Hadoop基础-MapReduce的Join操作
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.连接操作Map端Join(适合处理小表+大表的情况)


1 no001 12.3 7 2 no002 18.8 4 3 no003 20.0 3 4 no004 50.0 7 5 no005 23.1 2 6 no006 39.0 3 7 no007 5.0 2 8 no008 6.0 1
1 linghunbaiduren 2 yinzhengjie 3 alex 4 linhaifeng 5 wupeiqi 6 xupeicheng 7 changqiling 8 laowang
1>.MapJoinMapper.java 文件内容
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:[email protected] 5 */ 6 package cn.org.yinzhengjie.join.map; 7 8 import org.apache.hadoop.conf.Configuration; 9 import org.apache.hadoop.fs.FSDataInputStream; 10 import org.apache.hadoop.fs.FileSystem; 11 import org.apache.hadoop.fs.Path; 12 import org.apache.hadoop.io.IntWritable; 13 import org.apache.hadoop.io.LongWritable; 14 import org.apache.hadoop.io.NullWritable; 15 import org.apache.hadoop.io.Text; 16 import org.apache.hadoop.mapreduce.Mapper; 17 18 import java.io.BufferedReader; 19 import java.io.IOException; 20 import java.io.InputStreamReader; 21 import java.util.HashMap; 22 import java.util.Map; 23 24 25 /** 26 * 输出KeyValue 27 * key是组合后的数据 28 * value空 29 * 30 */ 31 public class MapJoinMapper extends Mapper<LongWritable,Text,Text,NullWritable> { 32 33 Map<Integer,String> map = new HashMap<Integer, String>(); 34 35 36 /** 37 * 38 *setup方法是在map方法之前执行,它也是map方法的初始化操作. 39 * 40 */ 41 @Override 42 protected void setup(Context context) throws IOException, InterruptedException { 43 //通过上下文,得到conf 44 Configuration conf = context.getConfiguration(); 45 //通过conf获取自定义key 46 String file = conf.get("customer.file"); 47 //读取customer数据 48 FileSystem fs = FileSystem.get(conf); 49 FSDataInputStream fis = fs.open(new Path(file)); 50 InputStreamReader reader = new InputStreamReader(fis); 51 BufferedReader br = new BufferedReader(reader); 52 String line = null; 53 byte[] buf = new byte[1024]; 54 while((line = br.readLine()) != null){ 55 String[] arr = line.split("\t"); 56 int id = Integer.parseInt(arr[0]); 57 String name = arr[1]; 58 //1 tom 59 //2 tomas 60 map.put(id,name); 61 } 62 } 63 64 /** 65 * 通过 66 * oid orderno price cid 67 * 8 no008 6.0 1 68 * 69 * 得到 70 * cid cname orderno price 71 * 1 tom no008 6.0 72 */ 73 74 @Override 75 protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { 76 77 String line = value.toString(); 78 79 String[] arr = line.split("\t"); 80 81 String orderno = arr[1]; 82 String price = arr[2]; 83 int cid = Integer.parseInt(arr[3]); 84 85 String name = map.get(cid); 86 //拼串操作 87 String outKey = cid + "\t" + name + "\t" + orderno + "\t" + price + "\t"; 88 // 89 context.write(new Text(outKey), NullWritable.get()); 90 } 91 }
2>.MapJoinApp.java 文件内容
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:[email protected] 5 */ 6 package cn.org.yinzhengjie.join.map; 7 8 import org.apache.hadoop.conf.Configuration; 9 import org.apache.hadoop.fs.FileSystem; 10 import org.apache.hadoop.fs.Path; 11 import org.apache.hadoop.io.NullWritable; 12 import org.apache.hadoop.io.Text; 13 import org.apache.hadoop.mapreduce.Job; 14 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 15 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 16 17 public class MapJoinApp { 18 19 public static void main(String[] args) throws Exception { 20 Configuration conf = new Configuration(); 21 //自定义一个变量名"customer.file",后面的文件是其具体的值,这里设置后可以在Mapper端通过get方法获取改变量的值。 22 conf.set("customer.file", "D:\\10.Java\\IDE\\yhinzhengjieData\\customers.txt"); 23 conf.set("fs.defaultFS","file:///"); 24 FileSystem fs = FileSystem.get(conf); 25 Job job = Job.getInstance(conf); 26 job.setJarByClass(MapJoinApp.class); 27 job.setJobName("Map-Join"); 28 job.setMapperClass(MapJoinMapper.class); 29 job.setOutputKeyClass(Text.class); 30 job.setOutputValueClass(NullWritable.class); 31 FileInputFormat.addInputPath(job,new Path("D:\\10.Java\\IDE\\yhinzhengjieData\\orders.txt")); 32 Path outPath = new Path("D:\\10.Java\\IDE\\yhinzhengjieData\\out"); 33 if (fs.exists(outPath)){ 34 fs.delete(outPath); 35 } 36 FileOutputFormat.setOutputPath(job,outPath); 37 job.waitForCompletion(true); 38 } 39 }
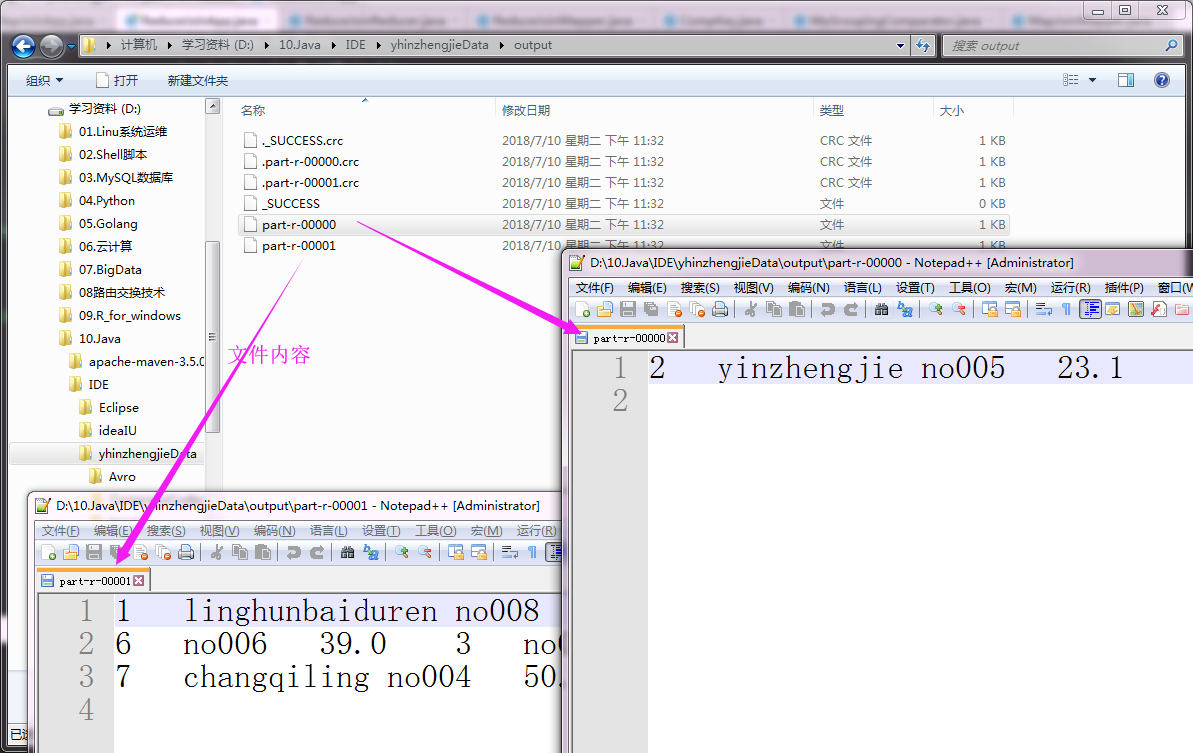
3>.验证结果是否正确

二.连接操作Reduce端Join之组合Key实现(适合处理大表+大表的情况)
1 no001 12.3 7 2 no002 18.8 4 3 no003 20.0 3 4 no004 50.0 7 5 no005 23.1 2 6 no006 39.0 3 7 no007 5.0 2 8 no008 6.0 1
1 linghunbaiduren 2 yinzhengjie 3 alex 4 linhaifeng 5 wupeiqi 6 xupeicheng 7 changqiling 8 laowang
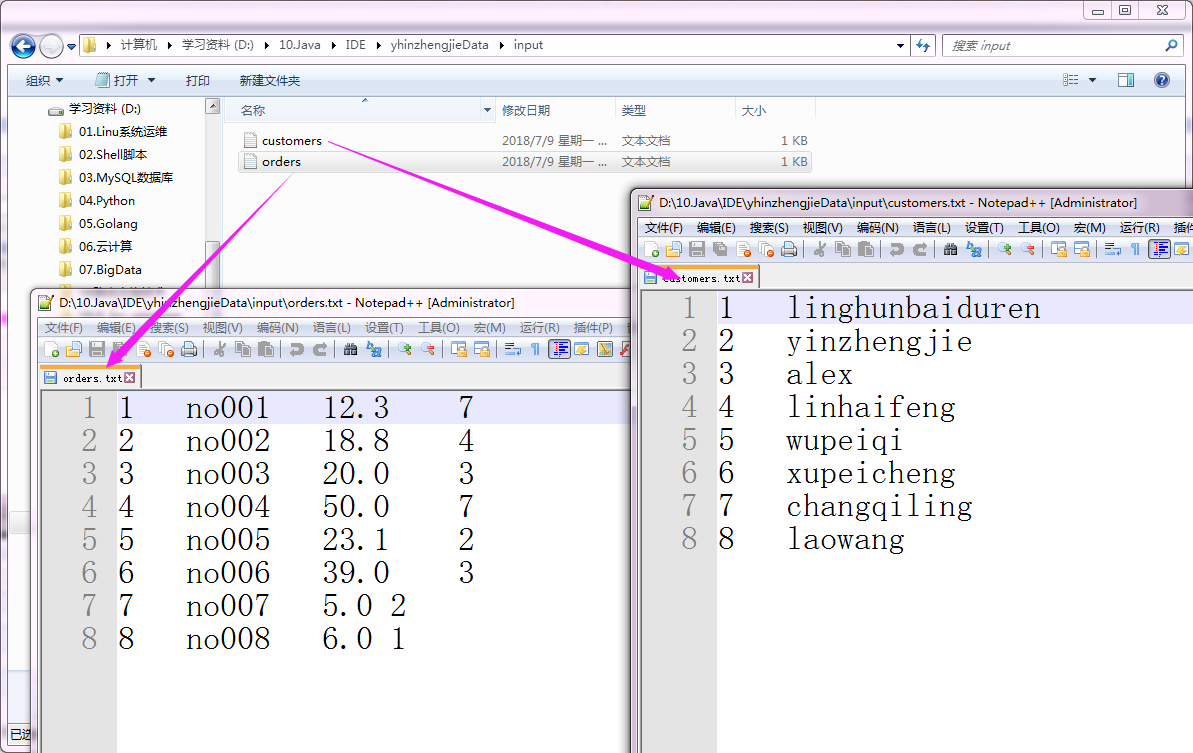
以上两个文件的指定路径如下:(输入路径)
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:[email protected] 5 */ 6 package cn.org.yinzhengjie.join.reduce; 7 8 import org.apache.hadoop.io.WritableComparable; 9 10 import java.io.DataInput; 11 import java.io.DataOutput; 12 import java.io.IOException; 13 14 public class CompKey implements WritableComparable<CompKey> { 15 //定义客户id 16 private int cid; 17 //定义标识 18 private int flag; 19 20 public int compareTo(CompKey o) { 21 //如果cid相等 22 if (this.getCid() == o.getCid()) { 23 //比较flag 24 return this.getFlag() - o.getFlag(); 25 } 26 return this.getCid() - o.getCid(); 27 } 28 29 //定义序列化 30 public void write(DataOutput out) throws IOException { 31 out.writeInt(cid); 32 out.writeInt(flag); 33 } 34 35 //定义反序列化 36 public void readFields(DataInput in) throws IOException { 37 cid = in.readInt(); 38 flag = in.readInt(); 39 } 40 41 public int getCid() { 42 return cid; 43 } 44 45 public void setCid(int cid) { 46 this.cid = cid; 47 } 48 49 public int getFlag() { 50 return flag; 51 } 52 53 public void setFlag(int flag) { 54 this.flag = flag; 55 } 56 57 @Override 58 public String toString() { 59 return cid + "," + flag; 60 } 61 }
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:[email protected] 5 */ 6 package cn.org.yinzhengjie.join.reduce; 7 8 import org.apache.hadoop.io.WritableComparable; 9 import org.apache.hadoop.io.WritableComparator; 10 11 public class MyGroupingComparator extends WritableComparator { 12 13 public MyGroupingComparator() { 14 super(CompKey.class, true); 15 } 16 17 @Override 18 public int compare(WritableComparable a, WritableComparable b) { 19 20 CompKey ck1 = (CompKey) a; 21 CompKey ck2 = (CompKey) b; 22 23 int cid1 = ck1.getCid(); 24 int cid2 = ck2.getCid(); 25 26 27 return cid1 - cid2; 28 } 29 }
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:[email protected] 5 */ 6 package cn.org.yinzhengjie.join.reduce; 7 8 import org.apache.hadoop.io.LongWritable; 9 import org.apache.hadoop.io.Text; 10 import org.apache.hadoop.mapreduce.InputSplit; 11 import org.apache.hadoop.mapreduce.Mapper; 12 import org.apache.hadoop.mapreduce.lib.input.FileSplit; 13 14 import java.io.IOException; 15 16 public class ReduceJoinMapper extends Mapper<LongWritable, Text, CompKey, Text> { 17 18 String fileName; 19 20 @Override 21 protected void setup(Context context) throws IOException, InterruptedException { 22 //得到输入切片 23 InputSplit split = context.getInputSplit(); 24 FileSplit fileSplit = (FileSplit) split; 25 26 //得到切片文件名或路径 27 fileName = fileSplit.getPath().getName(); 28 } 29 30 @Override 31 protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { 32 33 String line = value.toString(); 34 String[] arr = line.split("\t"); 35 36 //判断文件是否包含"customers"。 37 if (fileName.contains("customers")) { 38 int cid = Integer.parseInt(arr[0]); 39 CompKey ck = new CompKey(); 40 ck.setCid(cid); 41 ck.setFlag(0); 42 context.write(ck, value); 43 } else { 44 int cid = Integer.parseInt(arr[3]); 45 CompKey ck = new CompKey(); 46 ck.setCid(cid); 47 ck.setFlag(1); 48 context.write(ck, value); 49 } 50 } 51 }
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:[email protected] 5 */ 6 package cn.org.yinzhengjie.join.reduce; 7 8 import org.apache.hadoop.io.NullWritable; 9 import org.apache.hadoop.io.Text; 10 import org.apache.hadoop.mapreduce.Reducer; 11 12 import java.io.IOException; 13 import java.util.Iterator; 14 15 public class ReduceJoinReducer extends Reducer<CompKey, Text, Text, NullWritable> { 16 17 18 /** 19 * 通过 20 * oid orderno price cid 21 * 8 no008 6.0 1 22 * <p> 23 * 得到 24 * cid cname orderno price 25 * 1 tom no008 6.0 26 */ 27 @Override 28 protected void reduce(CompKey key, Iterable<Text> values, Context context) throws IOException, InterruptedException { 29 30 //初始化迭代器 31 Iterator<Text> it = values.iterator(); 32 33 //将while指针指向第一条之后 34 String cust = it.next().toString(); 35 36 //继上一条之后读取 37 while(it.hasNext()){ 38 String[] arr = it.next().toString().split("\t"); 39 String orderno = arr[1]; 40 String price = arr[2]; 41 String newLine = cust.toString() + "\t" + orderno + "\t" + price; 42 context.write(new Text(newLine), NullWritable.get()); 43 44 } 45 } 46 }
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:[email protected] 5 */ 6 package cn.org.yinzhengjie.join.reduce; 7 8 import org.apache.hadoop.conf.Configuration; 9 import org.apache.hadoop.fs.FileSystem; 10 import org.apache.hadoop.fs.Path; 11 import org.apache.hadoop.io.NullWritable; 12 import org.apache.hadoop.io.Text; 13 import org.apache.hadoop.mapreduce.Job; 14 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 15 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 16 17 public class ReduceJoinApp { 18 19 20 public static void main(String[] args) throws Exception { 21 Configuration conf = new Configuration(); 22 conf.set("fs.defaultFS","file:///"); 23 FileSystem fs = FileSystem.get(conf); 24 Job job = Job.getInstance(conf); 25 job.setJarByClass(ReduceJoinApp.class); 26 job.setJobName("Reduce-Join"); 27 job.setMapperClass(ReduceJoinMapper.class); 28 job.setReducerClass(ReduceJoinReducer.class); 29 job.setGroupingComparatorClass(MyGroupingComparator.class); 30 //map的输出k-v 31 job.setMapOutputKeyClass(CompKey.class); 32 job.setMapOutputValueClass(Text.class); 33 34 //reduce的k-v 35 job.setOutputKeyClass(Text.class); 36 job.setOutputValueClass(NullWritable.class); 37 38 //指定输入的文件路径 39 FileInputFormat.addInputPath(job,new Path("D:\\10.Java\\IDE\\yhinzhengjieData\\input\\")); 40 //指定输出的文件路径 41 Path outPath = new Path("D:\\10.Java\\IDE\\yhinzhengjieData\\output"); 42 if (fs.exists(outPath)){ 43 fs.delete(outPath); 44 } 45 FileOutputFormat.setOutputPath(job,outPath); 46 47 job.setNumReduceTasks(2); 48 job.waitForCompletion(true); 49 } 50 }
以上代码执行结果如下:(输出路径)