进来一直为各种课程的实验报告困扰,字数很多,百度文库、豆瓣等资源网站又无法免费下载。
就想着如果我能把他们截图下来,然后批量转换成文字该多好呢?
所谓懒惰是人类进步的阶梯。
笔者决定通过python程序,调用百度api完成这项功能。
认证百度开发者
首先要在百度开发者平台认证成为百度开发者,创建应用后即会获得ID、API Key、Secret Key
如图:
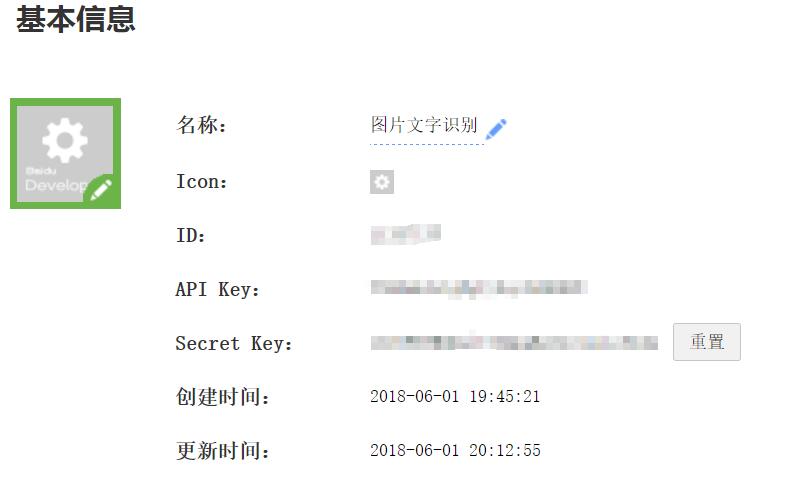
图中为笔者自己的账号,所以进行了打码。后文进行编程时,笔者将使用网络上分享的账号等进行演示。
安装库
打开cmd,输入:pip install baidu-aip
等待安装完成即可。下面进行编程。
导入必要文件
扫描二维码关注公众号,回复:
1834754 查看本文章

from aip import AipOcr
import osAipOcr即我们需要的百度文字识别功能。
设置自己的ID、API Key、Secret Key
笔者在此使用网络上分享的账号,建议使用自己注册的账号。
APP_ID = '9851066'
API_KEY = 'LUGBatgyRGoerR9FZbV4SQYk'
SECRET_KEY = 'fB2MNz1c2UHLTximFlC4laXPg7CVfyjV'
aipOcr = AipOcr(APP_ID, API_KEY, SECRET_KEY)打开并加载图片文件的函数
def get_file_content(filePath): #这样只要获得文件名就能够进行识别
with open(filePath, 'rb') as fp:
return fp.read()注意使用二进制打开。
关键代码
在代码中具体注释
for root, dirs, files in os.walk(".", topdown=False): # 该迭代类型每单元返回三个部分,我们需要的文件名在第三部分,具体参数自行了解
for name in files: # name即为文件夹下每个文件的文件名
if 'png' in name: # 判断是否为图片格式,笔者这里设置png因为常用QQ截图,可自行添加其他格式
filePath = os.path.join(root, name)[2:] # 记录下的文件名有./.前缀,所以从第二位为我们需要的filepath
options = {
'detect_direction': 'true',
'language_type': 'CHN_ENG',
}
result = aipOcr.webImage(get_file_content(filePath),options) #通过filepath打开并识图
for i in result['words_result']: # result为字典类型,识别出的文字信息存放在'words_result'对应的字典中
print(i['words']) #列表中接着嵌套字典,每一部分信息存储在'words'键中 完整代码
from aip import AipOcr
import os
APP_ID = '9851066'
API_KEY = 'LUGBatgyRGoerR9FZbV4SQYk'
SECRET_KEY = 'fB2MNz1c2UHLTximFlC4laXPg7CVfyjV'
aipOcr = AipOcr(APP_ID, API_KEY, SECRET_KEY)
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
for root, dirs, files in os.walk(".", topdown=False):
for name in files:
if 'png' in name:
filePath = os.path.join(root, name)[2:]
options = {
'detect_direction': 'true',
'language_type': 'CHN_ENG',
}
result = aipOcr.webImage(get_file_content(filePath),options)
print(result)
for i in result['words_result']:
print(i['words'])
如何使用
把程序放入单独文件夹中,下面只要把想识别的图片全部放入该文件夹下,运行程序即可批量识别并打印所有图片中的文字。
运行示例
我们任意把一些图片放入文件夹,如下面两图
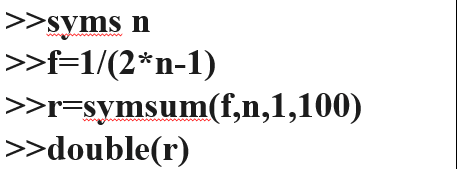

接着我们运行程序,结果如下图
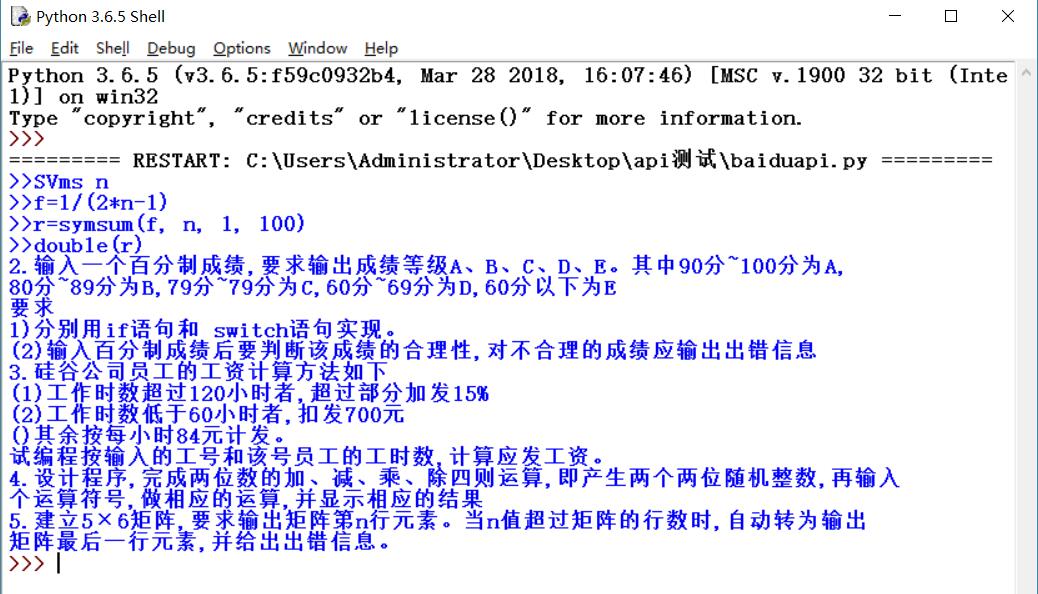
可以看到程序读完第一个图,接着读第二个图,实现批量转换。
经过笔者多次测试,准确率达到95%以上,达到预期效果。
接着为了提高普适性,可转换为exe格式、增加图形界面等,时间原因笔者不再深入。
文中涉及到的帐号密码来源于网络分享,侵删
转载请告知作者