笔试的东西就不贴上来了,毕竟试卷上写着未经允许不得外传。我还是个遵纪守法的好公民。
谈谈面试吧,顺便把题目答案整理一下,供日后参考。会有个人理解疏漏或者不正确的地方,欢迎提出指正!
面试分了好几批,我是第一批,大概是笔试分数比较低,不过最后两道编程题和一道算法题都空着没做,居然还能过已经很吃惊了,(姨母笑)大概是报算法的人少吧所以笔试通过率高一点。
首先是自我介绍,这个说实话都没好好准备过,mark一下
介绍一下什么是神经网络(自我介绍的时候有提到现在的研究方向)
人工神经网络(ANNs)也成为神经网络(NNs),模拟人脑的神经网络结构以期实现类人工智能的机器学习技术,同时也是深度学习的基础。(它的第一个应用是提出的感知机网络和联想学习规则)
神经网络一般是一层一层的,比较经典的是包含三个层次的神经网络:输入层,隐藏层(中间层),输出层。层与层之间连接,每个连接上都有一个权值,一个神经网络的训练过程可以看作是将权值和偏置值调整到最优的状态,这个最优的状态就是让整个网络的预测效果最好。
一篇参考博文,可以帮助更好地理解。神经网络浅谈:从神经元到深度学习
介绍一下卷积神经网络
卷积神经网络是一种深度的前馈神经网络,包括卷积层、池化层。卷积层主要是池化操作这个在初始里有一道简答题就是说说”卷积“的含义。卷积层神经网络使用的激活函数一般是ReLU(The Rectified Linear Unit修正线性单元),其特点是收敛快,求梯度简单。通常还有全连接层在网络的尾部。
参考博客。卷积神经网络CNN总结
介绍一下集成学习
集成学习是通过构建并结合多个学习期来完成学习任务。目前的集成学习方法大致有两类,一类是个体学习器之间存在强依赖关系、必须串行生成的序列化方法,代表是Boosting;一类是个体学习器之间不存在强依赖关系、可同时生成的并行化方法,比如Bagging和随机森林。
Boosting:(代表是Adaboost)每个新分类器根据以训练出的分类器的性能来进行训练,分类结果基于所有分类器的加权求和。
Bagging:从原始数据集中选择s次后得到s个新数据集的技术(有放回的抽样方法),有论文证明这种采样方法大约会有63%(1-1/e)不会重复。对分类任务使用简单投票法,回归是简单平均法。
介绍一下决策树(上面几个问题都是因为我在简历中有提到,所以问了,但是好像我前面几位也有问到差不多这些东西)
基于树结构来进行决策。决策过程的最终结论对应我们所希望的判定结果。类型有很多CART、ID3、C4.5等
划分的策略看信息熵和信息增益,信息增益越大,说明使用属性a划分获得的”纯度提升“越大。
当然还有什么基尼指数、剪枝处理(预剪枝和后剪枝)。好好看西瓜书吧。
信息熵的公式是什么?
其值越小,纯度越高。
补充一下信息增益的公式
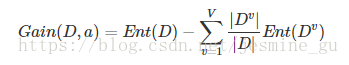
如果数据的分布比较大,那么信息熵和信息增益有什么变化之类的?
这个问题没听清楚,大概是这个意思。
我的理解是分布大,或者说变化大那么熵也大。在信息增益中,携带的信息量多,该特征就越重要,系统有它没它将发生变化,那么这个前后信息量的变化就是特征给系统带来的信息量,也就是熵。
西瓜书中提到,信息增益对取值数目多的属性有偏好,所以就有C4.5决策树算法用增益率来选择最优属性。
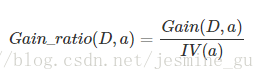
数据结构学的怎么样?对图、树啊之类是否了解?解释一下完全二叉树和不完全二叉树。
才发现我回答的时候说的是满二叉树,怪不得面试官在我说完的时候笑了,尴尬。
完全二叉树的叶子节点只能在最后两层出现,也就是只允许最后一层有空缺并且空缺在右侧;
对任意个节点,如果其右子树的深度为j,则其左子树的深度必为j或者j+1.即度为1的点只有1个或0个。
如果深度为h,那么除h层外的所有层都是满的。第i层最多有2^(i-1)个节点,整棵树最多有2^i-1个节点。
学过线性代数吗?有没有用过矩阵相关的包?
numpy?(略)
有没有用过什么深度学习的框架?跑过什么?结果怎么样?
(略)
感觉问的很基础,怪自己去之前没准备,感觉跟裸考一样,最重要的还是自己基础也不到家,答得是真差啊!不忍直视。
任重道远啊,继续努力,不要太浮躁了。
启示就是:简历上写的东西一定要搞清楚弄明白!!!然后基础很重要!!!