Hadoop Examples
Hadoop 自带了MapReduce 的 Examples 等程序(hadoop-mapreduce-examples), 当下载 hadoop源码 后,网上有很多介绍搭建环境并进行调试的文章。但大部分是将 WordCount.java 等程序打包成 jar 文件后,通过 org.apache.hadoop.util.Runjar 类运行并调试。
但实际上,hadoop-mapreduce-examples 中提供的每个示例程序都有main函数,而且通过pom.xml已经设置好了依赖关系,如果能直接调试运行那些程序,岂不是最方便。
问题分析和解决步骤(授人以渔)
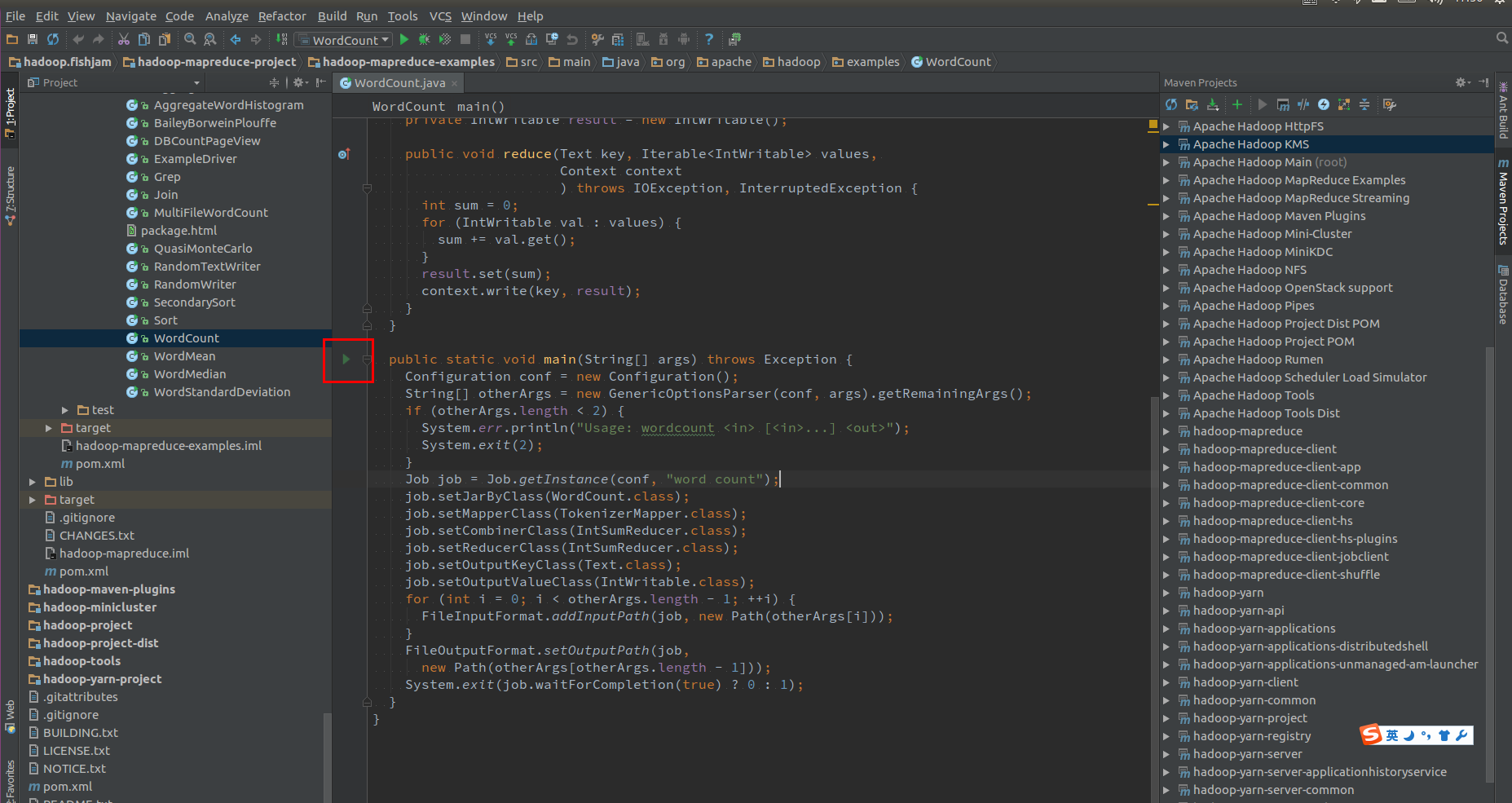
使用 Idea 打开 hadoop-mapreduce-examples 或 hadoop 的POM工程后,打开 hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/WordCount.java 文件,直接点击main函数前面表示运行 “>” 的 Gutter Icons(如图1):
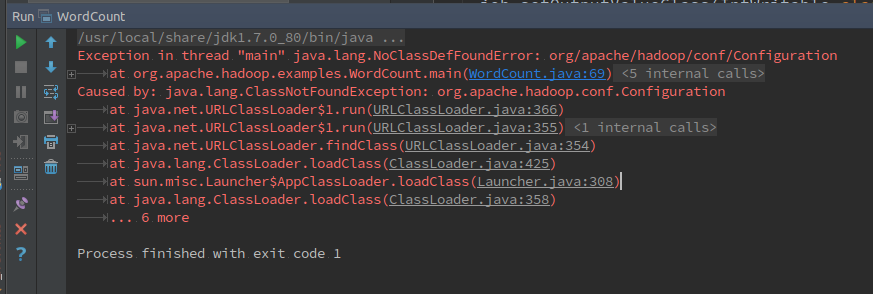
通常,这个时候不会运行成功,会提示如图2所示的“NoClassDefFoundError”等错误,很多人就认为Map/Reduce 程序只能在Hadoop框架中运行,直接放弃。
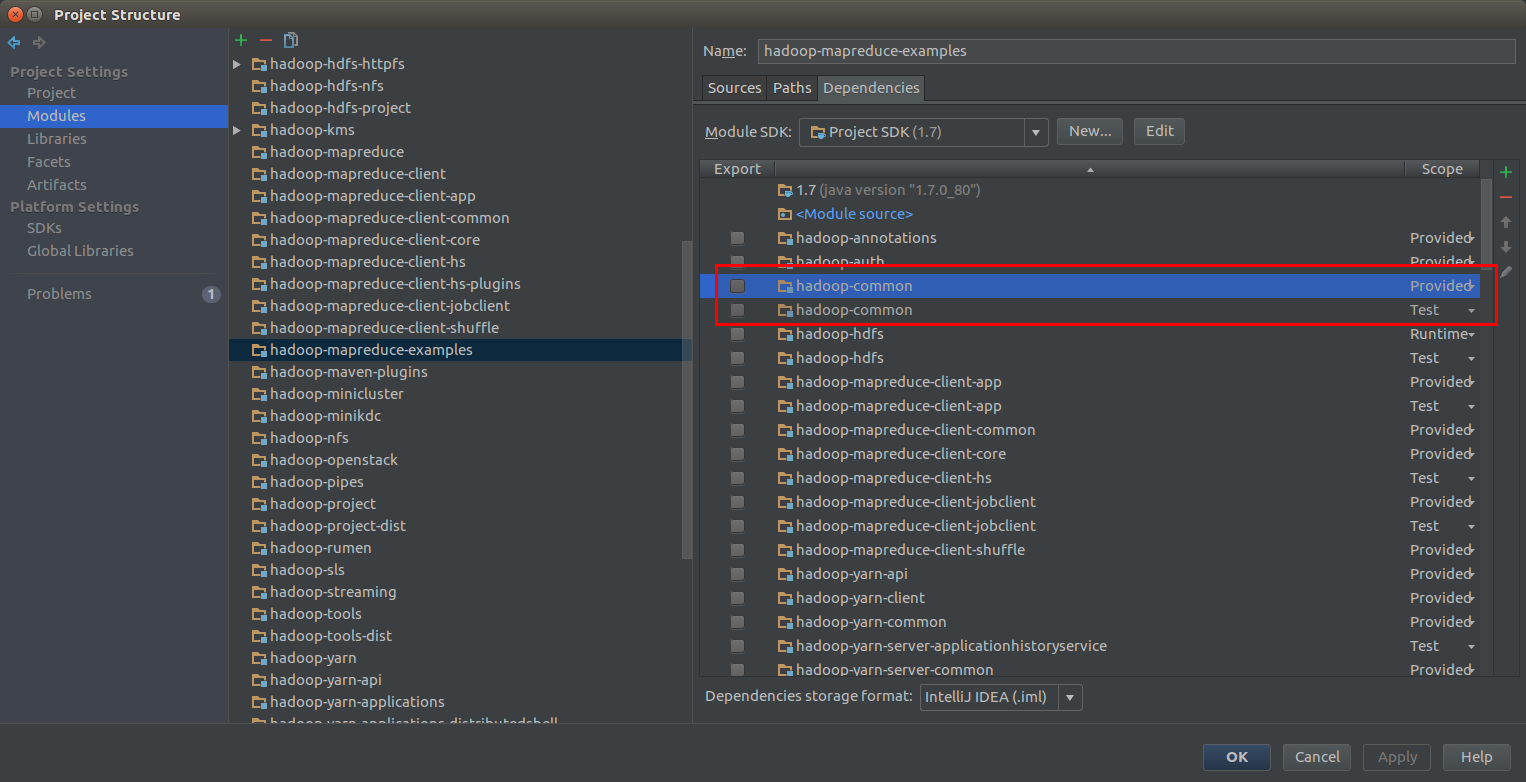
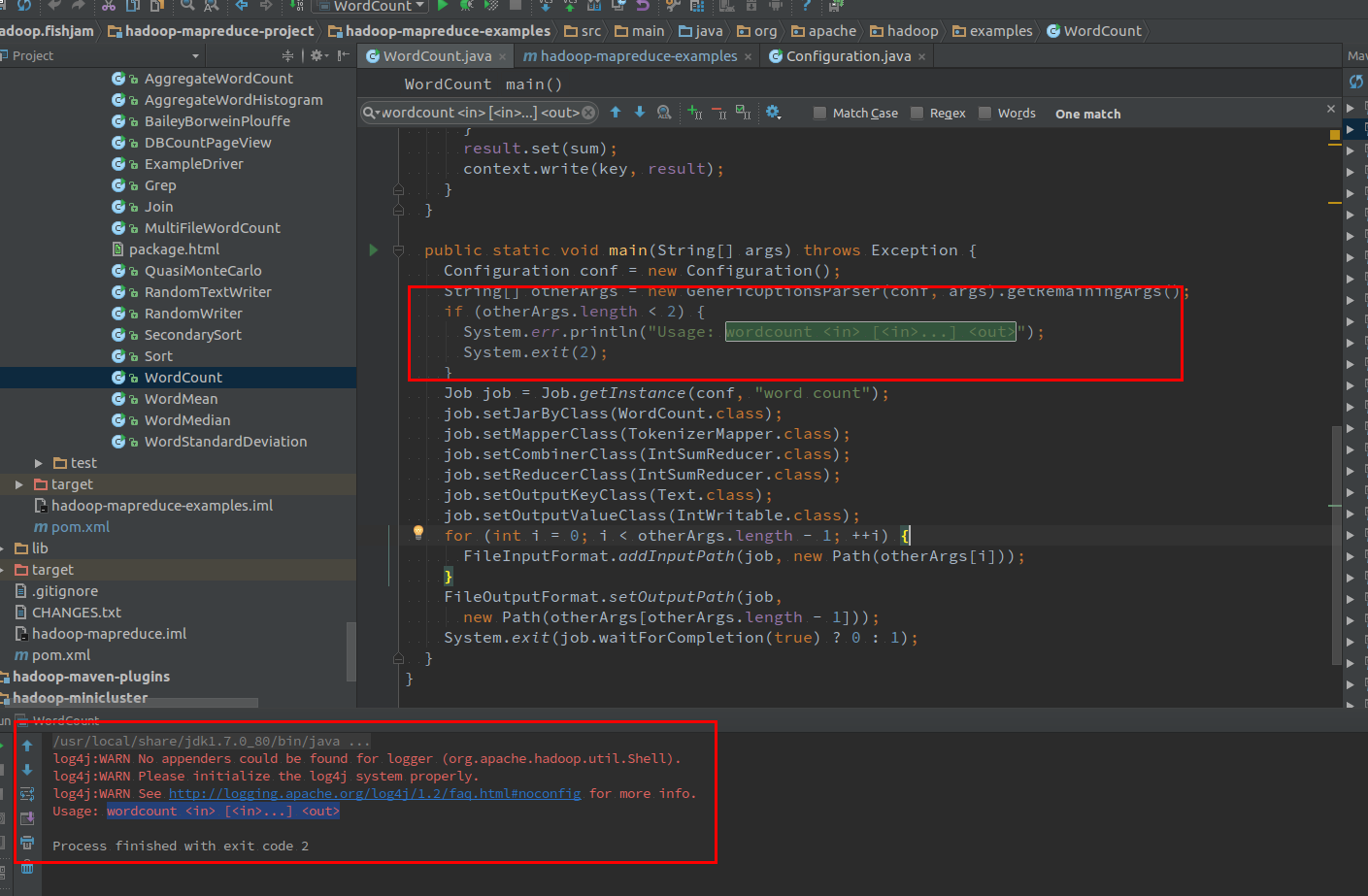
仔细分析一下 hadoop-mapreduce-examples 中的依赖关系,可以发现 WordCount.java 运行时需要的 hadoop-common 库的Scope是 “Provided” 方式(如图3),检查一下其pom.xml 文件(如图4),确实如此:
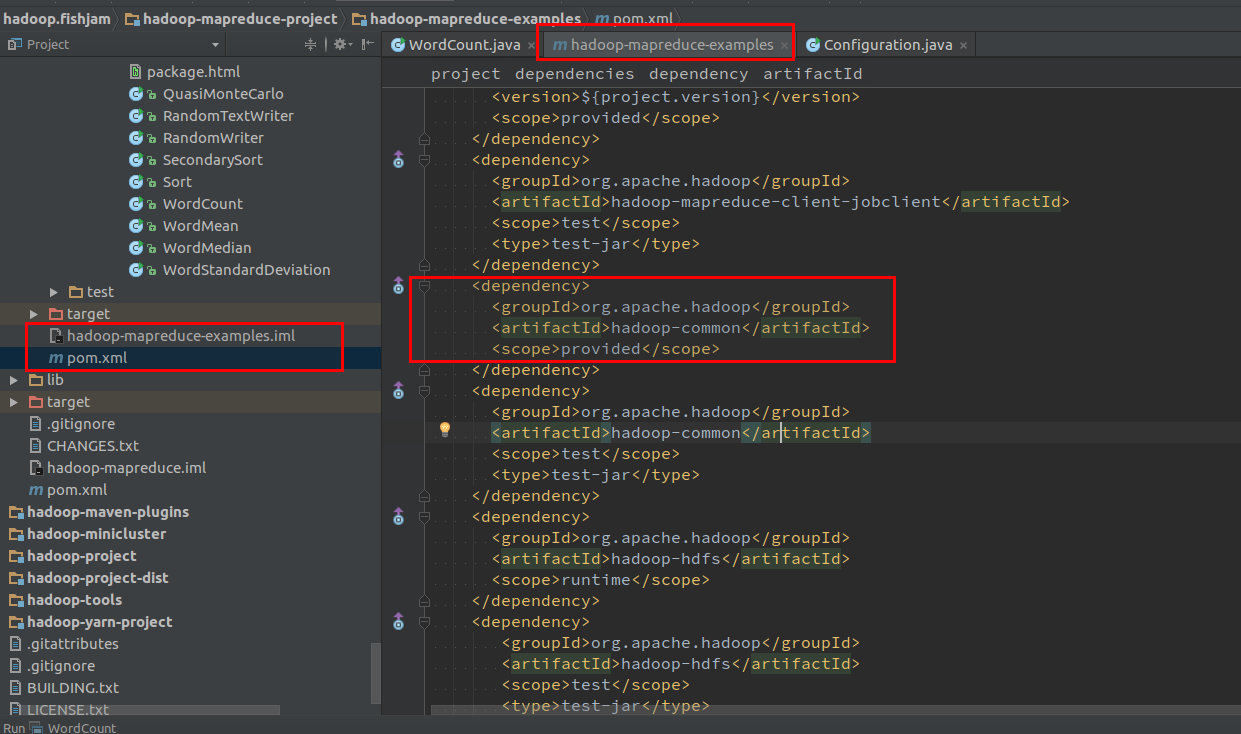
这个时候立刻知道,将Scope删除或改为默认的compile有可能就能解决这个问题(具体原因,如果不清楚的建议学习以下Maven的Scope概念)。更改后重新运行 WordCount.java 程序,发现错误日志果然不一样(提示运行时参数不满足需求),已经能够进入main了。
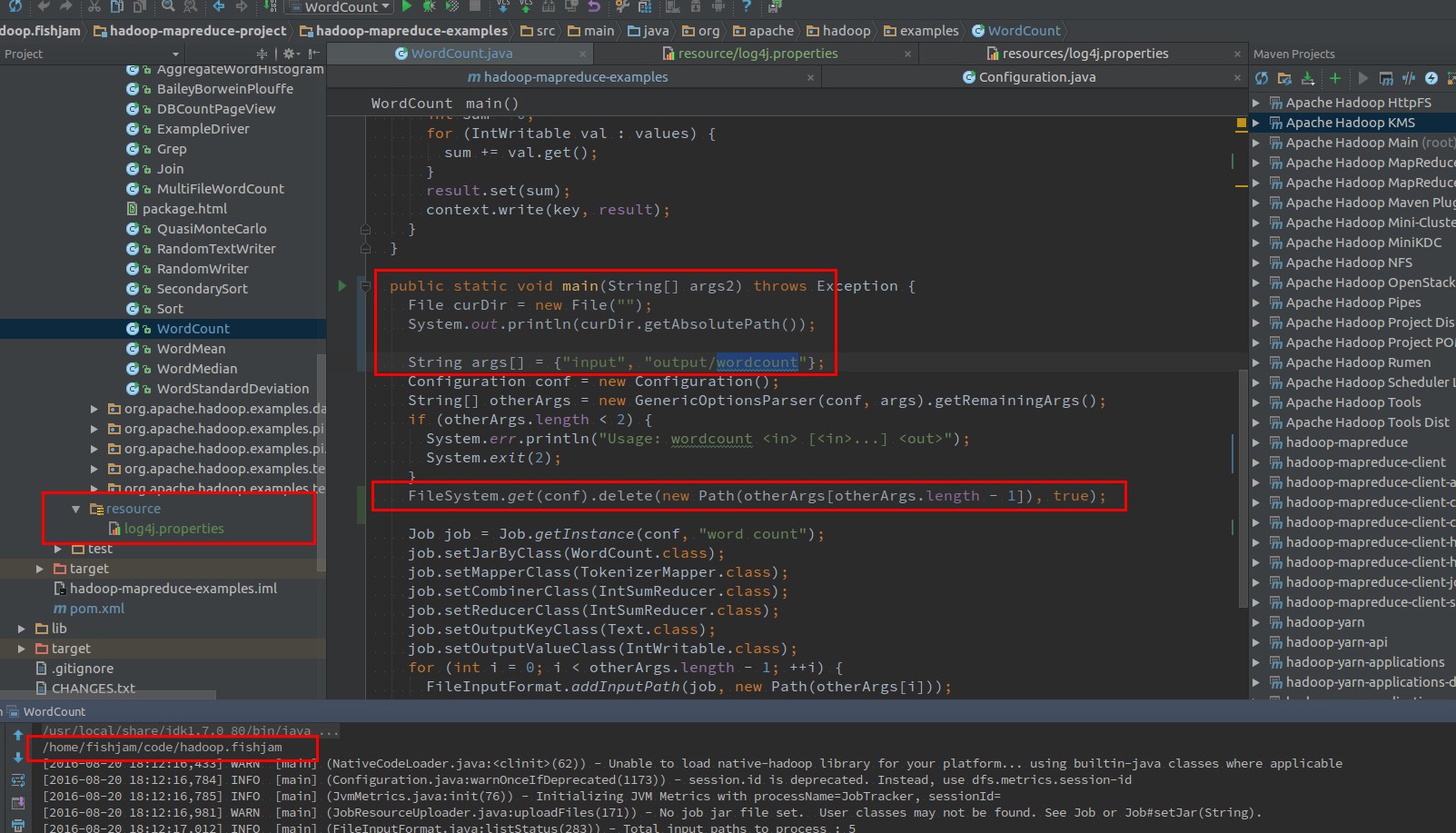
最后,对项目进行最后的改动:
1.通过命令行的方式提供 args 参数 – 这样方便在代码中随时更改;
2.通过 FileSystem 来自动删除输出目录 – 避免每次运行前都要手动删除或可能的报错
3.建立resource目录,并拷贝进log4j.properties,这样可以显示日志信息
4.在项目的根目录下建立输入目录(input – 具体目录位置可通过 new File(“”).getAbsolutePath() 获得)和输出目录,并拷贝进需要测试的文件。
此时重新运行程序,没有问题的话,即可顺利运行了。然后可用同样的方式调试 hadoop-mapreduce-examples 中的所有示例来学些Hadoop的使用了。
注意事项
本方法可以很容易的调试MapReduce程序,但由于默认使用的是单机模式,因此不能直接调试 HDFS 相关的代码.
后续如果研究出简易调试HDFS方法的话,再进行共享.
总结
综上所述,下载hadoop源码后,更改 hadoop-mapreduce-examples 项目pom.xml 中的scope,即可很方便的调试其程序了,而其最方便的地方在于,可以随时更改并测试Hadoop的源码,大大提高学习Hadoop的效率。