https://blog.csdn.net/zeb_perfect/article/details/52574915
Hash碰撞冲突
我们知道,对象Hash的前提是实现equals()和hashCode()两个方法,那么HashCode()的作用就是保证对象返回唯一hash值,但当两个对象计算值一样时,这就发生了碰撞冲突。如下将介绍如何处理冲突,当然其前提是一致性hash。
1.开放地址法
开放地执法有一个公式:Hi=(H(key)+di) MOD m i=1,2,…,k(k<=m-1)
其中,m为哈希表的表长。di 是产生冲突的时候的增量序列。如果di值可能为1,2,3,…m-1,称线性探测再散列。
如果di取1,则每次冲突之后,向后移动1个位置.如果di取值可能为1,-1,2,-2,4,-4,9,-9,16,-16,…k*k,-k*k(k<=m/2),称二次探测再散列。
如果di取值可能为伪随机数列。称伪随机探测再散列。
2.再哈希法
当发生冲突时,使用第二个、第三个、哈希函数计算地址,直到无冲突时。缺点:计算时间增加。
比如上面第一次按照姓首字母进行哈希,如果产生冲突可以按照姓字母首字母第二位进行哈希,再冲突,第三位,直到不冲突为止
3.链地址法(拉链法)
将所有关键字为同义词的记录存储在同一线性链表中。如下:
因此这种方法,可以近似的认为是筒子里面套筒子
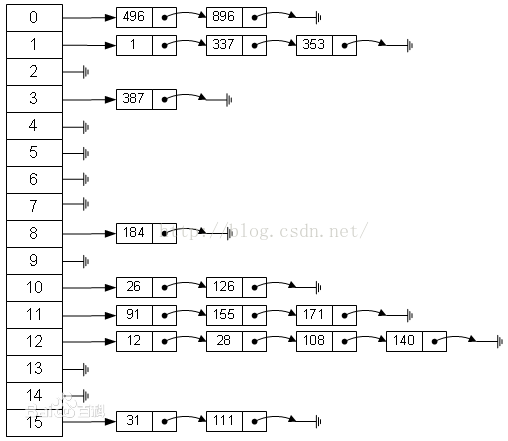
4.建立一个公共溢出区
假设哈希函数的值域为[0,m-1],则设向量HashTable[0..m-1]为基本表,另外设立存储空间向量OverTable[0..v]用以存储发生冲突的记录。
拉链法的优缺点:
优点:
①拉链法处理冲突简单,且无堆积现象,即非同义词决不会发生冲突,因此平均查找长度较短;②由于拉链法中各链表上的结点空间是动态申请的,故它更适合于造表前无法确定表长的情况;
③开放定址法为减少冲突,要求装填因子α较小,故当结点规模较大时会浪费很多空间。而拉链法中可取α≥1,且结点较大时,拉链法中增加的指针域可忽略不计,因此节省空间;
④在用拉链法构造的散列表中,删除结点的操作易于实现。只要简单地删去链表上相应的结点即可。而对开放地址法构造的散列表,删除结点不能简单地将被删结 点的空间置为空,否则将截断在它之后填人散列表的同义词结点的查找路径。这是因为各种开放地址法中,空地址单元(即开放地址)都是查找失败的条件。因此在 用开放地址法处理冲突的散列表上执行删除操作,只能在被删结点上做删除标记,而不能真正删除结点。
缺点:
指针需要额外的空间,故当结点规模较小时,开放定址法较为节省空间,而若将节省的指针空间用来扩大散列表的规模,可使装填因子变小,这又减少了开放定址法中的冲突,从而提高平均查找速度。
============================================================================================
https://www.cnblogs.com/wuchaodzxx/p/7396599.html
解决hash冲突的三个方法
通过构造性能良好的哈希函数,可以减少冲突,但一般不可能完全避免冲突,因此解决冲突是哈希法的另一个关键问题。创建哈希表和查找哈希表都会遇到冲突,两种情况下解决冲突的方法应该一致。下面以创建哈希表为例,说明解决冲突的方法。常用的解决冲突方法有以下四种:
开放定址法
这种方法也称再散列法,其基本思想是:当关键字key的哈希地址p=H(key)出现冲突时,以p为基础,产生另一个哈希地址p1,如果p1仍然冲突,再以p为基础,产生另一个哈希地址p2,…,直到找出一个不冲突的哈希地址pi ,将相应元素存入其中。这种方法有一个通用的再散列函数形式:
Hi=(H(key)+di)% m i=1,2,…,n
其中H(key)为哈希函数,m 为表长,di称为增量序列。增量序列的取值方式不同,相应的再散列方式也不同。主要有以下三种:
线性探测再散列
dii=1,2,3,…,m-1
这种方法的特点是:冲突发生时,顺序查看表中下一单元,直到找出一个空单元或查遍全表。
二次探测再散列
di=12,-12,22,-22,…,k2,-k2 ( k<=m/2 )
这种方法的特点是:冲突发生时,在表的左右进行跳跃式探测,比较灵活。
伪随机探测再散列
di=伪随机数序列。
具体实现时,应建立一个伪随机数发生器,(如i=(i+p) % m),并给定一个随机数做起点。
例如,已知哈希表长度m=11,哈希函数为:H(key)= key % 11,则H(47)=3,H(26)=4,H(60)=5,假设下一个关键字为69,则H(69)=3,与47冲突。
如果用线性探测再散列处理冲突,下一个哈希地址为H1=(3 + 1)% 11 = 4,仍然冲突,再找下一个哈希地址为H2=(3 + 2)% 11 = 5,还是冲突,继续找下一个哈希地址为H3=(3 + 3)% 11 = 6,此时不再冲突,将69填入5号单元。
如果用二次探测再散列处理冲突,下一个哈希地址为H1=(3 + 12)% 11 = 4,仍然冲突,再找下一个哈希地址为H2=(3 - 12)% 11 = 2,此时不再冲突,将69填入2号单元。
如果用伪随机探测再散列处理冲突,且伪随机数序列为:2,5,9,……..,则下一个哈希地址为H1=(3 + 2)% 11 = 5,仍然冲突,再找下一个哈希地址为H2=(3 + 5)% 11 = 8,此时不再冲突,将69填入8号单元。
再哈希法
这种方法是同时构造多个不同的哈希函数:
Hi=RH1(key) i=1,2,…,k
当哈希地址Hi=RH1(key)发生冲突时,再计算Hi=RH2(key)……,直到冲突不再产生。这种方法不易产生聚集,但增加了计算时间。
链地址法
这种方法的基本思想是将所有哈希地址为i的元素构成一个称为同义词链的单链表,并将单链表的头指针存在哈希表的第i个单元中,因而查找、插入和删除主要在同义词链中进行。链地址法适用于经常进行插入和删除的情况。
建立公共溢出区
这种方法的基本思想是:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。