解决问题:数据库分表可以解决单表海量数据的查询性能问题,分库可以解决单台数据库的并发访问压力问题
应用场景:在没分库分表情况下当订单表数量超过1000万条以上,我们需要对订单表按照业务进行分库分表(当超过500万条数据数据库查询用索引效率大大下降)
技术方案:一般都采用第三方工具,当当网的sharding-jdbc,阿里TDDL、mycat和Cobar等插件
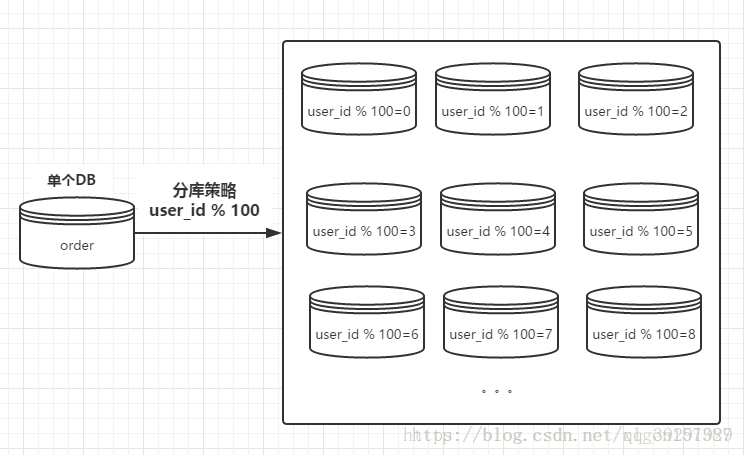
数据分表实现策略:一般采用业务进行分,比如订单表,如果是用户订单那么按照用户id后两位(当数据量不是很大情况下)取模存到不同的数据库表中,如果是商家订单那么按照商家id后两位(当数据量不是很大情况下)取模存到不同的数据库表中
数据库环境:一般采用一个主机(或者多个,公司有钱),安装多个数据库,设置不同数据库端口而已,就是一个阿里云服务器上装多个数据库不同端口而已
主从复制:一般采用主从复制,新增和修改都在主库,查询都是在从库中,一般一对多
分库分表查询:当订单页面需要根据会员姓名、手机号码、订单号、下单开始时间、下单结束时间等等,设计到多个模块一起关联查询时,
采用如下方案:
1.对不可变字段做沉余,方便查询,比如用户姓名,在金融平台用户实名后姓名不能更改.
2.根据阿里规则:各个模块不要做关联查询,避免join。比如:上述订单表查询,首先到会员数据库中查询,然后在到订单表中查询。
规则:既然分库分表就不要join查询。
重点:(1).一般会员id使用UUID,那么首先要进行hash获取到整数值,然后进行去模操作
(2).所有数据根据数据库表数量进行取模
(3).必须对数据库查询关键字段添加索引,提高查询效率
本次利用sharding-jdbc进行分库分表实战如下:
java分库分表技术
猜你喜欢
转载自blog.csdn.net/qq_39291929/article/details/80795221
今日推荐
周排行