大神博客:
#include<cstdio>//自己学习了kmp之后打的一个kmp代码,希望有用
#include<cstring>
#include<iostream>
#include<algorithm>
using namespace std;
const int maxn = 1e5+5;
char a[maxn],b[maxn];
int nex[maxn];
void kmpnext(char* c)
{
nex[0] = -1;
int k = -1;
int len = strlen(c);
for(int i = 1;i<len;i++){
while(k>-1 && c[k+1] !=c[i]){
k = nex[k+1];
}
if(c[k+1] == c[i]){
k++;
}
nex[i] = k;
}
for(int i = 0;i<len;i++){
printf("%d ",nex[i]);
}printf("\n");
}
int kmp(char* c,char* d){
kmpnext(d);
int cnt = -1;
int lenc = strlen(c),lend = strlen(d);
int k = -1;
for(int i = 0;i<lenc;i++){
while(k>-1 && d[k+1] != c[i]){
k = nex[k];
}
if(d[k+1] == c[i]){
k++;
}
if(k == lend - 1){
return (i - k);
}
}
return cnt;
}
int main()
{
scanf("%s",a);
scanf("%s",b);
int l = kmp(a,b);
int len = strlen(b);
printf("%d %d\n",l,len+l);
for(int i = l;i<l+len;i++){
printf("%c ",a[i]);
}printf("\n");
return 0;
}
HDU——剪花布条
Problem Description
一块花布条,里面有些图案,另有一块直接可用的小饰条,里面也有一些图案。对于给定的花布条和小饰条,计算一下能从花布条中尽可能剪出几块小饰条来呢?
Input
输入中含有一些数据,分别是成对出现的花布条和小饰条,其布条都是用可见ASCII字符表示的,可见的ASCII字符有多少个,布条的花纹也有多少种花样。花纹条和小饰条不会超过1000个字符长。如果遇见#字符,则不再进行工作。
Output
输出能从花纹布中剪出的最多小饰条个数,如果一块都没有,那就老老实实输出0,每个结果之间应换行。
Sample Input
abcde a3aaaaaa aa#
Sample Output
03
AC:代码
#include<cstdio>
#include<cstring>
#include<iostream>
#include<algorithm>
using namespace std;
const int maxn = 1005;
char a[maxn],b[maxn];
int nextt[maxn];
void kmpnext(char* c){
int len = strlen(c);
nextt[0] = -1;
int k = -1;
for(int i = 1;i<len;i++){
while(k>-1 && c[k+1] != c[i]){
k = nextt[k];
}
if(c[i] == c[k+1]){
k++;
}
nextt[i] = k;
}
}
int kmp(char* c,char* d){
kmpnext(d);
int lenc = strlen(c),lend = strlen(d);
int k = -1,cnt = 0;
for(int i = 0;i<lenc;i++){
while(k>-1 && d[k+1] != c[i]){
k = nextt[k];
}
if(c[i] == d[k+1]){
k++;
}
if(k == lend - 1){
cnt++;
k = nextt[k];
i += lend-1;//重点
}
}
return cnt;
}
int main()
{
while(~scanf("%s",a))
{
if(a[0] == '#') break;
scanf("%s",b);
int l = kmp(a,b);
printf("%d\n",l);
}
return 0;
}
HDU - 1867 A + B for you again
Problem Description
Generally speaking, there are a lot of problems about strings processing. Now you encounter another such problem. If you get two strings, such as “asdf” and “sdfg”, the result of the addition between them is “asdfg”, for “sdf” is the tail substring of “asdf” and the head substring of the “sdfg” . However, the result comes as “asdfghjk”, when you have to add “asdf” and “ghjk” and guarantee the shortest string first, then the minimum lexicographic second, the same rules for other additions.
Input
For each case, there are two strings (the chars selected just form ‘a’ to ‘z’) for you, and each length of theirs won’t exceed 10^5 and won’t be empty.
Output
Print the ultimate string by the book.
Sample Input
asdf sdfgasdf ghjk
Sample Output
asdfgasdfghjk
#include <cstdio>
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int maxn = 1e5+5;
char a[maxn],b[maxn];
int nex[maxn];
void getnext(char* x,int xlen)
{
nex[0] = -1;
int k = -1;
for(int i = 1;i<xlen;i++ )
{
while(k>-1 && x[k+1] != x[i]){
k = nex[k];
}
if(x[k+1] == x[i]){
k++;
}
nex[i] = k;
}
}
int kmp(char* x,char* y)
{
int xlen = strlen(x),ylen = strlen(y);
int k = -1;
getnext(y,ylen);
for(int i = 0;i<xlen;i++)
{
while(k>-1 && y[k+1]!=x[i]){
k = nex[k];
}
if(y[k+1]== x[i]){
k++;
}
if( i == xlen - 1)
{
if(k == -1) return 0;
else {
return ( xlen - ( i - k ) );
}
}
}
}
int main()
{
while(~scanf("%s %s",a,b))
{
int l = kmp(a,b);
int r = kmp(b,a);
// printf("%d %d\n",l,r);
if( l == r){
if(a[0]>b[0])
{
printf("%s%s\n",b,a+l);
} else {
printf("%s%s\n",a,b+l);
}
} else {
if(l>r){
printf("%s%s\n",a,b+l);
} else {
printf("%s%s\n",b,a+r);
}
}
}
return 0;
}
HDU--1711
Given two sequences of numbers : a[1], a[2], ...... , a[N], and b[1], b[2], ...... , b[M] (1 <= M <= 10000, 1 <= N <= 1000000). Your task is to find a number K which make a[K] = b[1], a[K + 1] = b[2], ...... , a[K + M - 1] = b[M]. If there are more than one K exist, output the smallest one.
InputThe first line of input is a number T which indicate the number of cases. Each case contains three lines. The first line is two numbers N and M (1 <= M <= 10000, 1 <= N <= 1000000). The second line contains N integers which indicate a[1], a[2], ...... , a[N]. The third line contains M integers which indicate b[1], b[2], ...... , b[M]. All integers are in the range of [-1000000, 1000000].
OutputFor each test case, you should output one line which only contain K described above. If no such K exists, output -1 instead.
Sample Input
2 13 5 1 2 1 2 3 1 2 3 1 3 2 1 2 1 2 3 1 3 13 5 1 2 1 2 3 1 2 3 1 3 2 1 2 1 2 3 2 1Sample Output
6 -1
#include<cstdio>
#include<cstring>
#include<iostream>
#include<algorithm>
using namespace std;
const int maxn = 1e6+5;
int nex[maxn];
int a[maxn],b[maxn];
int alen,blen;
void getnext(int* x,int xlen)
{
nex[0] = -1;
int k = -1;
for(int i = 1;i<xlen;i++)
{
while(k>-1 && x[k+1] != x[i])
{
k = nex[k];
}
if(x[k+1] == x[i]) k++;
nex[i] = k;
}
// for(int i = 0;i<xlen;i++){
// printf("%d ",nex[i]);
// }printf("\n");
}
int slove(int* x,int* y,int xlen,int ylen)
{
getnext(y,ylen);
int j = -1;
for(int i = 0;i<xlen;i++){
while(j>-1 && y[j+1] != x[i]){
j = nex[j];
}
if(y[j+1] == x[i]){
j++;
}
if(j == ylen - 1){
return i - j + 1;
}
}
return -1;
}
int main()
{
int t;
scanf("%d",&t);
while(t--)
{
scanf("%d %d",&alen,&blen);
for(int i = 0;i<alen;i++){
scanf("%d",&a[i]);
}
for(int i = 0;i<blen;i++){
scanf("%d",&b[i]);
}
int v = slove(a,b,alen,blen);
printf("%d\n",v);
}
return 0;
}
2264: sequence
题目描述
给定一个含n个数的序列A和一个含m (m<=n) 个数的序列B。
询问在A中有多少段连续的长为m的子序列Ak,Ak+1,…,Ak+m-1使得对于任意1<=i, j<=m满足Ak+i-1-Bi=Ak+j-1-Bj
输入
第一行两个整数n,m (1 <= m <= n <= 106)
接下来一行n个整数,描述序列A (Ai <= 109)
接下来一行m个整数,描述序列B (Bi <= 109)
输出
输出一个数表示答案
样例输入
7 46 6 8 5 5 7 47 7 9 6
样例输出
2
AC:代码
#include<cstdio>
#include<cstring>
#include<iostream>
#include<algorithm>
using namespace std;
const int maxn = 1e6+5;
int a[maxn],b[maxn],c[maxn];
int nex[maxn];
int n,m;
void getnext(int* x,int xlen)
{
nex[0] = -1;
int k = -1;
int j = 0;
while(j<xlen)
{
if(k == -1 || x[j] == x[k])
{
j++;
k++;
nex[j] = k;
} else {
k = nex[k];
}
}
// for(int i = 0;i<=xlen;i++){
// printf("%d ",nex[i]);
// }printf("\n");
}
int slove(int* x,int* y)
{
int xlen = n - 2,ylen = m - 1;
int j = 0,cnt = 0;
getnext(y,ylen - 1);
for(int i = 0;i<=xlen;i++){
while(j>-1 && x[i] != y[j]){
j = nex[j];
}
if(x[i] == y[j]) j++;
if(j == ylen ){
cnt++;
j = nex[j - 1] + 1;
}
}
// while(i<xlen && j<ylen)
// {
// if(j == -1 || a[i] == b[j]){
// j++;
// i++;
// } else {
// j = nex[j];
// }
// if( j == ylen - 1){
// cnt++;
//// printf("%d %d\n",i,j);
// i -= (nex[j]);
// j = 0;
//// printf("%d %d\n",i,j);
// }
// }
return cnt;
}
int main()
{
scanf("%d %d",&n,&m);
for(int i = 0;i<n;i++){
scanf("%d",&c[i]);
}
for(int i = 0;i<n-1;i++){
a[i] = c[i+1] - c[i];
}
for(int i = 0;i<m;i++){
scanf("%d",&c[i]);
}
for(int i = 0;i<m-1;i++){
b[i] = c[i+1] - c[i];
}
int s = slove(a,b);
printf("%d\n",s);
return 0;
}
The French author Georges Perec (1936–1982) once wrote a book, La disparition, without the letter 'e'. He was a member of the Oulipo group. A quote from the book:
Tout avait Pair normal, mais tout s’affirmait faux. Tout avait Fair normal, d’abord, puis surgissait l’inhumain, l’affolant. Il aurait voulu savoir où s’articulait l’association qui l’unissait au roman : stir son tapis, assaillant à tout instant son imagination, l’intuition d’un tabou, la vision d’un mal obscur, d’un quoi vacant, d’un non-dit : la vision, l’avision d’un oubli commandant tout, où s’abolissait la raison : tout avait l’air normal mais…
Perec would probably have scored high (or rather, low) in the following contest. People are asked to write a perhaps even meaningful text on some subject with as few occurrences of a given “word” as possible. Our task is to provide the jury with a program that counts these occurrences, in order to obtain a ranking of the competitors. These competitors often write very long texts with nonsense meaning; a sequence of 500,000 consecutive 'T's is not unusual. And they never use spaces.
So we want to quickly find out how often a word, i.e., a given string, occurs in a text. More formally: given the alphabet {'A', 'B', 'C', …, 'Z'} and two finite strings over that alphabet, a word W and a text T, count the number of occurrences of W in T. All the consecutive characters of W must exactly match consecutive characters of T. Occurrences may overlap.
InputThe first line of the input file contains a single number: the number of test cases to follow. Each test case has the following format:
Tout avait Pair normal, mais tout s’affirmait faux. Tout avait Fair normal, d’abord, puis surgissait l’inhumain, l’affolant. Il aurait voulu savoir où s’articulait l’association qui l’unissait au roman : stir son tapis, assaillant à tout instant son imagination, l’intuition d’un tabou, la vision d’un mal obscur, d’un quoi vacant, d’un non-dit : la vision, l’avision d’un oubli commandant tout, où s’abolissait la raison : tout avait l’air normal mais…
Perec would probably have scored high (or rather, low) in the following contest. People are asked to write a perhaps even meaningful text on some subject with as few occurrences of a given “word” as possible. Our task is to provide the jury with a program that counts these occurrences, in order to obtain a ranking of the competitors. These competitors often write very long texts with nonsense meaning; a sequence of 500,000 consecutive 'T's is not unusual. And they never use spaces.
So we want to quickly find out how often a word, i.e., a given string, occurs in a text. More formally: given the alphabet {'A', 'B', 'C', …, 'Z'} and two finite strings over that alphabet, a word W and a text T, count the number of occurrences of W in T. All the consecutive characters of W must exactly match consecutive characters of T. Occurrences may overlap.
One line with the word W, a string over {'A', 'B', 'C', …, 'Z'}, with 1 ≤ |W| ≤ 10,000 (here |W| denotes the length of the string W).
One line with the text T, a string over {'A', 'B', 'C', …, 'Z'}, with |W| ≤ |T| ≤ 1,000,000.
OutputFor every test case in the input file, the output should contain a single number, on a single line: the number of occurrences of the word W in the text T.
Sample Input
3 BAPC BAPC AZA AZAZAZA VERDI AVERDXIVYERDIANSample Output
1 3 0题意:其实就是让你求出b串在a中出现的次数
#include<cstdio>
#include<cstring>
#include<iostream>
#include<algorithm>
using namespace std;
const int maxn = 1e6+5;
char a[maxn],b[maxn],temp[maxn];
int nex[maxn];
void getnext(char* x,int xlen)
{
nex[0] = -1;
int k = -1;
for(int i = 1;i<xlen;i++)
{
while(k>-1 && x[k+1] != x[i])
{
k = nex[k];
}
if(x[k+1] == x[i])
{
k++;
}
nex[i] = k;
}
// for(int i = 0;i<xlen;i++){
// printf("%d ",nex[i]);
// }printf("\n");
}
int slove(char* x,char* y,int xlen,int ylen)
{
getnext(y,ylen);
int k = -1,cnt = 0;
for(int i = 0;i<xlen;i++){
while(k>-1 && y[k+1] != x[i]){
k = nex[k];
}
if(y[k+1] == x[i]){
k++;
}
if(k == ylen - 1){
cnt++;
k = nex[k];
}
}
return cnt;
}
int main()
{
int t;
scanf("%d",&t);
while(t--)
{
scanf("%s %s",a,b);
int alen = strlen(a),blen = strlen(b);
if(blen>alen){
for(int i = 0;i<alen;i++){
temp[i] = a[i];
}
for(int i = 0;i<blen;i++){
a[i] = b[i];
}
for(int i = 0;i<alen;i++){
b[i] = temp[i];
}
int m = alen;
alen = blen;
blen = m;
}
int v = slove(a,b,alen,blen);
printf("%d\n",v);
}
return 0;
}
P3375 【模板】KMP字符串匹配
题目描述
如题,给出两个字符串s1和s2,其中s2为s1的子串,求出s2在s1中所有出现的位置。
为了减少骗分的情况,接下来还要输出子串的前缀数组next。
(如果你不知道这是什么意思也不要问,去百度搜[kmp算法]学习一下就知道了。)
输入输出格式
输入格式:第一行为一个字符串,即为s1
第二行为一个字符串,即为s2
输出格式:若干行,每行包含一个整数,表示s2在s1中出现的位置
接下来1行,包括length(s2)个整数,表示前缀数组next[i]的值。
输入输出样例
说明
时空限制:1000ms,128M
数据规模:
设s1长度为N,s2长度为M
对于30%的数据:N<=15,M<=5
对于70%的数据:N<=10000,M<=100
对于100%的数据:N<=1000000,M<=1000000
样例说明:
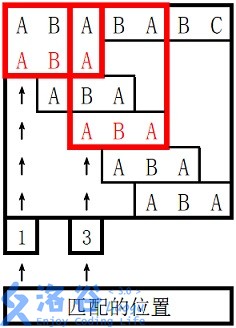
所以两个匹配位置为1和3,输出1、3
- #include<cstdio>
- #include<cstring>
- #include<iostream>
- #include<algorithm>
- using namespace std;
- const int maxn = 1000000 + 5;
- char a[maxn],b[maxn];
- int nex[maxn];
- int alen,blen;
- void getnext(char* x,int xlen){
- nex[0] = -1;
- int k = -1;
- for(int i = 1;i<xlen;i++){
- while(k>-1 && x[k+1] != x[i]){
- k = nex[k];
- }
- if(x[k+1] == x[i]){
- k++;
- }
- nex[i] = k;
- }
- // for(int i = 0;i<xlen;i++){
- // printf("%d ",nex[i]);
- // }
- }
- void slove(char* x,char* y,int xlen,int ylen)
- {
- getnext(y,ylen);
- int k = -1;
- for(int i = 0;i<xlen;i++){
- while( k>-1 && y[k+1] != x[i]){
- k = nex[k];
- }
- if( y[k+1] == x[i] ) k++;
- if(k == ylen - 1){
- printf("%d\n",i - k + 1);
- k = nex[k-1]+1;
- }
- }
- }
- int main()
- {
- scanf("%s %s",a,b);
- int alen = strlen(a),blen = strlen(b);
- slove(a,b,alen,blen);
- for(int i = 0;i<blen;i++){
- printf("%d ",nex[i]+1);
- }
- return 0;
- }