1、HashMap数据结构
HashMap是基于hash表进行key-value存储的一种数据结构,学过数据结构的我们都知道Hash表(散列表)的基本思想以及原理。在这里不做过多介绍。HashMap及其子类采用hash算法来决定Map中key的存储,并通过hash算法来增加key集合的大小。
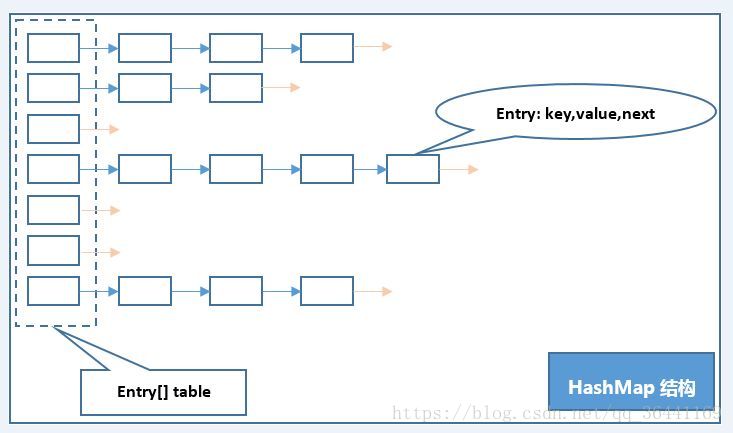
hash表里可以存储元素的位置被称为"桶",hash算法可以根据元素的hashCode值计算出元素在hash表中的位置,从而进行存储或者取出数据。在散列地址冲突的情况下,单个桶会存放多个元素,在HashMap中这些元素以一个单链表的方式进行存储,存储大致如图所示
2、HashMap源码分析(jdk1.8)
2、1存储结构
Hash表存储
transient Node<K,V>[] table;
桶元素
static class Node<K,V> implements Map.Entry<K,V> {
//因为在Hash表中如果HashCode冲突是以链式方式存储,所以存在next属性
final int hash;
final K key;
V value;
Node<K,V> next;
2、2jdk1.8的改进
在jdk1.8中HashMap中最大的区别为散列冲突时的处理方式,在jdk1.8以前在hashCode冲 突时都只是将其转换为链式进行存储,这样实现起来虽然简单但是当链表长度超过一定长度时进行元素查询时难免会造成时间复杂度过高的弊端,所以在jdk1.8中当一个hashCode相同的元素个数超过一定值时(
TREEIFY_THRESHOLD = 8)我们采用红黑树的形式进行存储(采用平衡二叉树),这样可以大大提高元素索引的效率(相当于数据库中的索引)。
//在这里用当hashCode的元素超过8时用红黑树(TreeNode)存放key-value值
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
/**
* Returns root of tree containing this node.
*/
final TreeNode<K,V> root() {
for (TreeNode<K,V> r = this, p;;) {
if ((p = r.parent) == null)
return r;
r = p;
}
}
. ........
}
2、3核心方法分析
2、3、1put方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//如果tal为空(还没有分配内存)或者table的长度为0先调用resize初始化table
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//根据散列计算函数,将HashCode为hash的元素放入table[(n-1)&hash]的位置,方法时新建一个Node节点同时将hash,key,value值传入
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
//此种情况存在散列冲突的情况,处理散列冲突
else {
Node<K,V> e; K k;
//检查第一个Node,p是不是要找的值
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
//遍历到列表的最后一个元素节点,并将重新申请一个节点
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//如果冲突的元素节点数已经达到TREEIFY_THRESHOLD(8)个,则改变链式存储采用红黑树的存储方式
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//如果有相同的key值就结束遍历
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//就是链表上有相同的key值
if (e != null) { // existing mapping for key
V oldValue = e.value;
//onlyIfAbsent为false或是oldvalue值为空则对value值进行更新
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
//返回存在的Value值
return oldValue;
}
}
++modCount;
//如果当前大小大于门限,门限原本是初始容量*0.75
if (++size > threshold)
//扩容两倍
resize();
afterNodeInsertion(evict);
return null;
}
put方法总结:
1、判断table是否为空,或者table.size==0,如果是则进入hash表内存申请方法
2、获取当前元素的hash值,并在table中通过散列函数寻找到其需要存放的值
3、判断其要放入的桶是否已经有元素
--->否 申请Node空间,将key,value,hash,NextNode等信息放入Node中
--->是 处理散列冲突,根据冲突元素的个数进一步选择链式存储还是红黑树的存储的方式
2、3、2HashMap的扩容resize()方法
final Node[] resize() {
Node[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
/*如果旧表的长度不是空*/
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
/*把新表的长度设置为旧表长度的两倍(移位运算<<1),newCap=2*oldCap*/
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
/*把新表的门限设置为旧表门限的两倍,newThr=oldThr*2*/
newThr = oldThr << 1; // double threshold
}
/*如果旧表的长度的是0,就是说第一次初始化表*/
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;//新表长度乘以加载因子
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
/*重新申请hash表的内存空间,并拷贝原表中的数据*/
Node[] newTab = (Node[])new Node[newCap];
table = newTab;//把新表赋值给table
if (oldTab != null) {//原表不是空要把原表中数据移动到新表中
/*遍历原来的旧表*/
for (int j = 0; j < oldCap; ++j) {
Node e;
//原表中不为空的节点
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
//说明这个node没有链表直接放在新表的e.hash & (newCap - 1)位置
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
//node节点中存在链表,将一个链表拆分为两个链表分别放入散列表的不同位置
else if (e instanceof TreeNode)
((TreeNode)e).split(this, newTab, j, oldCap);
/*如果e后边有链表,到这里表示e后面带着个单链表,需要遍历单链表,将每个结点重*/
else { // preserve order保证顺序
////新计算在新表的位置,并进行搬运
Node loHead = null, loTail = null;
Node hiHead = null, hiTail = null;
Node next;
do {
next = e.next;//记录下一个结点
//新表是旧表的两倍容量,实例上就把单链表拆分为两队,
//e.hash&oldCap为偶数一队,e.hash&oldCap为奇数一对
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {//lo队不为null,放在新表原位置
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {//hi队不为null,放在新表j+oldCap位置
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
附:限于作者编码与理解能力,欢迎读者批评指正