说明
说明1、其余的见前几篇博客,本文基于之前安装的集群安装spark,安装的节点如下(标红的为本次安装):
机器 |
安装软件 |
进程 |
focuson1 |
zookeeper;hadoop namenode;hadoop DataNode;hbase master;hbase regionrerver;spark master;spark worker |
JournalNode; DataNode; QuorumPeerMain; NameNode; NodeManager;DFSZKFailoverController;HMaster;HRegionServer;Worker;Master |
focuson2 |
zookeeper;hadoop namenode;hadoop DataNode;yarn;hbase master;hbase regionrerver;spark master;spark worker |
NodeManager;ResourceManager;JournalNode; DataNode; QuorumPeerMain; NameNode; DFSZKFailoverController;HMaster;HRegionServer;Worker;Master |
focuson3 |
zookeeper;hadoop DataNode;yarn;hbase regionrerver;spark worker |
NodeManager;ResourceManager;JournalNode; DataNode; QuorumPeerMain;HRegionServer;Worker/2 |
说明2、本次是安装spark最新版本2.3.0,需在hadoop基础上搭建,使用zookeeper作为master高可用。
说明3、此版本要求jdk的版本至少为1.8,如果低于1.8,启动会报下面的错
Exception in thread "main" java.lang.UnsupportedClassVersionError: org/apache/spark/launcher/Main : Unsupported major.minor version 52.0
at java.lang.ClassLoader.defineClass1(Native Method)
at java.lang.ClassLoader.defineClass(ClassLoader.java:800)
at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142)
at java.net.URLClassLoader.defineClass(URLClassLoader.java:449)
at java.net.URLClassLoader.access$100(URLClassLoader.java:71)
at java.net.URLClassLoader$1.run(URLClassLoader.java:361)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:308)
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
at sun.launcher.LauncherHelper.checkAndLoadMain(LauncherHelper.java:482)
集群安装
1、下载最新镜像,由于我hadoop是2.6,所以版本是spark-2.3.0-bin-hadoop2.6.tgz。将包上传至focuson1用户家目录,解压
cd /usr/local/src/ mkdir spark mv ~/spark-2.3.0-bin-hadoop2.6.tgz . tar -xvf spark-2.3.0-bin-hadoop2.6.tgz rm -f spark-2.3.0-bin-hadoop2.6.tgz
2、环境变量配置,方便操作。下面粘出来总的:
vi /etc/profile JAVA_HOME=/usr/local/src/java/jdk1.8.0_172 export HADOOP_HOME=/usr/local/src/hadoop/hadoop-2.6.0 export ZOOKEEPER_HOME=/usr/local/src/zookeeper/zookeeper-3.4.12 export SPARK_HOME=/usr/local/src/spark/spark-2.3.0-bin-hadoop2.6 export HBASE_HOME=/usr/local/src/hbase/hbase-1.4.3 JAVA_BIN=/usr/local/src/java/jdk1.7.0_51/bin PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin:$ZOOKEEPER_HOME/bin:$SPARK_HOME/bin:HBASE_HOME/bin: CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export JAVA_HOME JAVA_BIN PATH CLASSPATH
3、配置文件配置-spark-env.sh & slaves
cd $SPARK_HOME/conf cp spark-env.sh.template spark-env.sh vi spark-env.sh #配置如下 #hadoop的配置文件路径,spark会去读取配置文件,如果不在同一个集群,需拷贝配置文件到spark的节点,让spark能够读到 HADOOP_CONF_DIR=/usr/local/src/hadoop/hadoop-2.6.0/etc/hadoop #本机ip SPARK_LOCAL_IP=focuson3 JAVA_HOME=/usr/local/src/java/jdk1.8.0_172 #zookeeper实现spark的高可用 SPARK_MASTER_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER-Dspark.deploy.zookeeper.url=focuson1:2181,focuson2:2181,focuson3:2181-Dspark.deploy.zookeeper.dir=/spark" cp slaves.template slaves vi slaves #配置集群worker focuson1 focuson2 focuson
focuson1 focuson2 focuson3
4、scp到其他两台机器。
scp -r /usr/local/src/spark focuson2:/usr/local/src/ scp -r /usr/local/src/spark focuson3:/usr/local/src/
5、启动(默认已启动hadoop、zookeeper)
启动一:在focuson1上
cd $SPARK_HOME ./sbin/start-all.sh
启动输出如下,启动了focuson1的master和三个节点的worker:
[root@focuson1 spark-2.3.0-bin-hadoop2.6]# ./sbin/start-all.sh starting org.apache.spark.deploy.master.Master, logging to /usr/local/src/spark/spark-2.3.0-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.master.Master-1-focuson1.out focuson2: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/src/spark/spark-2.3.0-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-focuson2.out focuson1: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/src/spark/spark-2.3.0-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-focuson1.out focuson3: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/src/spark/spark-2.3.0-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-focuson3.out
启动二:在focuson2上,启动master
[root@focuson2 spark-2.3.0-bin-hadoop2.6]# ./sbin/start-master.sh starting org.apache.spark.deploy.master.Master, logging to /usr/local/src/spark/spark-2.3.0-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.master.Master-1-focuson2.out
6、验证。
验证一:是否启动成功。在三台机器上分别jps,会发现三台机器上都有worker进程,focuson1和focuson2上有master进程。
验证二:master HA
在focuson上启动zookeeper客户端,会发现创建了/spark监听路径,和配置文件一致:
[root@focuson1 conf]# zkCli.sh [zk: localhost:2181(CONNECTED) 0] ls / [zookeeper, yarn-leader-election, spark, hadoop-ha, hbase]
web界面,发现focuson1的status为ALIVE,focuson2的status为STANDBY:
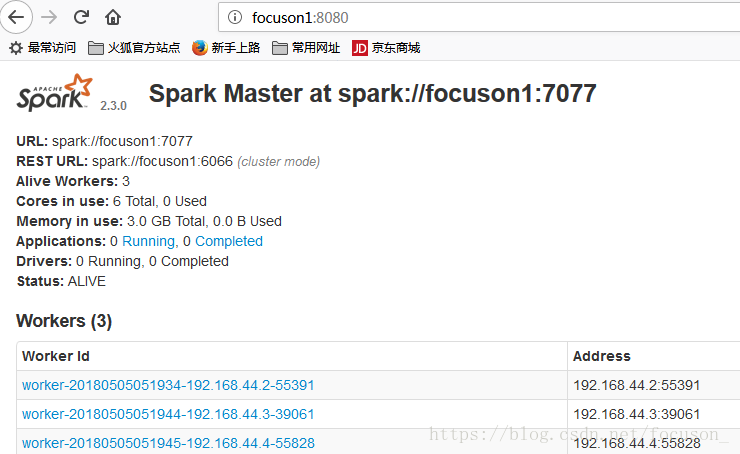

在focuson1上,stop掉master进程,会发现过一会,focuson2会变成alive。
完事。