目前语音识别主流是基于WFST解码器,WFST中的优化操作如Determinization,Minimization,Weight Pushing 使得Viterbi解码速度大大加快。 然而实际语音识别的问题还有很多,第一,往往基于静态的HCLG.fst 可能非常大,需要消耗大量内存;第二,静态的HCLG.fst 非常大,一旦语言模型G.fst或者 HMM模型H.fst, Context phones C.fst, 词典L.fst 需要微小的变动,需要重新构建整个HCLG.fst。
为了解决上述问题,我们将介绍如何在动态的HCLG.fst中进行解码。
我们简要介绍主流的两种动态解码方式,即look-ahead composition 和 on-the-fly rescoring。
1. Look-Ahead Composition
这种方式和静态解码十分类似,因为HCLG.fst过于庞大,我们在内存只构建G.fst 和HCL.fst,在解码时需要的时候边compose边解码,即采用lazy 的方式,需要时解码时需要某一state才进行compose算法展开。
但直接这样做速度上存在严重问题,主要有两个。第一个:和静态HCLG.fst事先优化压缩不同,动态构建的HCLG会有大量redundant path,这样解码时会搜索大量无效路径或者说遍历dead states。第二个:没有weight push 操作,这样只有在遇到word label的时候才有非0的权重,与静态HCLG相比,不能提前排除一些分数较低的路径,beam search的速度受到严重影响。我们介绍的look-ahead composition就解决了上述两种问题。大致和generic composition一样,不过我们引入一个新的概念 prospective labels。 prospective labels也就是从每个states出发可以到达non-epsilon label的集合,如下图例子,矩形框内即为当前state的prospective labels。 Li (p) and Lo(p) 即为状态p的输入prospective labels和输出prospective labels。
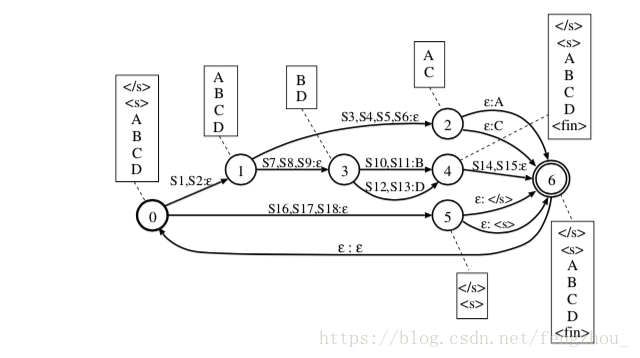
因此我们在compose的时候只有当Li (p1) and Lo(p2)有交集的时候才合并,没有交集说明之后无法到达final states,当前states是dead states,这样避免了无效的路径搜索。
对于weight pushing的问题,我们同样引入look-ahead weights,这样就能计算future label的weights,提前进行权重的判断,达到weight pushing相同的目的。
上述算法在实际事先过程和generic composition类似,把look-ahead做成filter(Label reachability filter with weight pushing),将此filter和 Epsilon sequencing filter合并就完成了这一算法。对generic composition不了解的童鞋可以看我的这篇博客《语音识别WFST核心算法讲解(2. Generic Composition)》
上述只是简要介绍,实际过程判断Li (p1) and Lo(p2)是否有交集,如果直接判断,复杂度很高,这里引入interval representation,即对HCL 的ilabel进行relabel,使的state的prospective labels在一个interval中,即 ∀ label ∈ Lo(p1), bo(p1) ≤ label< eo(p1)。这样直接判断区间是否相交即可,速度大大加快,relabel这一操作可以在解码前就做好,之后再relabel回去,这一问题被Allauzen et al.定义为Consecutive Ones Problem(C1P),这里不做详细介绍,有兴趣的童鞋可以去了解一下C1P。
2. On-the-fly Rescoring
这种方式采取的是incremental LMs。事先准备两个language model,Gm和Gn/m,使得最终的G = Gm ◦ Gn/m(◦ 表示compose, 当m=3表示 3-gram的语音模型, 通常m小于n)。
这样做使得之前静态的HCLG = HCLGm ◦ Gn/m 。主要流程是用较小的m和HCL做compose,构建一个小的静态网络,在解码的时候遇到一个word label,立刻rescore成大语言模型中Gn/m的weights。 这样做Viterbi解码只在第一个语音模型中,第二个高阶的语音模型的作用仅仅是对发现的路径(hypothesis)进行rescore,这样也是one pass解码,达到了提速的目的。这里具体的rescore 算法没有做详细讲解。
3. Look-Ahead Composition compares with On-the-fly Rescoring
总体而言,两者在速度和准确度上区别都不大,On-the-fly Rescoring在较小的WFST上做解码,空间上效率更高,而Look-Ahead Composition不需要rescore,也不需要做额外的incremental LMs。