1.为什么要服务发现【https://www.nginx.com/blog/service-discovery-in-a-microservices-architecture/】
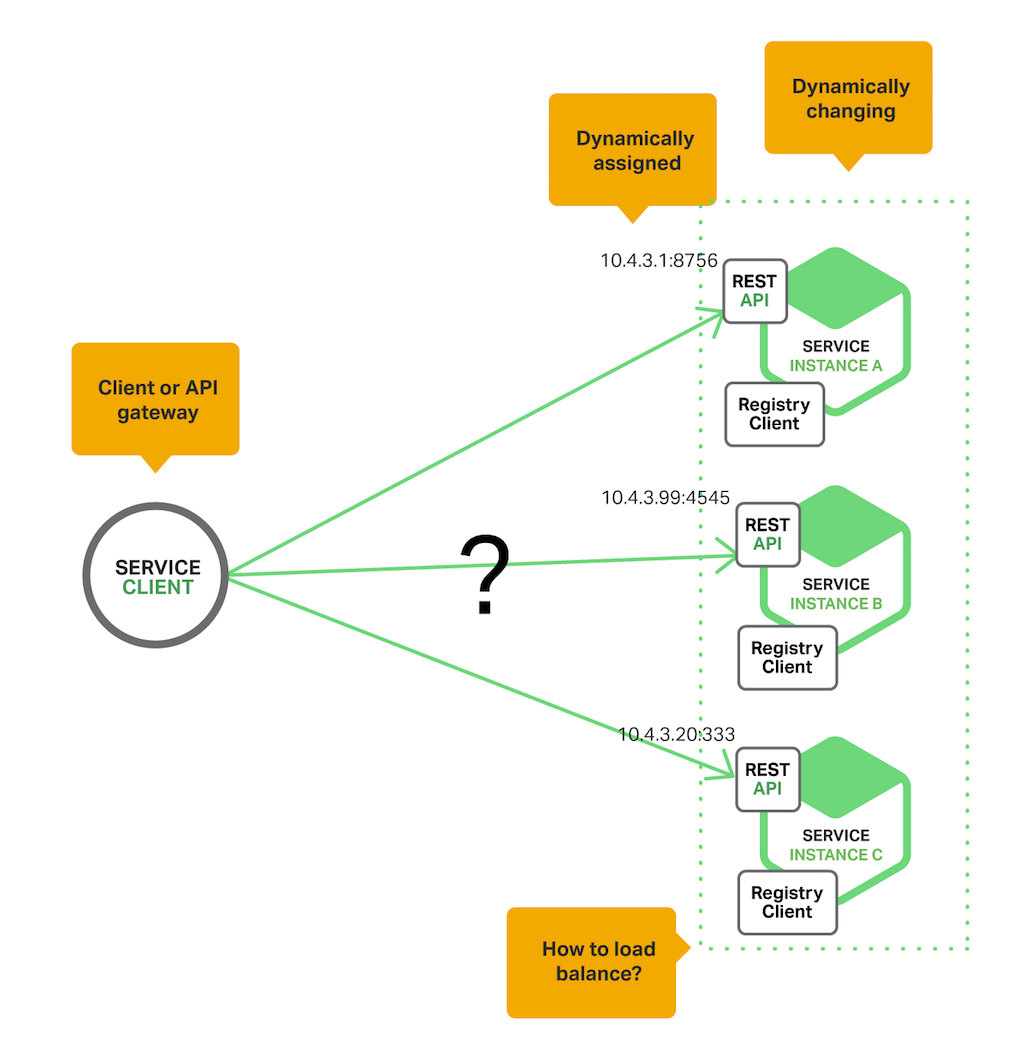
2.选型

3.业界使用【http://www.infoq.com/cn/articles/background-architecture-and-solutions-of-service-discovery】
DNS可以算是最为原始的服务发现系统,但是在服务变更较为频繁,即服务的动态性很强的时候,DNS记录的传播速度可能会跟不上服务的变更速度,这将导致在一定的时间窗口内无法提供正确的服务位置信息,所以这种方案只适合在比较静态的环境中使用,不适用于微服务。
基于ZooKeeper、Etcd等分布式键值对存储服务来建立服务发现系统在现在看起来也不是一种很好的方案,一方面是因为它们只能提供基本的数据存储功能,还需要在外围做大量的开发才能形成完整的服务发现方案。另一方面是因为它们都是强一致性系统,在集群发生分区时会优先保证一致性、放弃可用性,而服务发现方案更注重可用性,为了保证可用性可以选择最终一致性,这两方面原因共同导致了ZooKeeper、Etcd这类系统越来越远离服务发现方案的备选清单,像SmartStack这种依赖ZooKeeper的服务发现方案也逐渐发觉ZooKeeper成了它的薄弱环节。
Netflix的Eureka是现在最流行的服务发现方案,服务端和客户端都是Java编写的,针对微服务场景,并且和Netflix的其他开源项目以及Spring Cloud都有着非常好的整合,具备良好的生态,如果你使用Java语言开发,Eureka几乎是你的最佳选择。与ZooKeeper、Etcd或者依赖它们的方案不同,Eureka是个专门为服务发现从零开始开发的项目,Eureka以可用性为先,可以在多种故障期间保持服务发现和服务注册功能可用,虽然此时会存在一些数据错误,但是Eureka的设计原则是“存在少量的错误数据,总比完全不可用要好”,并且可以在故障恢复之后按最终一致性进行状态合并,清理掉错误数据。
前面为什么说Eureka“几乎是”最佳选择,因为它还有个强大的对手Consul。Consul是HashiCorp公司的商业产品,它有一个开源的基础版本,这个版本在基本的服务发现功能之外,还提供了多数据中心部署能力,包括内存、存储使用情况在内的细粒度服务状态检测能力,和用于服务配置的键值对存储能力(这是一把双刃剑,使用它可以带来便捷,但是也意味着和Consul的较强耦合性),这几个能力Eureka目前都没有。而Consul的商业版本功能更为强大,如果你不介意依赖单一公司提供的商业产品,也可以从Consul的开源版本开始用起。
最后还有一个比较有趣的方案是SkyDNS,这是一个结合古老的DNS技术和时髦的Go语言、Raft算法的有趣项目,主要在Kubernetes里使用,因为Kubernetes有一层较为稳定的Service抽象,有点类似于问题2里描述的服务端服务发现方式,所以不存在DNS时间窗口的问题。
这里我就不对上述的各个方案做具体功能特性上的对比了,我在做方案选型时不太喜欢做这种微观对比,因为具体的功能特性是易变的,今天Consul出一个新功能,明天Eureka出一个新特性,如果依赖这个做选择,会摇摆不定,我更注重这些方案背后的一些根深蒂固的必然性,比如ZooKeeper永远都不会为了服务发现放弃它的强一致性,所以即使它有再多适合服务发现的功能特性,它也不会成为服务发现的优选方案,再比如Consul由一家商业软件公司提供,那么必然或多或少的存在商业软件的某些弊端,如果你非常在意这些弊端,Consul再强大,你也不会选择它。