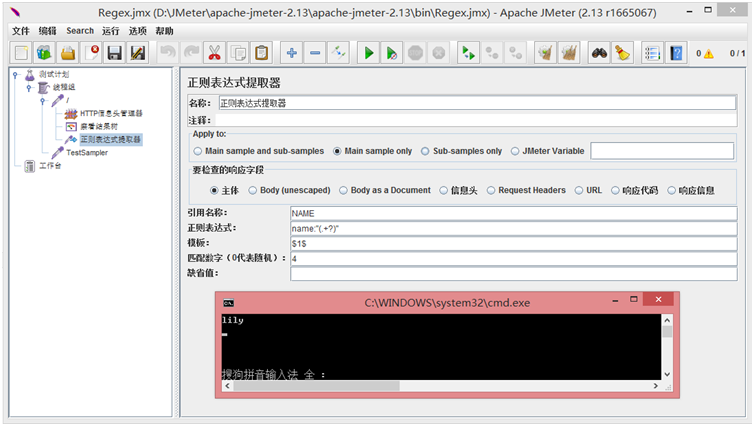
当然,你也可以不用设置“模板”项,通过refName_g(the number of groups in the Regex)和refName_gn(where n=0,1,2 - the groups for the match)的方式来对组序号进行选择,比如下面的例子: