原文地址: https://blog.csdn.net/xinghun_4/article/details/47907161
视频地址:Apache Mesos vs. Hadoop YARN #WhiteboardWalkthrough
总结:
1、最大的不同点在于他们所采用的scheduler:mesos让framework决定mesos提供的这个资源是否适合该job,从而接受或者拒绝这个资源。而对于yarn来说,决定权在于yarn,是yarn本身(自行替应用程序作主)决定这个资源是否适合该job,对于各种各样的应用程序来说或许这就是个错误的决定(这就是现代人为什么拒绝父母之命媒妁之言而选择自由婚姻的缘故吧)。所以从scaling的角度来说,mesos更scalable。
2、其次,yarn是MapReduce进化的产物,yarn从诞生之日起就是为hadoopjobs管理资源的(yarn也开始朝着mesos涉及的领域进军),yarn只为hadoop jobs提供了一个static partitioning。而mesos的设计目标是为各个框架(hadoop、spark、web services等)提供dynamical partitioning,让各个集群框架共用数据中心机器。
3、myriad项目将让yarn运行在mesos上面。
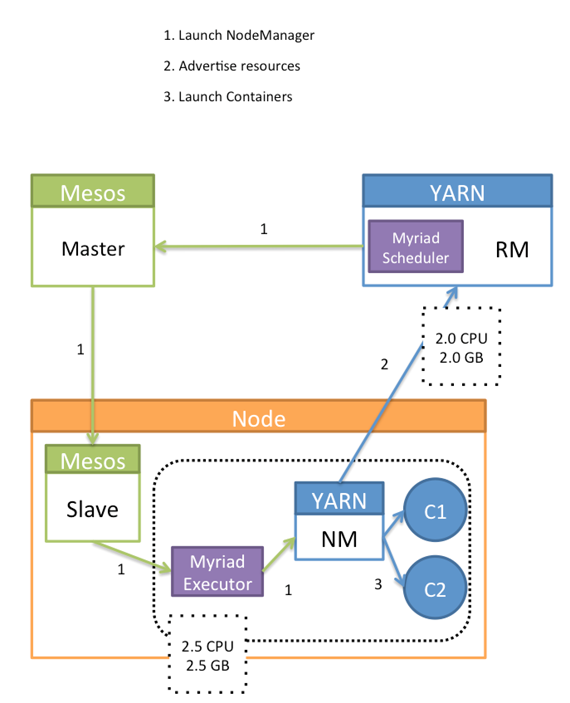
This open source software project is both a Mesos framework and a YARN scheduler that enables Mesos to manage YARN resource requests. When a job comes into YARN, it will schedule it via the Myriad Scheduler, which will match the request to incoming Mesos resource offers. Mesos, in turn, will pass it on to the Mesos worker nodes. The Mesos nodes will then communicate the request to a Myriad executor which is running the YARN node manager. Myriad launches YARN node managers on Mesos resources, which then communicate to the YARN resource manager what resources are available to them. YARN can then consume the resources as it sees fit. Myriad provides a seamless bridge from the pool of resources available in Mesos to the YARN tasks that want those resources.
The beauty of this approach is that not only does it allow you to elastically run YARN workloads on a shared cluster, but it actually makes YARN more dynamic and elastic than it was originally designed to be. This approach also makes it easy for a data center operations team to expand resources given to YARN (or, take them away as the case might be) without ever having to reconfigure the YARN cluster. It becomes very easy to dynamically control your entire data center. This model also provides an easy way to run and manage multiple YARN implementations, even different versions of YARN on the same cluster.
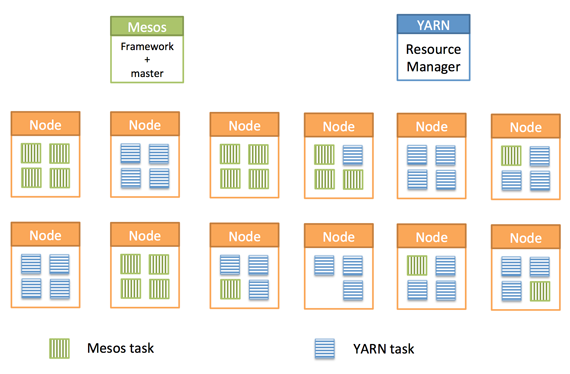
Resource sharing. Source: Mesosphere and MapR, used with permission.
Myriad blends the best of both the YARN and Mesos worlds. By utilizing Myriad, Mesos and YARN can collaborate, and you can achieve an as-it-happens business. Data analytics can be performed in-place on the same hardware that runs your production services. No longer will you face the resource constraints (and low utilization) caused by static partitions. Resources can be elastically reconfigured to meet the demands of the business as it happens.
下文最后Sumit Nigam的问题和Jim Scott的回答也很经典,通过一问一答形式Jim Scott道出了the scalability of a non-monolithic scheduling capacity。
下面是视频的内容:
Here's the video transcript:
Hi, my name is Jim Scott, Director of Enterprise Strategy and Architecture at MapR. Today I'd like to talk to you in this Whiteboard Walkthrough on Mesos versus YARN, and why one may or may not be better in global resource management than the other. There's a lot of contention in these two camps between the methods and the intentions of how to use these resource managers.
Mesos was built to be a global resource manager for your entire data center. YARN was created as a necessity to move the Hadoop MapReduce API to the next iteration and life cycle. It had to remove the resource management out of that embedded framework and into its own container management life cycle model, if you will.
The primary difference between Mesos and Yarn is going to be its scheduler. In Mesos, when a job comes in, a job request comes into the Mesos master, and what Mesos does is it determines what the resources are that are available, and it makes offers back. Those offers can be accepted or rejected.
This allows the framework to decide what the best fit is for the job that needs to be run. Now, if it accepts the job for the resources, it places the job on the slave and all is happy. It has the option to reject the offer and wait for another offer to come in. One of the nice things about this model is it is very scalable. This is a model that Google has proven, that they've documented. White papers are available for this that show the scalability of a non-monolithic scheduling capacity.
So what happens is when you move over to the YARN side, a job request comes into the YARN resource manager, and YARN evaluates all the resources available and it places the job. It's the one making the decision where jobs should go; thus it is modeled as a monolithic scheduler. So from a scaling perspective, Mesos has better scaling capabilities.
In addition to this, YARN, as I mentioned before, was created as a necessity for the evolutionary step of the MapReduce framework. What this means was that Yarn was created to be a resource manager for Hadoopjobs. YARN has tried to grow out of that and grow more into the space that Mesos is occupying so well.
In that model, what we want to consider here is that we have different scaling capabilities, and that the implementation between these two is going to be different, and that the people who put these in place had different intentions to start. This many make some impact in your decision for which to use.
What we have here is when you want to evaluate how to manage your data center as a whole, you've got Mesos on one side that can manage every single resource in your data center, and on the other you have YARN which can safely manage these Hadoop jobs. What that means for you is that right now,YARN is not capable of managing your entire data center. So the two of these are competing for the space, and in order for you to move along, if you want to benefit from both, this means you'll need to create, effectively, a static partition which means that so many resources will be allocated to YARN and so many resources will be allocated to Mesos. Fundamentally, this is an issue.This is the entire problem that Mesos was designed to prevent in the first place: static partitioning.
You've probably got a big task ahead of you to figure out which to use and where to use it. My hope is that I've given you enough information with respect to resource scheduling for you to move forward and ask more questions and figure out where to move in your global resource management for your data center.
The question is, can we make the two of these play together harmoniously for the sake of the benefit of the enterprise and the data center? Ultimately we have to ask, "Why can't we all just get along?" If we put politics aside, we can ask, "Can we make Mesos and YARN work together?" The answer is yes. MapR has worked in unison with eBay, Twitter, and Mesosphere to create a project called Project Myriad.Project Myriad's goal is to actually make the two of these work together.
What that means is that Mesos can manage your entire data center. With this open source software, it enables Mesos' Myriad executor to launch and manage YARN node managers. What happens is that when a job comes in to YARN, it will send the request to Mesos. Mesos in turn will pass it on to the Mesos slave, and then there is a Myriad executor that runs near the Yarn node manager and the Mesos slave. What it does is it advertises to the YARN node manager how many resources it has available.
The beauty of this approach is this actually makes YARN more dynamic, because it gives the resources to YARN that it wants to place where it sees fit. From the Mesos side, if you want to add or remove resources from YARN, it becomes very easy to dynamically control your entire data center.
The benefit here is that when you have your production operations being managed globally by Mesos, you can have the people on the data analytics since running their jobs in any fashion that they see fit via YARN for job placement. This means that dynamically, YARN will be limited in a production environment, and from a global perspective if you needed to take resources away, Hadoops resiliency with job placement will allow those jobs to be placed elsewhere on the cluster. You can kill instances of YARN and take back those resources to make them available to Mesos.
This really is the best of both worlds. It removes the static partitioning concept that running the two of these independently in a data center would create. The benefit overall is that Project Myriad is going to enable you to deploy both technologies in your data center. Leverage this for your data center resource management as a whole, leverage this to manage those Hadoop jobs where you may need them to just get deployed faster, where you don't care about the accept and reject capabilities of Mesos for those jobs, where data locality is your primary concern for Hadoop data only. This is an enabling technology that we hope that you will look into and evaluate if it's a fit for your company.
Project Myriad is hosted on GitHub and is available for download. There's documentation there that explains how this works. You'll probably even see diagrams similar to this, but probably a little prettier. Go out, explore, and give it a try.
That's all for this Whiteboard Walkthrough of Mesos vs YARN. If you have any questions about this topic, MapR is the open source leader for Mesos and YARN. Please feel free to contact us and ask us any questions on how to implement this in your business. Remember, if you've liked this and you'd like to suggest more topics, please comment below. Don't forget to follow us on Twitter @mapr #WhiteboardWalkthrough. Thank you.