相同点
1、LR和SVM都是分类算法(曾经我认为这个点简直就是废话,了解机器学习的人都知道。然而,虽然是废话,也要说出来,毕竟确实是一个相同点。)
2、如果不考虑使用核函数,LR和SVM都是线性分类模型,也就是说它们的分类决策面是线性的。
其实LR也能使用核函数,但我们通常不会在LR中使用核函数,只会在SVM中使用。原因下面会提及。
3、LR和SVM都是监督学习方法。
监督学习方法、半监督学习方法和无监督学习方法的概念这里不再赘述。
4、LR和SVM都是判别模型。
判别模型和生成模型的概念这里也不再赘述。典型的判别模型包括K近邻法、感知机、决策树、Logistic回归、最大熵、SVM、boosting、条件随机场等。典型的生成模型包括朴素贝叶斯法、隐马尔可夫模型、高斯混合模型。
5、LR和SVM在学术界和工业界都广为人知并且应用广泛。(感觉这个点也比较像废话)
不同点
1、loss function不一样
LR的loss function是

SVM的loss function是
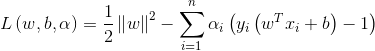
LR基于概率理论,通过极大似然估计方法估计出参数的值,然后计算分类概率,取概率较大的作为分类结果。SVM基于几何间隔最大化,把最大几何间隔面作为最优分类面。
2、SVM只考虑分类面附近的局部的点,即支持向量,LR则考虑所有的点,与分类面距离较远的点对结果也起作用,虽然作用较小。
SVM中的分类面是由支持向量控制的,非支持向量对结果不会产生任何影响。LR中的分类面则是由全部样本共同决定。线性SVM不直接依赖于数据分布,分类平面不受一类点影响;LR则受所有数据点的影响,如果数据不同类别strongly unbalance,一般需要先对数据做balancing。
3、在解决非线性分类问题时,SVM采用核函数,而LR通常不采用核函数。
分类模型的结果就是计算决策面,模型训练的过程就是决策面的计算过程。在计算决策面时,SVM算法中只有支持向量参与了核计算,即kernel machine的解的系数是稀疏的。在LR算法里,如果采用核函数,则每一个样本点都会参与核计算,这会带来很高的计算复杂度,所以,在具体应用中,LR很少采用核函数。
4、SVM不具有伸缩不变性,LR则具有伸缩不变性。
SVM模型在各个维度进行不均匀伸缩后,最优解与原来不等价,对于这样的模型,除非本来各维数据的分布范围就比较接近,否则必须进行标准化,以免模型参数被分布范围较大或较小的数据影响。LR模型在各个维度进行不均匀伸缩后,最优解与原来等价,对于这样的模型,是否标准化理论上不会改变最优解。但是,由于实际求解往往使用迭代算法,如果目标函数的形状太“扁”,迭代算法可能收敛得很慢甚至不收敛。所以对于具有伸缩不变性的模型,最好也进行数据标准化。
5、SVM损失函数自带正则项,因此,SVM是结构风险最小化算法。而LR需要额外在损失函数上加正则项。
所谓结构风险最小化,意思就是在训练误差和模型复杂度之间寻求平衡,防止过拟合,从而达到真实误差的最小化。未达到结构风险最小化的目的,最常用的方法就是添加正则项。
1. Adaboost 输SVM的一点就是需要的训练样本相当大,另外对一些脏数据的处理没有SVM利用惩罚因子方面。此外,在实践方面,一般Adaboost训练太耗时了,同样的数据量,你可以比较看,SVM确实快。
8. 用Adaboost去学一大堆feature,竟然不输latent SVM,真让我小小惊讶了一下。 看来,在有足够的training
data的情况下,Adaboost依然不输SVM。Adaboost因为其非线性的组合,能够fit很复杂的分界面,但是一定要有足够的训练样本。而SVM再加上kernel trick,我觉得依然有最好的generalization性能。
3. 两者组合,svm作为弱分类器实现adaboost,人脸表情 火焰识别
4. 有谁利用svm作为弱分类器实现adaboost算法的啊?
我觉得,你可能对某些概念的理解存在一定的偏差,adaboost算法是boosting算法的一个分支,boosting和bagging是重采样技术的两个主流方向。换句话说,adaboost算法的作用,是通过对训练样本的重采样,来解决训练样本不足造成的训练精度低的问题。。。而SVM是一个经典的两类分类器,所以,应该是用adaboost来增强SVM的分类能力,而不是用SVM来集成adaboost。。。
5. adaboost+haar人脸分类器用的是CART树,
接触机器学习最早就是这两个分类器开始的,今天想起了这两个概念,就脑海里滚动公式。想着它们做分类时的样子,想起写点对他们的直观认识,可能有很多不严谨的地方,看客可不要太较真啦。
说起Adaboost,想像一个包含所有数据点的集合,比如这些点就是每天在地铁站看到的所有女生,这个点里存储了女生x的身高、体重、皮肤颜色、发质、B、W之类不拉不拉不拉的一堆数据。现在问题就来了:什么样的算是美女啊??!!我跟很多同事同学去探讨这个问题,得到许多不一样的回答。A君认为个头要在Th1以上、B要在Th2以上、发质要在Th3以上;B君认为个头不是关键,他觉得只要Thmin<体重/身高<Thmax就是美女;C君又有不同意见,他的眼里认为只要和他的女盆友(S小姐)很像就是美女(大家可以认为我就是C君);D君是我们当中思想最不接地气的一个,他认为我的问题侮辱了他的智商和节操,看女生嘛要看气质,外在什么的都是次要的……最后我把每个人的判断标准(假设Hypotheses)整理起来,我发现他们每个人都有自己的标准,都很强悍地认为这就是美女!可以说他们每个人的判断标准都是一个强分类器了。可是这根本回答不了我的问题:什么样的算是美女啊?
后来大家吃饭的时候终于达成了共识:我们让每个人说出一个特别不能容忍的标准,比如如果她的体重身高比触犯了B君的最后底线(这个底线比之前的Thmin或者Thmax宽泛多了),他在B君那里是无论如何都不能称为美女了(即使是白富也不可以)。这样他们每个人的标准都宽松了许多许多(弱分类器),然后我们让A君先来判断,他认为是美女的交给B君,B-->C-->D-->……,最后得到的这些所谓美女虽然和每个人的标准都有一定差距,但是大家都觉得这样的结果还说得过去,不至于他们当中的某个人互掐起来。而且这样判断起来速度还蛮快的。
我问D君你看这个结果何如?D君说这和机器学习中的Adaboost有点像,(⊙o⊙)…
后来单位来了个E君,E君听说了我们的讨论,给了我一个工具,说把这个交给他们每个人,就能得到每个人对美女的划分了。这个工具还是蛮神奇的!A君拿到它以后,把他的各种要求输入进去了,无非就是各个Th啊,这些在数据点中都有存储,直接划定一条线就搞定了,so easy!A君利用此工具迅速把全公司上下筛选了一遍,真是无良啊。B君利用这个工具时,要用两条直线,依然是so easy!根据C君女友的各个特征此工具画出了多条直线几乎逼近一个曲面总算描绘出了C君的美女概念,almost easy!D君可是给这个工具出了个难题:error C2065: "气质" undeclared identifier !什么是气质啊。D君以为此工具要崩溃了可就错了。他还有个叫做Kernel的利器,从现有的身高、体重等一系列信息中提取出了这些女生所从事的职业、教育背景、家庭环境不拉不拉一大堆比之前还要多得多的数据,然后它在这些数据里画出一个区分平面得到了D君的美女概念标准。
这下D君大为惊叹,奔走相告且大呼曰:真乃验证美女之神器也!于是D君为它赐名:Super Validation Machine!