目录
数据集介绍
本次使用的验证码是方正系统,现在很多的大学的教务系统用的就是这个方正系统,刚好既然那么普遍,我们就用它练一练手。经过观察大量的验证码发现,该系统的验证码只有小写的字母和数字,这样分类就少了很多了。该系统的验证码如下:
| 验证码 | 尺寸 | 说明 |
|---|---|---|
 |
72*27 | 只有数字和小写字母 |
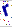 |
12*27 | 第一个X方向的从5开始裁剪到17,Y取全部,即从0裁剪到27 |
 |
12*27 | 第二个X方向的从17开始裁剪到29,Y取全部,即从0裁剪到27 |
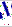 |
12*27 | 第三个X方向的从29开始裁剪到41,Y取全部,即从0裁剪到27 |
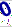 |
12*27 | 第四个X方向的从41开始裁剪到53,Y取全部,即从0裁剪到27 |
通过上面表上说明,我们就可以开始裁剪验证码了。在裁剪之前我们先要下载编写一个程序,让它来帮我们下载更多的验证码
下载验证码
编写一个下载验证码的程序DownloadYanZhengMa.py,这里我们只需要传入保存路径和要下载的数量就可以了。
# -*- coding:utf-8 -*-
import re
import uuid
import requests
import os
class DownloadYanZhengMa:
def __init__(self,save_path,download_max):
self.download_sum = 0
self.save_path = save_path
self.download_max = download_max
def downloadImages(self):
try:
pic = requests.get('http://jwsys.ctbu.edu.cn/CheckCode.aspx?', timeout=500)
pic_name = self.save_path+'/' +str(uuid.uuid1()) + '.png'
with open(pic_name, 'wb') as f:
f.write(pic.content)
self.download_sum += 1
print '已下载完成'+str(self.download_sum)+'张验证码'
if self.download_sum >= self.download_max:
return
else:
return self.downloadImages()
except Exception, e:
print '【错误】当前图片无法下载,%s' % e
return self.downloadImages()
if __name__ == '__main__':
downloadYanZhenMa = DownloadYanZhengMa(save_path='images/download_yanzhengma', download_max=1000)
downloadYanZhenMa.downloadImages()修改验证码的文件名
从上一个部分可以看到下载到images/download_yanzhengma文件夹中, 待下载完成之后,需要做以下几件事:
- 将每一张验证码命名为其对应的验证码内容,这是一个庞大的工作量
- 将命名好的验证码剪切到
images/src_yanzhengma/文件夹中
修改验证码的文件名是一个非常费时的工程,如果快速正确命名,那要发挥你们的想象力了,笔者同时也提供了数据集,这个不用担心. 正确命名是非常重要的, 在一个部分会讲到.
裁剪验证码
在数据集介绍的那部分,我们编写一个CorpYanZhengMa.py程序,让它来帮我们去裁剪所有的验证码,但是要注意一下几点:
- 验证码的命名一定要对于验证码的内容,这个非常重要
- 裁剪的验证码会单独存放在自己对应的文件夹中
# coding=utf-8
import os
import uuid
from PIL import Image
class YanZhenMaUtil():
def __init__(self):
pass
def splitimage(self,src, dstpath):
name = src.split('/')
name1 = name[name.__len__() - 1]
name2 = name1.split('.')[0]
l1 = list(name2)
img = Image.open(src)
box1 = (5, 0, 17, 27)
box2 = (17, 0, 29, 27)
box3 = (29, 0, 41, 27)
box4 = (41, 0, 53, 27)
path1 = dstpath + '/%s' % l1[0]
path2 = dstpath + '/%s' % l1[1]
path3 = dstpath + '/%s' % l1[2]
path4 = dstpath + '/%s' % l1[3]
if not os.path.exists(path1):
os.makedirs(path1)
if not os.path.exists(path2):
os.makedirs(path2)
if not os.path.exists(path3):
os.makedirs(path3)
if not os.path.exists(path4):
os.makedirs(path4)
img.crop(box1).save(path1 + '/%s.png' % uuid.uuid1())
img.crop(box2).save(path2 + '/%s.png' % uuid.uuid1())
img.crop(box3).save(path3 + '/%s.png' % uuid.uuid1())
img.crop(box4).save(path4 + '/%s.png' % uuid.uuid1())
if __name__ == '__main__':
root_path = 'images/src_yanzhengma/'
dstpath = 'images/dst_yanzhengma/'
imgs = os.listdir(root_path)
yanZhenMaUtil = YanZhenMaUtil()
for src in imgs:
src = root_path + src
yanZhenMaUtil.splitimage(src=src, dstpath=dstpath)例如经过上面裁剪,会生成这些文件夹,裁剪的图片会放在这里

你会发现只有33个文件夹,你应该会好奇10+26不应该是36个类别吗.因为验证码去掉了容易混淆的9,o,z,所以只剩下了33个类别.
生成图像列表
编写一个生成CreateDataList.py的程序,然后我们要把刚才的验证码生成一个图像列表,只有这个这里PaddlePaddle才能读取验证码数据,在自定义图像数据集的识别这一章有介绍,如果不了解的话可以阅读该文章。
这里就用到了上一个部分裁剪后的数据集,通过传入../images/dst_yanzhengma这个路径,会把之前裁剪好的所有图像都生成它的相对路径,给之后的训练程序使用.
# coding=utf-8
import os
import json
class CreateDataList:
def __init__(self):
pass
def createDataList(self, data_root_path):
# # 把生产的数据列表都放在自己的总类别文件夹中
data_list_path = ''
# 所有类别的信息
class_detail = []
# 获取所有类别
class_dirs = os.listdir(data_root_path)
# 类别标签
class_label = 0
# 获取总类别的名称
father_paths = data_root_path.split('/')
while True:
if father_paths[father_paths.__len__() - 1] == '':
del father_paths[father_paths.__len__() - 1]
else:
break
father_path = father_paths[father_paths.__len__() - 1]
all_class_images = 0
# 读取每个类别
for class_dir in class_dirs:
# 每个类别的信息
class_detail_list = {}
test_sum = 0
trainer_sum = 0
# 把生产的数据列表都放在自己的总类别文件夹中
data_list_path = "../data/%s/" % father_path
# 统计每个类别有多少张图片
class_sum = 0
# 获取类别路径
path = data_root_path + "/" + class_dir
# 获取所有图片
img_paths = os.listdir(path)
for img_path in img_paths:
# 每张图片的路径
name_path = path + '/' + img_path
# 如果不存在这个文件夹,就创建
isexist = os.path.exists(data_list_path)
if not isexist:
os.makedirs(data_list_path)
# 每10张图片取一个做测试数据
if class_sum % 10 == 0:
test_sum += 1
with open(data_list_path + "test.list", 'a') as f:
f.write(name_path + "\t%d" % class_label + "\n")
else:
trainer_sum += 1
with open(data_list_path + "trainer.list", 'a') as f:
f.write(name_path + "\t%d" % class_label + "\n")
class_sum += 1
all_class_images += 1
class_label += 1
# 说明的json文件的class_detail数据
class_detail_list['class_name'] = class_dir
class_detail_list['class_label'] = class_label
class_detail_list['class_test_images'] = test_sum
class_detail_list['class_trainer_images'] = trainer_sum
class_detail.append(class_detail_list)
# 获取类别数量
all_class_sum = class_dirs.__len__()
# 说明的json文件信息
readjson = {}
readjson['all_class_name'] = father_path
readjson['all_class_sum'] = all_class_sum
readjson['all_class_images'] = all_class_images
readjson['class_detail'] = class_detail
jsons = json.dumps(readjson, sort_keys=True, indent=4, separators=(',', ': '))
with open(data_list_path + "readme.json",'w') as f:
f.write(jsons)
if __name__ == '__main__':
createDataList = CreateDataList()
createDataList.createDataList('../images/dst_yanzhengma')通过上面的程序,一共会生成trainer.list,test.list,readme.json,其中trainer.list,test.list分布是用来训练和测试的,readme.json这个在这里就非常重要了。它会通过标签寻找的对用的字符。readme.json的格式如下:
{
"all_class_images": 3300,
"all_class_name": "vegetables",
"all_class_sum": 3,
"class_detail": [
{
"class_label": 1,
"class_name": "cuke",
"class_test_images": 110,
"class_trainer_images": 990
}
}读取数据
因为是使用自定义数据集,所以同样使用到reader.py这程序,但是这次又点不一样,这次使用的单通道的灰度图,所以我们的参数要变一变,把is_color的参数变成False,因为默认的是True.从官方文档可以了解到这些
paddle.v2.image.simple_transform(im,resize_size,crop_size,is_train,is_color = True,mean = None )参数:
- im(ndarray) - HWC布局的输入图像。
- resize_size(int) - 调整大小的图像的较短边缘长度。
- crop_size(int) - 裁剪尺寸。
- is_train(bool) - 是否训练。
- is_color(bool) - 图像是否是彩色的。
- mean(numpy array | list) - 平均值,可以是每个通道的元素平均值或平均值。
MyReader代码
为了做一下区分,我把命名改成了MyReade.py,在旧版本的该程序是有bug的,如果读者想使用这个程序,想要更新本地PaddlePaddle的版本,旧版本的bug是没有对灰度的图像处理,所以在做这个灰度的验证码时会报错。
# coding=utf-8
from multiprocessing import cpu_count
import paddle.v2 as paddle
class MyReader:
def __init__(self, imageSize):
self.imageSize = imageSize
def train_mapper(self, sample):
img, label = sample
# 我这里使用的是本地的image,如果你的paddlepaddle是最新的,也可以使用padd.v2.image
# 因为是灰度图,所以is_color=False
img = paddle.image.load_image(img, is_color=False)
img = paddle.image.simple_transform(img, 38, self.imageSize, True, is_color=False)
return img.flatten().astype('float32'), label
def test_mapper(self, sample):
img, label = sample
# 我这里使用的是本地的image,如果你的paddlepaddle是最新的,也可以使用padd.v2.image
# 因为是灰度图,所以is_color=False
img = paddle.image.load_image(img, is_color=False)
img = paddle.image.simple_transform(img, 38, self.imageSize, False, is_color=False)
return img.flatten().astype('float32'), label
def train_reader(self, train_list, buffered_size=1024):
def reader():
with open(train_list, 'r') as f:
lines = [line.strip() for line in f]
for line in lines:
img_path, lab = line.strip().split('\t')
yield img_path, int(lab)
return paddle.reader.xmap_readers(self.train_mapper, reader,
cpu_count(), buffered_size)
def test_reader(self, test_list, buffered_size=1024):
def reader():
with open(test_list, 'r') as f:
lines = [line.strip() for line in f]
for line in lines:
img_path, lab = line.strip().split('\t')
yield img_path, int(lab)
return paddle.reader.xmap_readers(self.test_mapper, reader,
cpu_count(), buffered_size)使用PaddlePaddle开始训练
同样在开始训练的前,要定义一个神经网络vgg.py,我们这次使用的还是前面两章使用到的VGG16的神经网络模型,在这里我同样是把BN层关闭了,至于为什么,可以查看之前的文章:
# coding:utf-8
import paddle.v2 as paddle
# ***********************定义VGG卷积神经网络模型***************************************
def vgg_bn_drop(datadim, type_size):
image = paddle.layer.data(name="image",
type=paddle.data_type.dense_vector(datadim))
def conv_block(ipt, num_filter, groups, dropouts, num_channels=None):
return paddle.networks.img_conv_group(
input=ipt,
num_channels=num_channels,
pool_size=2,
pool_stride=2,
conv_num_filter=[num_filter] * groups,
conv_filter_size=3,
conv_act=paddle.activation.Relu(),
conv_with_batchnorm=False,
conv_batchnorm_drop_rate=dropouts,
pool_type=paddle.pooling.Max())
# 最后一个参数是图像的通道数
conv1 = conv_block(image, 64, 2, [0.3, 0], 1)
conv2 = conv_block(conv1, 128, 2, [0.4, 0])
conv3 = conv_block(conv2, 256, 3, [0.4, 0.4, 0])
conv4 = conv_block(conv3, 512, 3, [0.4, 0.4, 0])
conv5 = conv_block(conv4, 512, 3, [0.4, 0.4, 0])
drop = paddle.layer.dropout(input=conv5, dropout_rate=0.5)
fc1 = paddle.layer.fc(input=drop, size=512, act=paddle.activation.Linear())
bn = paddle.layer.batch_norm(input=fc1,
act=paddle.activation.Relu(),
layer_attr=paddle.attr.Extra(drop_rate=0.5))
fc2 = paddle.layer.fc(input=bn, size=512, act=paddle.activation.Linear())
# 通过Softmax获得分类器
out = paddle.layer.fc(input=fc2,
size=type_size,
act=paddle.activation.Softmax())
return out然后创建一个train.py编写以下代码:
导入依赖包
首先要先导入依赖包,其中有PaddlePaddle的V2包和上面定义的Myreader.py读取数据的程序
# coding:utf-8
import sys
import os
import paddle.v2 as paddle
from MyReader import MyReader
from vgg import vgg_bn_drop
from cnn import convolutional_neural_network初始化Paddle
然后我们创建一个类,再在类中创建一个初始化函数,在初始化函数中来初始化我们的PaddlePaddle
class PaddleUtil:
def __init__(self):
# 初始化paddpaddle,只是用CPU,把GPU关闭
paddle.init(use_gpu=False, trainer_count=2)程序默认给出的是VGG16网络神经模型,还记得我们在手写数字识别使用的卷积神经网络LeNet-5吧,这里笔者也提供LeNet-5的神经网络模型cnn.py:
# coding:utf-8
import paddle.v2 as paddle
# 卷积神经网络LeNet-5,获取分类器
def convolutional_neural_network(datadim, type_size):
image = paddle.layer.data(name="image",
type=paddle.data_type.dense_vector(datadim))
# 第一个卷积--池化层
conv_pool_1 = paddle.networks.simple_img_conv_pool(input=image,
filter_size=5,
num_filters=20,
num_channel=1,
pool_size=2,
pool_stride=2,
act=paddle.activation.Relu())
# 第二个卷积--池化层
conv_pool_2 = paddle.networks.simple_img_conv_pool(input=conv_pool_1,
filter_size=5,
num_filters=50,
num_channel=20,
pool_size=2,
pool_stride=2,
act=paddle.activation.Relu())
# 以softmax为激活函数的全连接输出层
out = paddle.layer.fc(input=conv_pool_2,
size=type_size,
act=paddle.activation.Softmax())
return out如果要使用LeNet-5,只要把
out = self.vgg_bn_drop(input=image, type_size=type_size)改成
out = self.convolutional_neural_network(input=image, type_size=type_size)同时要把训练优化方法改成以下方法就可以了
optimizer = paddle.optimizer.Momentum(learning_rate=0.00001 / 128.0,
momentum=0.9,
regularization=paddle.optimizer.L2Regularization(rate=0.005 * 128))要提醒的是,为了让网络能够收敛,我把学习率调了很低,所以训练收敛会非常慢.
获取参数
该函数可以通过输入是否是参数文件路径,或者是损失函数,如果是参数文件路径,就使用之前训练好的参数生产参数.
如果不传入参数文件路径,那就使用传入的损失函数生成参数
def get_parameters(self, parameters_path=None, cost=None):
if not parameters_path:
# 使用cost创建parameters
if not cost:
raise NameError('请输入cost参数')
else:
# 根据损失函数创建参数
parameters = paddle.parameters.create(cost)
print "cost"
return parameters
else:
# 使用之前训练好的参数
try:
# 使用训练好的参数
with open(parameters_path, 'r') as f:
parameters = paddle.parameters.Parameters.from_tar(f)
print "使用parameters"
return parameters
except Exception as e:
raise NameError("你的参数文件错误,具体问题是:%s" % e)创建训练器
创建训练器要3个参数,分别是损失函数,参数,优化方法.
通过图像的标签信息和分类器生成损失函数.
参数可以选择是使用之前训练好的参数,然后在此基础上再进行训练,又或者是使用损失函数生成初始化参数.
然后再生成优化方法.就可以创建一个训练器了.
# datadim 数据大小
def get_trainer(self, datadim, type_size, parameters_path):
# 获得图片对于的信息标签
label = paddle.layer.data(name="label",
type=paddle.data_type.integer_value(type_size))
# 获取全连接层,也就是分类器
out = vgg_bn_drop(datadim=datadim, type_size=type_size)
# 获得损失函数
cost = paddle.layer.classification_cost(input=out, label=label)
# 获得参数
if not parameters_path:
parameters = self.get_parameters(cost=cost)
else:
parameters = self.get_parameters(parameters_path=parameters_path)
'''
定义优化方法
learning_rate 迭代的速度
momentum 跟前面动量优化的比例
regularzation 正则化,防止过拟合
'''
# ********************如果使用VGG网络模型就用这个优化方法******************
optimizer = paddle.optimizer.Momentum(
momentum=0.9,
regularization=paddle.optimizer.L2Regularization(rate=0.0005 * 128),
learning_rate=0.0001 / 128,
learning_rate_decay_a=0.1,
learning_rate_decay_b=128000 * 35,
learning_rate_schedule="discexp", )
# ********************如果使用LeNet-5网络模型就用这个优化方法******************
# optimizer = paddle.optimizer.Momentum(learning_rate=0.00001 / 128.0,
# momentum=0.9,
# regularization=paddle.optimizer.L2Regularization(rate=0.005 * 128))
'''
创建训练器
cost 分类器
parameters 训练参数,可以通过创建,也可以使用之前训练好的参数
update_equation 优化方法
'''
trainer = paddle.trainer.SGD(cost=cost,
parameters=parameters,
update_equation=optimizer)
return trainer开始训练
我们把图片设置成灰度图来处理了,所以数据集也非常小。所以相对之前训练CIFAR数据集来说,训练起来还算挺快的。
# ***********************开始训练***************************************
def start_trainer(self, trainer, num_passes, save_parameters_name, trainer_reader, test_reader):
# 获得数据
reader = paddle.batch(reader=paddle.reader.shuffle(reader=trainer_reader,
buf_size=50000),
batch_size=128)
# 保证保存模型的目录是存在的
father_path = save_parameters_name[:save_parameters_name.rfind("/")]
if not os.path.exists(father_path):
os.makedirs(father_path)
# 指定每条数据和padd.layer.data的对应关系
feeding = {"image": 0, "label": 1}
# 定义训练事件
def event_handler(event):
if isinstance(event, paddle.event.EndIteration):
if event.batch_id % 100 == 0:
print "\nPass %d, Batch %d, Cost %f, %s" % (
event.pass_id, event.batch_id, event.cost, event.metrics)
else:
sys.stdout.write('.')
sys.stdout.flush()
# 每一轮训练完成之后
if isinstance(event, paddle.event.EndPass):
# 保存训练好的参数
with open(save_parameters_name, 'w') as f:
trainer.save_parameter_to_tar(f)
# 测试准确率
result = trainer.test(reader=paddle.batch(reader=test_reader,
batch_size=128),
feeding=feeding)
print "\nTest with Pass %d, %s" % (event.pass_id, result.metrics)
'''
开始训练
reader 训练数据
num_passes 训练的轮数
event_handler 训练的事件,比如在训练的时候要做一些什么事情
feeding 说明每条数据和padd.layer.data的对应关系
'''
trainer.train(reader=reader,
num_passes=num_passes,
event_handler=event_handler,
feeding=feeding)然后在main中调用相应的函数,就可以开始训练了
if __name__ == '__main__':
# 类别总数
type_size = 33
# 图片大小
imageSize = 32
# 总的分类名称
all_class_name = 'dst_yanzhengma'
# 保存的model路径
parameters_path = "../model/model.tar"
# 数据的大小
datadim = imageSize * imageSize
paddleUtil = PaddleUtil()
# *******************************开始训练**************************************
myReader = MyReader(imageSize=imageSize)
# parameters_path设置为None就使用普通生成参数,
trainer = paddleUtil.get_trainer(datadim=datadim, type_size=type_size, parameters_path=parameters_path)
trainer_reader = myReader.train_reader(train_list="../data/%s/trainer.list" % all_class_name)
test_reader = myReader.test_reader(test_list="../data/%s/test.list" % all_class_name)
paddleUtil.start_trainer(trainer=trainer, num_passes=100, save_parameters_name=parameters_path,
trainer_reader=trainer_reader, test_reader=test_reader)训练输出的日志:
Pass 0, Batch 0, Cost 3.684595, {'classification_error_evaluator': 0.9765625}
........................................
Test with Pass 0, {'classification_error_evaluator': 0.930390477180481}
Pass 1, Batch 0, Cost 3.523515, {'classification_error_evaluator': 0.953125}
........................................
Test with Pass 1, {'classification_error_evaluator': 0.8862478733062744}使用PaddlePaddle预测
编写infer.py做验证码预测,这次预测要做的事情比较多.
因为传进来的是一个完整的验证码,所以首先要对验证码进行裁剪.
然后把裁剪后的数据传该PaddlePaddle进行预测.
预测出来的是一个label值,所以还有通过label找到对应的字符
裁剪要预测的验证码
# *****************获取你要预测的参数********************************
def get_TestData(path, imageSize):
test_data = []
img = Image.open(path)
# 切割图片并保存
box1 = (5, 0, 17, 27)
box2 = (17, 0, 29, 27)
box3 = (29, 0, 41, 27)
box4 = (41, 0, 53, 27)
temp = '../images/temp'
img.crop(box1).resize((32, 32), Image.ANTIALIAS).save(temp + '/1.png')
img.crop(box2).resize((32, 32), Image.ANTIALIAS).save(temp + '/2.png')
img.crop(box3).resize((32, 32), Image.ANTIALIAS).save(temp + '/3.png')
img.crop(box4).resize((32, 32), Image.ANTIALIAS).save(temp + '/4.png')
# 把图像加载到预测数据中
test_data.append((image.load_and_transform(temp + '/1.png', 38, imageSize, False, is_color=False)
.flatten().astype('float32'),))
test_data.append((image.load_and_transform(temp + '/2.png', 38, imageSize, False, is_color=False)
.flatten().astype('float32'),))
test_data.append((image.load_and_transform(temp + '/3.png', 38, imageSize, False, is_color=False)
.flatten().astype('float32'),))
test_data.append((image.load_and_transform(temp + '/4.png', 38, imageSize, False, is_color=False)
.flatten().astype('float32'),))
return test_data使用裁剪好的图像进行预测
def to_prediction(test_data, parameters, out, all_class_name):
with open('../data/%s/readme.json' % all_class_name) as f:
txt = f.read()
# 获得预测结果
probs = paddle.infer(output_layer=out,
parameters=parameters,
input=test_data)
# 处理预测结果
lab = np.argsort(-probs)
# 返回概率最大的值和其对应的概率值
result = ''
for i in range(0, lab.__len__()):
print '第%d张预测结果为:%d,可信度为:%f' % (i + 1, lab[i][0], probs[i][(lab[i][0])])
result = result + lab_to_result(lab[i][0], txt)
return str(result)把预测的label转换成对应的字符
def lab_to_result(lab, json_str):
myjson = json.loads(json_str)
class_details = myjson['class_detail']
for class_detail in class_details:
if class_detail['class_label'] == lab:
return class_detail['class_name']然后通过以上的程序拼接,最后在main入口中调用对应的程序就可以预测验证码了
if __name__ == '__main__':
# 类别总数
type_size = 33
# 图片大小
imageSize = 32
# 总的分类名称
all_class_name = 'dst_yanzhengma'
# 保存的model路径
parameters_path = "../model/model.tar"
# 数据的大小
datadim = imageSize * imageSize
out = get_out(datadim=datadim, type_size=type_size)
parameters = get_parameters(parameters_path=parameters_path)
# 添加数据
test_data = paddleUtil.get_TestData("../images/src_yanzhengma/0a13.png", imageSize=imageSize)
result = paddleUtil.to_prediction(test_data=test_data,
parameters=parameters,
out=out,
all_class_name=all_class_name)
print '预测结果为:%s' % result预测结果输出
第1张预测结果为:0,可信度为:0.966999
第2张预测结果为:9,可信度为:0.664706
第3张预测结果为:1,可信度为:0.780999
第4张预测结果为:3,可信度为:0.959722
预测结果为:0a13项目代码
GitHub地址:https://github.com/yeyupiaoling/LearnPaddle