题记
在获取中文字符的时候,如果出现乱码的情况,我们需要了解当前的字符串的编码形式。使用下面两种方法可以判断字符串的编码形式。
法一:
isinstance(s, str) 用来判断是否为一般字符串
isinstance(s, unicode) 用来判断是否为unicode或
if type(str).__name__!="unicode":
str=unicode(str,"utf-8")
else:
pass法二:
Python chardet 字符编码判断
使用 chardet 可以很方便的实现字符串/文件的编码检测。尤其是中文网页,有的页面使用GBK/GB2312,有的使用UTF8,如果你需要去爬一些页面,知道网页编码很重要的,虽然HTML页面有charset标签,但是有些时候是不对的。那么chardet就能帮我们大忙了。
chardet 安装
下载chardet后,解压chardet压缩包,直接将chardet文件夹放在应用程序目录下,就可以使用import chardet开始使用chardet了。
或者使用setup.py安装文件,将chardet拷贝到Python系统目录下,这样你所有的python程序只要用import chardet就可以了。
python setup.py install参考
- chardet官网 http://chardet.feedparser.org/
- chardet下载页面:http://chardet.feedparser.org/download/
chardet实例
>>> import urllib
>>> rawdata = urllib.urlopen('http://www.google.cn/').read()
>>> import chardet
>>> chardet.detect(rawdata)
{'confidence': 0.98999999999999999, 'encoding': 'GB2312'}
>>>chardet可以直接用detect函数来检测所给字符的编码。函数返回值为字典,有2个元数,一个是检测的可信度,另外一个就是检测到的编码。 更多入门教程可以参考:[http://www.bugingcode.com/python_start/] (http://www.bugingcode.com/python_start/)
--------------------------------------
乱码原因:
因为你的文件声明为utf-8,并且也应该是用utf-8的编码保存的源文件。但是windows的本地默认编码是cp936,也就是gbk编码,所以在控制台
直接打印utf-8的字符串当然是乱码了。
解决方法:
在控制台打印的地方用一个转码就ok了,打印的时候这么写:
print myname.decode('UTF-8').encode('GBK')
比较通用的方法应该是:
import sys
type = sys.getfilesystemencoding()
print myname.decode('UTF-8').encode(type)
最近利用python抓取一些网上的数据,遇到了编码的问题。非常头痛,总结一下用到的解决方案。
- linux中vim下查看文件编码的命令 set fileencoding
- python中一个强力的编码检测包 chardet ,使用方法非常简单。linux下利用pip install chardet实现简单安装
|
1
2
3
4
|
import
chardet
f
=
open
(
'file'
,
'r'
)
fencoding
=
chardet.detect(f.read())
print
fencoding
|
fencoding输出格式 {'confidence': 0.96630842899499614, 'encoding': 'GB2312'} ,只能判断是否为某种编码的概率。比较准确的结果了。输入参数为str类型。
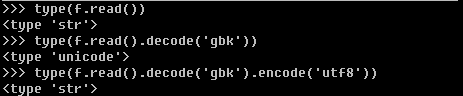
- 了解python中str的编码后可以利用decode和encode来实现编码的转换。
一般流程是str利用decode方法根据str的编码将其解码为unicode字符串类型,然后利用encode根据特定的编码将unicode字符串类型转换为特定的编码。python中str和unicode属于两种不同的类型,如下。
- 一般情况下window默认编码gbk,linux默认编码utf8
- python编程中 系统编码,python编码,文件编码 的概念。
系统编码:默认写源码的编辑器的编码方式。它代表源码文件内的所有内容都是根据词方式编码成二进制码流。存入到磁盘中的。linux下通过locale命令查看。
python编码:指python内设置的解码方式。如果不设定的话,python默认的是ascii解码方式。如果python源代码文件中不出现中文的话,这个地方怎么设定应该不会问题。
设定方法:在源码文件开头(一定是第一行):#-*-coding:UTF-8-*-,源码文件的设置解码方式是UTF-8 或者
|
1
2
3
|
import
sys
reload
(sys)
sys.setdefaultencoding(
'UTF-8'
)
|
文件编码:文本的编码方式,linux下vim利用set fileencoding查看。
- 一般情况下输出乱码的原因就是 没有按照系统解码的方式进行编码。
比如print s, s类型为str,linux系统下系统默认编码为utf8编码,s在输出前就应该编码为utf8。如果s为gbk编码就应该这样输出。print s.decode('gbk').encode('utf8')才能输出中文。
window下面情况相同,window默认编码为gbk编码,所以s输出前必须编码为gbk。
- python处理中一般处理unicode类型。这样输出前直接编码即可。
---------------------------
Python 中文编码
前面章节中我们已经学会了如何用 Python 输出 "Hello, World!",英文没有问题,但是如果你输出中文字符"你好,世界"就有可能会碰到中文编码问题。
Python 文件中如果未指定编码,在执行过程会出现报错:
#!/usr/bin/python print "你好,世界";
以上程序执行输出结果为:
File "test.py", line 2 SyntaxError: Non-ASCII character '\xe4' in file test.py on line 2, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details
Python中默认的编码格式是 ASCII 格式,在没修改编码格式时无法正确打印汉字,所以在读取中文时会报错。
解决方法为只要在文件开头加入 # -*- coding: UTF-8 -*- 或者 #coding=utf-8 就行了
注意:#coding=utf-8 的 = 号两边不要空格。
输出结果为:
你好,世界
所以如果大家在学习过程中,代码中包含中文,就需要在头部指定编码。
注意:Python3.X 源码文件默认使用utf-8编码,所以可以正常解析中文,无需指定 UTF-8 编码。
注意:如果你使用编辑器,同时需要设置 py 文件存储的格式为 UTF-8,否则会出现类似以下错误信息:
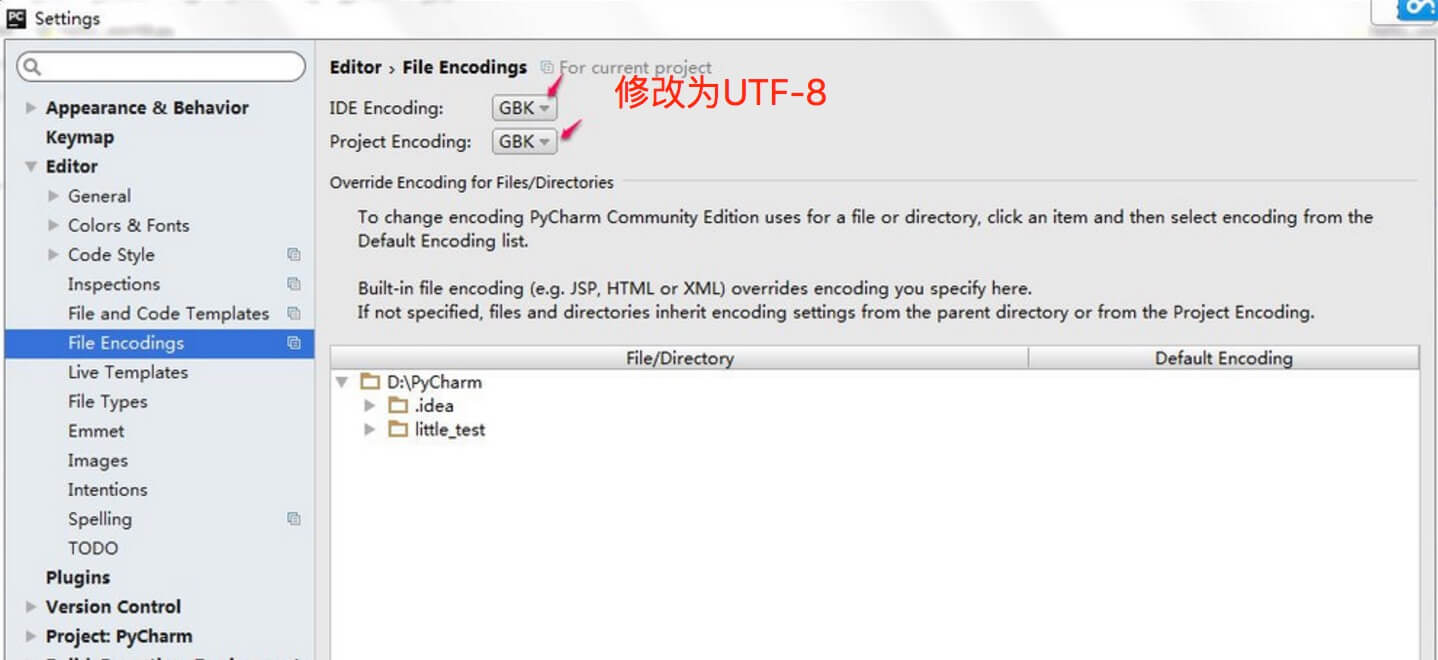
SyntaxError: (unicode error) ‘utf-8’ codec can’t decode byte 0xc4 in position 0: invalid continuation bytePycharm 设置步骤:
- 进入 file > Settings,在输入框搜索 encoding。
- 找到 Editor > File encodings,将 IDE Encoding 和 Project Encoding 设置为utf-8。