Tomcat启动是由Bootstrap开始的,大家都知道Tomcat最顶层的容器是Server,而Server又是是由Catalina调用的,理论上可以不用Bootstrap,只用Catalina就可以启动tomat了,使用Bootstrap的理由是。设计者希望有多种方式启动Tomcat,Catalina是一种固定的启动方式,而调用它的方式可能有很多种,Bootstrap是用命令行的方式去调用Catalina,但也可能有其他方式。不过Bootstrap目前就是Tomcat默认的启动方式了,启动分为初始化和正式启动。下面看一下初始化的过程,
Tomcat启动初始化时序图:
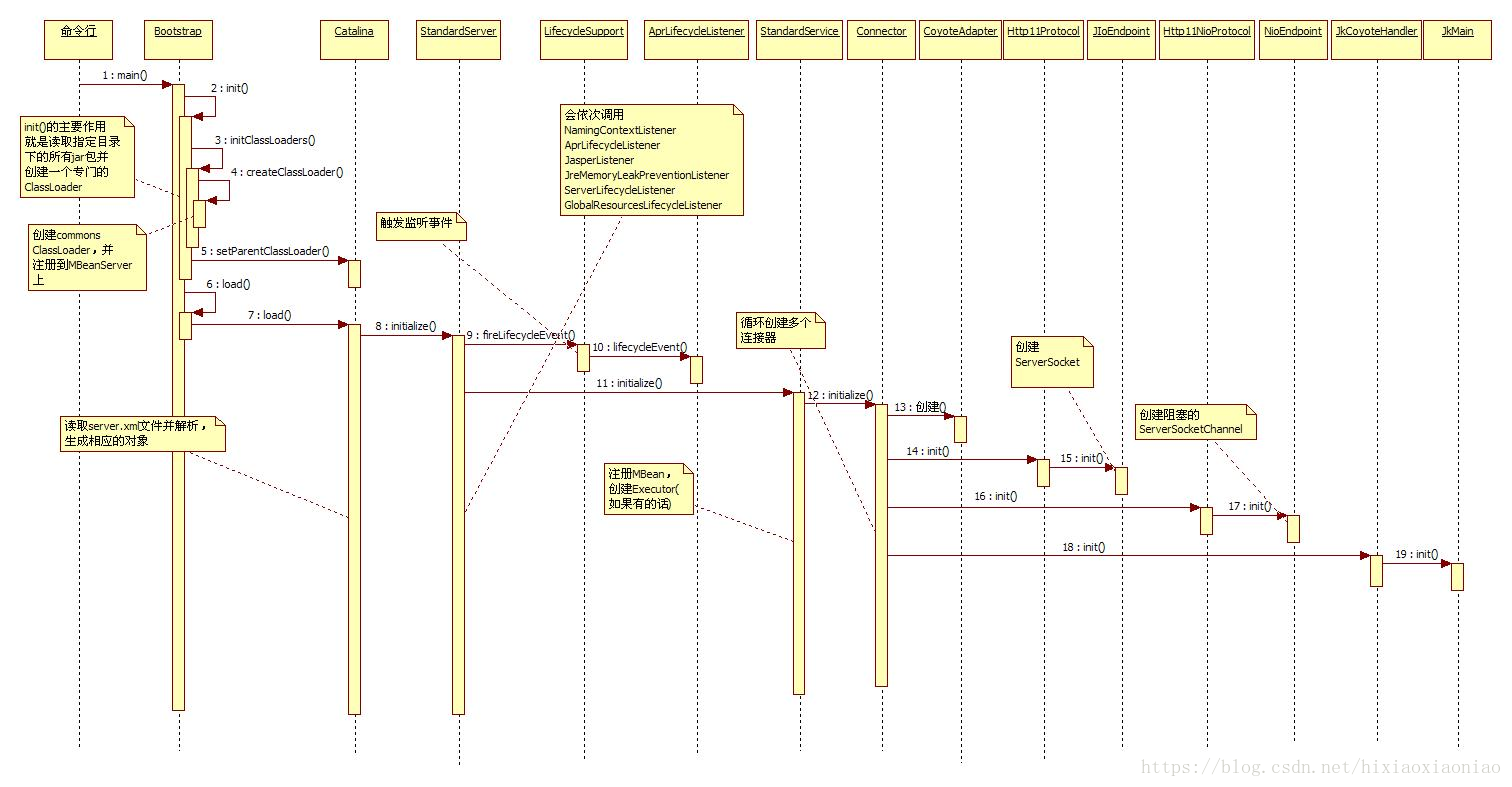
命令行启动会调用到Boostrap的main()方法中,首先Bootstrap会执行init(),它会初始化类装载器,然后创建容器所需用的类装载器,Tomcat6类装载器结构有了一些变化。
5.5的类装载器结构如下:

6.0的类装载器结构如下:
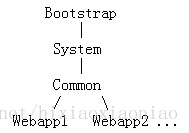
可以看到6.0取消了Catalina和Shared两个类装载器,只有一个commons类装载器了,如果想继续使用5.5的类装载器,可以通过修改配置文件
%TOMCAT_HOME%/conf/catalina.properties
这个文件里面定义了三个类装载器需用装载的目录,以及jar,只有common.loader有值,server.loader和shared.loader都是空的。
创建完类装载器之后就将类装载器赋给Ctalina,因为以后都是由Catalina管理容器了。
所以Bootstrap#init()的主要作用就是读取指定目录下的所有jar包并创建一个专门的ClassLoader
介绍完init()在看看load(),Bootstrap的load()会通过反射调用Catalina#load(),严格来说这里才能叫做初始化,因为后面的调用过程才是真正的初始化容器。Ctalina会去调用Server的initialize(),Server就是Tomcat最顶层的容器了,所以现在就开始真正初始化容器了,Server初始化的时候会触发一个监听器,这里使用的是观察者模式。关于Tomcat的设计模式请看《Tomcat源码分析---设计模式》一文。
和Server关联的监听器一共有6个,其中有一个是默认的,其余5个是在配置文件中定义的。
在调用第九步 LifecycleSupport,会依次调用NamingContextListener, AprLifecycleListener ,JasperListener
JreMemoryLeakPreventionListener ,ServerLifecycleListener ,GlobalResourcesLifecycleListener 六个监听器。
除了调用监听器另外一个工作就是注册MBean了。
Server会根据配置文件拿到它下面定义的子元素Service,由于Service可能有多个,所以这是一个循环调用的启动过程,Service#initialize()先注册MBean,然后初始化它下面的连接器和线程池,这两个元素都会有多个所以是一个循环初始化过程。Service会判断是否配置了线程池,如果配置了就注册相应的MBean,然后开始循环初始化连接器。
初始化连接器会调用Connector,接着Connector会创建一个CoyoteAdapter,将这个适配器赋给各种不同的连接器。
1.对于BIO会调用Http11Protocol#init(),由它再调用JIoEndpoint#init(),此时会创建一个ServerSocket。
2.对于NIO会调用Http11NioProtocol#init(),由它再调用NioEndpoint#inti(),此时会创建一个阻塞模式的ServerSocketChannel。
3.对于AJP会调用JkCoyoteHandler#inti(),再由它调用JkMain#init(),此时不会创建Socket,只是初始化配置参数。
现在初始化的工作就完成了,下面就要开始启动了,启动过程非常复杂,主要是部署的过程很麻烦,所以单独拿了出来。
启动过程我把分了三部分介绍,首先是启动容器过程(不包括部署),然后单独介绍一下启动的部署过程,最后是连接器和线程池的启动。第二部分最麻烦,最后一部分最简单。
下面看一下启动容器(不包括部署)的时序图:

Tomcat启动初始化时序图:
命令行启动会调用到Boostrap的main()方法中,首先Bootstrap会执行init(),它会初始化类装载器,然后创建容器所需用的类装载器,Tomcat6类装载器结构有了一些变化。
5.5的类装载器结构如下:
6.0的类装载器结构如下:
可以看到6.0取消了Catalina和Shared两个类装载器,只有一个commons类装载器了,如果想继续使用5.5的类装载器,可以通过修改配置文件
%TOMCAT_HOME%/conf/catalina.properties
这个文件里面定义了三个类装载器需用装载的目录,以及jar,只有common.loader有值,server.loader和shared.loader都是空的。
创建完类装载器之后就将类装载器赋给Ctalina,因为以后都是由Catalina管理容器了。
所以Bootstrap#init()的主要作用就是读取指定目录下的所有jar包并创建一个专门的ClassLoader
介绍完init()在看看load(),Bootstrap的load()会通过反射调用Catalina#load(),严格来说这里才能叫做初始化,因为后面的调用过程才是真正的初始化容器。Ctalina会去调用Server的initialize(),Server就是Tomcat最顶层的容器了,所以现在就开始真正初始化容器了,Server初始化的时候会触发一个监听器,这里使用的是观察者模式。关于Tomcat的设计模式请看《Tomcat源码分析---设计模式》一文。
和Server关联的监听器一共有6个,其中有一个是默认的,其余5个是在配置文件中定义的。
在调用第九步 LifecycleSupport,会依次调用NamingContextListener, AprLifecycleListener ,JasperListener
JreMemoryLeakPreventionListener ,ServerLifecycleListener ,GlobalResourcesLifecycleListener 六个监听器。
除了调用监听器另外一个工作就是注册MBean了。
Server会根据配置文件拿到它下面定义的子元素Service,由于Service可能有多个,所以这是一个循环调用的启动过程,Service#initialize()先注册MBean,然后初始化它下面的连接器和线程池,这两个元素都会有多个所以是一个循环初始化过程。Service会判断是否配置了线程池,如果配置了就注册相应的MBean,然后开始循环初始化连接器。
初始化连接器会调用Connector,接着Connector会创建一个CoyoteAdapter,将这个适配器赋给各种不同的连接器。
1.对于BIO会调用Http11Protocol#init(),由它再调用JIoEndpoint#init(),此时会创建一个ServerSocket。
2.对于NIO会调用Http11NioProtocol#init(),由它再调用NioEndpoint#inti(),此时会创建一个阻塞模式的ServerSocketChannel。
3.对于AJP会调用JkCoyoteHandler#inti(),再由它调用JkMain#init(),此时不会创建Socket,只是初始化配置参数。
现在初始化的工作就完成了,下面就要开始启动了,启动过程非常复杂,主要是部署的过程很麻烦,所以单独拿了出来。
启动过程我把分了三部分介绍,首先是启动容器过程(不包括部署),然后单独介绍一下启动的部署过程,最后是连接器和线程池的启动。第二部分最麻烦,最后一部分最简单。
下面看一下启动容器(不包括部署)的时序图:
调用start()是从Bootstrap开始的,实际上是通过命令行用户输入start还是stop等命令然后判断再调用相应方法,从Bootstrap-->Catalina-->Server,这个流程都很简单,调用到Server的时候会触发6个和它相关的监听器。之后Server会调用Service,此时Service会先启动容器再启动连接器和线程池。根据配置文件描述,Service下面的容器只有一个,但是连接器和线程池可以有多个。Service调用StandardEngine#start(),开始启动容器了,引擎会先初始化,注册MBean然后调用它的父类ContainerBase,这里是很关键的一步,在启动,停止,后台线程调用的时候都会利用他们的父类进行一些判断,
ContainerBase#start()方法如下:(去掉了注释)
public synchronized void start() throws LifecycleException {
if (started) {
if(log.isInfoEnabled())
log.info(sm.getString( "containerBase.alreadyStarted", logName()));
return;
}
lifecycle.fireLifecycleEvent( BEFORE_START_EVENT, null);
started = true;
if ((loader != null) && (loader instanceof Lifecycle))
(( Lifecycle) loader).start();
logger = null;
getLogger();
if ((logger != null) && (logger instanceof Lifecycle))
(( Lifecycle) logger).start();
if ((manager != null) && (manager instanceof Lifecycle))
(( Lifecycle) manager).start();
if ((cluster != null) && (cluster instanceof Lifecycle))
(( Lifecycle) cluster).start();
if ((realm != null) && (realm instanceof Lifecycle))
(( Lifecycle) realm).start();
if ((resources != null) && (resources instanceof Lifecycle))
(( Lifecycle) resources).start();
Container children[] = findChildren();
for (int i = 0; i < children.length; i++) {
if (children[i] instanceof Lifecycle)
(( Lifecycle) children[i]).start();
}
if (pipeline instanceof Lifecycle) {
(( Lifecycle) pipeline).start();
}
lifecycle.fireLifecycleEvent( START_EVENT, null);
threadStart(); //启动后台线程
lifecycle.fireLifecycleEvent( AFTER_START_EVENT, null);
}
Tomcat的容器包含了引擎,主机,上下文,包装,而每个容器都继承了ContainerBase,而容器可能会和Loader,Logger,Manager,Realm,
Cluster,Resource,Pipeline这些子组件关联,当然了,不是每个组件能包含全部这7个组件的,像主机和引擎就不包含Manager,而上下文包含了Manager,所以它可以管理session,而容器包含的这些子组件是在Digster在读取配置的时候完成的。也就是一创建好容器就会默认和一些子组件关联了。由于ContainerBase包含的这一系列操作,使得容器和它的子容器可以顺利完成关联组件的启动。
由于引擎关联了一个Realm,所以会去启动这个realm,也就是UserDatabaseRealm,另外它还会触发和自身绑定的监听器EngineConfig,不过这个监听器只是简单记录日志而已,啥也没做。最后会调用父类RealmBase#start(),在ContainerBase中会查找当前容器的所有子容器,然后启动所有的子容器,引擎下面就是主机,所以会去调用StandardHost#start()。
StandardHost会先调用init()注册MBean,另外StandardHost里有一个错误报告的valve,会委托父类ContainerBase加入到StandardPipeline中。接着调用父类ContainerBase#start(),此时主机没有任何管理的其他组件,所以一个也不会开启,默认情况下也没有子元素,所以也不会调用子元素的启动方法。 这里有一点很奇怪,一个主机下面可以部署多个应用,那么按理说主机可以有多个StandardContext,然后依次去执行这些上下文的启动。请注意,这里读取子元素是按照配置文件来的,也就是%CATALINA_HOME%/conf下的server.xml文件里描述的内容,这个xml文件里面Host节点默认是没有值的,所以也就取不到子元素了,那么上下文是怎么执行的呢?它是通过事件监听的方式触发的,回头再看一下ContainerBase#start()方法里的内容,在调用完pipeline的start()后,会执行一个事件监听,
lifecycle.fireLifecycleEvent( START_EVENT, null);
这样就会触发和主机关联的若干监听器,默认情况下主机只有一个监听器,叫HostConfig,所有的部署工作,找寻子元素Context的过程就是由它来完成的。事件监听会触发它的start()方法,接着会调用自身的deployApps()方法,这个方法的作用就是将tomcat的 webapp目录下的所有应用部署上。这个部署过程很复杂,会独单介绍,现在跳过去,继续看后面的过程。
StandardHost最后会委托父类调用自身的threadStart(),这里会开启一个后台线程,默认情况下主机是不会开启线程的。之后主机部分就执行完了,然后返回给引擎,引擎同样会委托父类ContainerBase调用threadStart(),此时就会开启一个后台线程,所以后台线程实际上是由引擎开启的,为什么是由引擎开启呢?因为引擎是所有容器里面最高的一个,由它开启后台线程后,这个后台线程就能依次读取到和当前容器相关联的子容器,然后依次执行子容器的后台方法,所以放在引擎里是最合适的。
引擎执行完了会返回给StandardService,此时会启动连接器,线程池,这里先略过。Service执行完后就又会会返回给StandardServer,Server也没做什么事,继续返回给Catalina,此时Catalina会向JVM注册一个后台线程CatalinaShutdownHook,这是一个线程类,它的run()方法会在停止的时候被调用,什么时候停止,当用户在已经启动的DOS窗口按下ctrl+C就会触发了。注册完钩子线程后,Catalina会调用自己的await()方法,此时会启动一个ServerSocket,默认会在8005,也就是配置文件中定义的端口监听连接,由于是BIO的连接,所以会一直等待,那什么时候会接收到数据呢?当用户执行了shutdown.bat命令后,会触发一个socket连接,这样就会await()就会继续执行了,await()后面是stop()方法,这样就能将容器关闭了。
说到这里,容器的启动过程(不包含部署)也就介绍完了。
现在来介绍一下迄今为止,最复杂的启动过程,启动时的部署过程,
首先看一下部署的时序图:
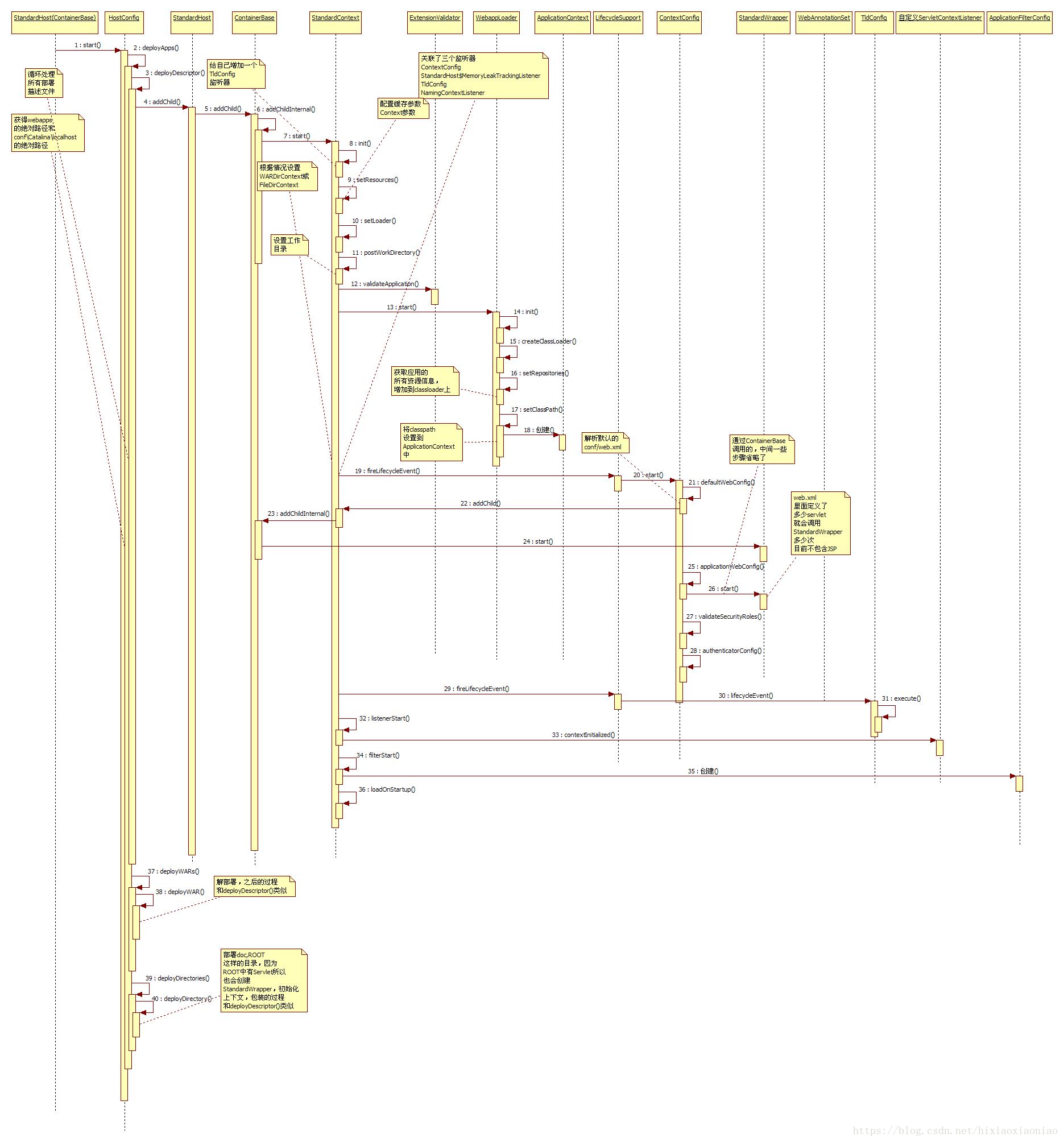
还记得HostConfig是怎么被调用的吗?首先是StandardHost调用父类ContainerBase#start(),然后调用和它相关的组件,子容器,这些都没有,最后会触发一个事件监听,这样就调到了HostConfig。HostConfig会调用自己的deployApps(),执行各种类型的应用部署:
// Deploy XML descriptors from configBase
deployDescriptors(configBase, configBase.list());
// Deploy WARs, and loop if additional descriptors are found
deployWARs(appBase, filteredAppPaths);
// Deploy expanded folders
deployDirectories(appBase, filteredAppPaths);
其实从它的注释中就看以看出这三个方法是什么意思了,第一个deployDescriptors()是根据描述文件部署,第二个deployWARs()当然就是部署一个WAR类型的压缩包,第三个deployDirectories()是部署一个目录。
这第二个很好理解,第一和第三个有什么区别呢?假设我们使用的都是默认配置,那么在%CATALINA_HOME%/conf/Catalina/localhost目录下会有若干个xml文件,部署的时候就是根据这个描述文件来的。这个描述文件应该是应用的名字.xml这样的形式。这个xml文件应该是放在应用的META-INF目录下。当处理目录应用的时候如果检查到主目录下有META-INF并且里面有以应用的名字.xml的文件,就会将这个文件放到/conf/Catalina/localhost目录下,呵呵,其实这个过程我并没有调试过,只是猜测的。这三个方法的处理过程大致是比较相似的,所以以第一个,根据描述文件部署来说明。
当执行deployDescriptors()后,会将/conf/Catalina/localhost目录下的描述文件都列出来,然后一一遍历,当找到一个xml文件后,就认为它是一个上下文,会将这个上下文加到主机上,所以HostConfig会调用StandardHost#addChild(),这样又会调用ContainerBase#addChildInternal(),最后将StandardContext增加到主机上,之后就会调用StandardContext#start()。
StandardContext执行过程如下:
1.init(),这会将一个TldConfig监听器增加到自己身上,不用说这个是用来解析TLD文件用的。
2.setResources(),这个用来配置配置缓存参数和Context参数
3.setLoader() 找到和自己相关的loader,这里就是WebappLoader
4.postWorkDirectory() 这是用来设置工作目录work的路径的
5.调用ExtensionValidator#validateApplication(),它用来验证META-INF目录下的MANIFEST.MF ,这个文件有对jar的描述,用来对它做验证。
6.启动WebappLoader#start()它的执行过程如下:
1)init()注册MBean
2)createClassLoader() 创建WebappClassLoader
3)setRepositories() 获取应用的所有资源信息,增加到classloader上
4)setClassPath() 创建ApplicationContext,然后将classpath设置到ApplicationContext上
以上执行完后,会触发一个事件监听,调用ContextConfig#start(),这会调用自身的defaultWebConfig(),它会解析默认的conf/web.xml,这里先说明一下,每个在配置文件中定义的Servlet都会对应一个包装,如果是InvoktionServlet,就是那种不需要配置定义就可以被调用的,可能对应的不是一个包装,另外jsp文件对应的是JspServlet,默认的web.xml文件里有DefaultServlet和JspServlet,所以会创建两个包装类,ContextConfig会调用StandardContext#addChild(),它会继续调用ContainerBase#addChildInternal(),然后启动这个子容器,也就是StandardWrapper#start()。 ContextConfig会继续执行自己的applicationWebConfig(),这是解析将应用本身的web.xml,由于这个文件中可能也定义了若干servlet,所以和处理defaultWebConfig()一样,最终也会使得ContainerBase调用StandardWrapper,将这个子容器加入。
ContextConfig会继续执行两个方法validateSecurityRoles()和authenticatorConfig()这是解析安全认证相关的。
7.以上执行完了会回到StandardContext,它会触发一个事件监听,这会调用到TldConfig#execute(),做一些tld解析的工作。
8.接着StandardContext执行listenerStart(),它将所有定义的Listener加入到map中,同时会调用自定义ServletContextListener的
contextInitialized()方法
9.调用filterStart(),这会创建ApplicationFilterConfig
10.调用loadOnStartup(),如果有servlet需要启动就运行的话,就会调用StandardWrapper#load(),它会用WebappClassLoader
去装载指定的Servlet,当装载完后就执行它的init()方法
这些过后deployDescriptors()方法终于就执行完了
再来看看deployWARs(),它会遍历指定目录下的所有war,然后将这个war包给解压,解压完了之后的执行过程和deployDescriptors()几乎差不多了,这里就省略了。
最后看看deployDirectories(),它遍历指定目录下的所有目录,就是那些非描述应用,非war的应用,比如DOC,ROOT这样的应用,我们平常部署一个应用也是属于这种应用,它的部署过程也是和deployDescriptors()差不多的
这样三个部署就执行完了,现在看看三种部署在启动的时候有什么区别
启动Tomcat的时候可以看到目录,描述文件,WAR部署的区别:
2011-8-30 18:23:09 org.apache.catalina.startup.HostConfig deployDescriptor
信息: Deploying configuration descriptor manager.xml
2011-8-30 18:23:09 org.apache.catalina.startup.HostConfig deployDescriptor
信息: Deploying configuration descriptor test.xml
2011-8-30 18:23:09 org.apache.catalina.startup.HostConfig deployWAR
信息: Deploying web application archive struts2-blank.war
2011-8-30 18:23:10 com.opensymphony.xwork2.util.logging.jdk.JdkLogger info
信息: Parsing configuration file [struts-default.xml]
2011-8-30 18:23:11 com.opensymphony.xwork2.util.logging.jdk.JdkLogger info
信息: Unable to locate configuration files of the name struts-plugin.xml, skippi
ng
2011-8-30 18:23:11 com.opensymphony.xwork2.util.logging.jdk.JdkLogger info
信息: Parsing configuration file [struts-plugin.xml]
2011-8-30 18:23:11 com.opensymphony.xwork2.util.logging.jdk.JdkLogger info
信息: Parsing configuration file [struts.xml]
2011-8-30 18:23:11 org.apache.catalina.startup.HostConfig deployDirectory
信息: Deploying web application directory docs
2011-8-30 18:23:11 org.apache.catalina.startup.HostConfig deployDirectory
信息: Deploying web application directory examples
2011-8-30 18:23:11 org.apache.catalina.startup.HostConfig deployDirectory
信息: Deploying web application directory ROOT
启动过程的前两部分介绍完了,第三部分是最简单的启动线程池和连接器
下面是启动线程池和连接器的时序图:
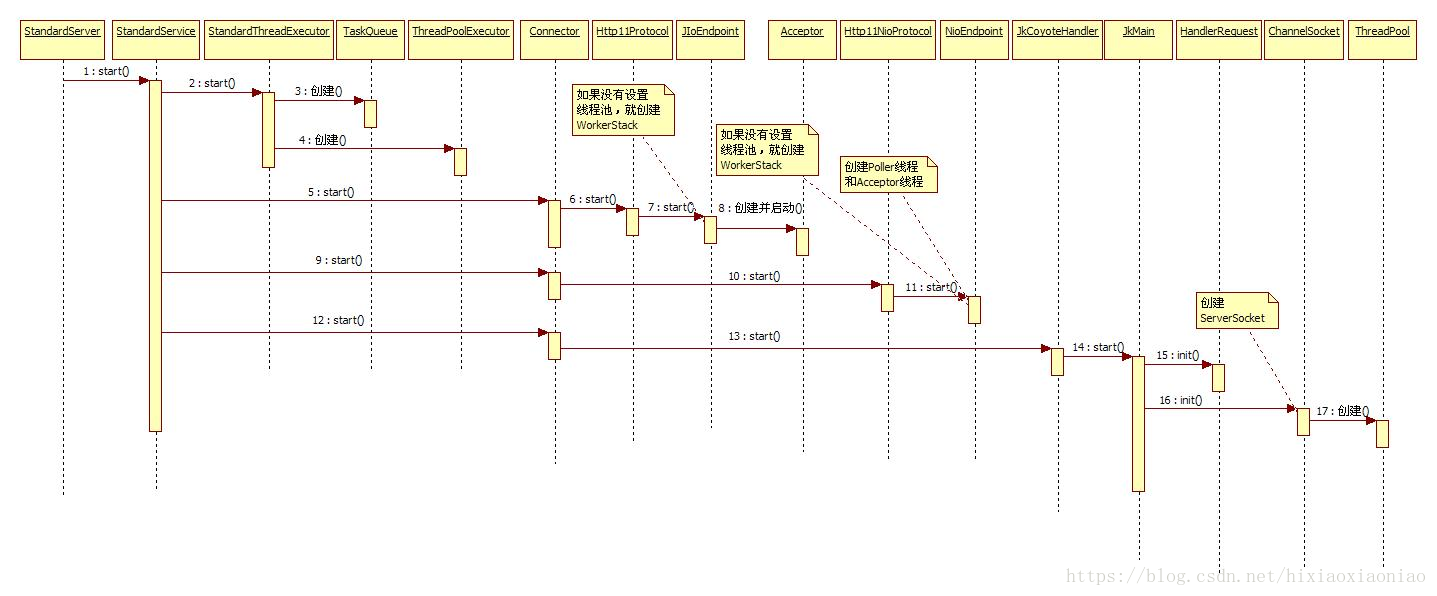
调用过程从StandardService开始,之前已经启动过了容器,下面就是线程池,因为线程池可能有多个,所以是循环启动,先是调用StandardThreadExecutor#start(),这是默认的线程池实现,它分别创建了TaskQueue和ThreadPoolExecutor,在创建ThreadPoolExecutor 的时候用TaskQueue作为参数,TaskQueue继承了LinkedBlockingQueue,所以Tomcat的线程池实际上使用的是JDK的线程池。线程池是如何跟连接器管理的呢?JioEndpoint有这么一段:
/**
* External Executor based thread pool.
*/
protected Executor executor = null;
public void setExecutor( Executor executor) { this.executor = executor; }
public Executor getExecutor() { return executor; }
所以应该通过配置文件创建连接器的时候设置上的,这一点就不用我们关心了。
假设我们配置了BIO,NIO,AJP三种连接器,他们的启动过程很类似,都是由StandardService调用Connector#start(),由Connector负责启动一个具体的连接器,
1.如果是BIO就调用Http11Protocol#start(),再由它调用JIoEndpoint#start(),由它创建并启动接收线程
2.如果是NIO就调用Http11NioProtocol#start()。,再由它调用NioEndpoint#start(),并创建启动Poller和接收线程
3.如果是AJP就调用JkCoyoteHandler#start(),再调用JkMain#start(),JkMain会分别调用HandlerRequest和ChannelSocket的
init(),ChannelSocket#init()里会创建ServerSocket并调用accept(),同时创建ThreadPool。
经过漫长的等待,Tomcat就启动完成了,启动的时候会注册一大堆MBean,注册MBean使用了apache的commons-modeler这个工具,解析xml使用的是digester这个工具。从启动过程来看连接器和线程池启动都不复杂,最复杂的就是容器,其中部署又是容器中最复杂的。
ContainerBase#start()方法如下:(去掉了注释)
public synchronized void start() throws LifecycleException {
if (started) {
if(log.isInfoEnabled())
log.info(sm.getString( "containerBase.alreadyStarted", logName()));
return;
}
lifecycle.fireLifecycleEvent( BEFORE_START_EVENT, null);
started = true;
if ((loader != null) && (loader instanceof Lifecycle))
(( Lifecycle) loader).start();
logger = null;
getLogger();
if ((logger != null) && (logger instanceof Lifecycle))
(( Lifecycle) logger).start();
if ((manager != null) && (manager instanceof Lifecycle))
(( Lifecycle) manager).start();
if ((cluster != null) && (cluster instanceof Lifecycle))
(( Lifecycle) cluster).start();
if ((realm != null) && (realm instanceof Lifecycle))
(( Lifecycle) realm).start();
if ((resources != null) && (resources instanceof Lifecycle))
(( Lifecycle) resources).start();
Container children[] = findChildren();
for (int i = 0; i < children.length; i++) {
if (children[i] instanceof Lifecycle)
(( Lifecycle) children[i]).start();
}
if (pipeline instanceof Lifecycle) {
(( Lifecycle) pipeline).start();
}
lifecycle.fireLifecycleEvent( START_EVENT, null);
threadStart(); //启动后台线程
lifecycle.fireLifecycleEvent( AFTER_START_EVENT, null);
}
Tomcat的容器包含了引擎,主机,上下文,包装,而每个容器都继承了ContainerBase,而容器可能会和Loader,Logger,Manager,Realm,
Cluster,Resource,Pipeline这些子组件关联,当然了,不是每个组件能包含全部这7个组件的,像主机和引擎就不包含Manager,而上下文包含了Manager,所以它可以管理session,而容器包含的这些子组件是在Digster在读取配置的时候完成的。也就是一创建好容器就会默认和一些子组件关联了。由于ContainerBase包含的这一系列操作,使得容器和它的子容器可以顺利完成关联组件的启动。
由于引擎关联了一个Realm,所以会去启动这个realm,也就是UserDatabaseRealm,另外它还会触发和自身绑定的监听器EngineConfig,不过这个监听器只是简单记录日志而已,啥也没做。最后会调用父类RealmBase#start(),在ContainerBase中会查找当前容器的所有子容器,然后启动所有的子容器,引擎下面就是主机,所以会去调用StandardHost#start()。
StandardHost会先调用init()注册MBean,另外StandardHost里有一个错误报告的valve,会委托父类ContainerBase加入到StandardPipeline中。接着调用父类ContainerBase#start(),此时主机没有任何管理的其他组件,所以一个也不会开启,默认情况下也没有子元素,所以也不会调用子元素的启动方法。 这里有一点很奇怪,一个主机下面可以部署多个应用,那么按理说主机可以有多个StandardContext,然后依次去执行这些上下文的启动。请注意,这里读取子元素是按照配置文件来的,也就是%CATALINA_HOME%/conf下的server.xml文件里描述的内容,这个xml文件里面Host节点默认是没有值的,所以也就取不到子元素了,那么上下文是怎么执行的呢?它是通过事件监听的方式触发的,回头再看一下ContainerBase#start()方法里的内容,在调用完pipeline的start()后,会执行一个事件监听,
lifecycle.fireLifecycleEvent( START_EVENT, null);
这样就会触发和主机关联的若干监听器,默认情况下主机只有一个监听器,叫HostConfig,所有的部署工作,找寻子元素Context的过程就是由它来完成的。事件监听会触发它的start()方法,接着会调用自身的deployApps()方法,这个方法的作用就是将tomcat的 webapp目录下的所有应用部署上。这个部署过程很复杂,会独单介绍,现在跳过去,继续看后面的过程。
StandardHost最后会委托父类调用自身的threadStart(),这里会开启一个后台线程,默认情况下主机是不会开启线程的。之后主机部分就执行完了,然后返回给引擎,引擎同样会委托父类ContainerBase调用threadStart(),此时就会开启一个后台线程,所以后台线程实际上是由引擎开启的,为什么是由引擎开启呢?因为引擎是所有容器里面最高的一个,由它开启后台线程后,这个后台线程就能依次读取到和当前容器相关联的子容器,然后依次执行子容器的后台方法,所以放在引擎里是最合适的。
引擎执行完了会返回给StandardService,此时会启动连接器,线程池,这里先略过。Service执行完后就又会会返回给StandardServer,Server也没做什么事,继续返回给Catalina,此时Catalina会向JVM注册一个后台线程CatalinaShutdownHook,这是一个线程类,它的run()方法会在停止的时候被调用,什么时候停止,当用户在已经启动的DOS窗口按下ctrl+C就会触发了。注册完钩子线程后,Catalina会调用自己的await()方法,此时会启动一个ServerSocket,默认会在8005,也就是配置文件中定义的端口监听连接,由于是BIO的连接,所以会一直等待,那什么时候会接收到数据呢?当用户执行了shutdown.bat命令后,会触发一个socket连接,这样就会await()就会继续执行了,await()后面是stop()方法,这样就能将容器关闭了。
说到这里,容器的启动过程(不包含部署)也就介绍完了。
现在来介绍一下迄今为止,最复杂的启动过程,启动时的部署过程,
首先看一下部署的时序图:
还记得HostConfig是怎么被调用的吗?首先是StandardHost调用父类ContainerBase#start(),然后调用和它相关的组件,子容器,这些都没有,最后会触发一个事件监听,这样就调到了HostConfig。HostConfig会调用自己的deployApps(),执行各种类型的应用部署:
// Deploy XML descriptors from configBase
deployDescriptors(configBase, configBase.list());
// Deploy WARs, and loop if additional descriptors are found
deployWARs(appBase, filteredAppPaths);
// Deploy expanded folders
deployDirectories(appBase, filteredAppPaths);
其实从它的注释中就看以看出这三个方法是什么意思了,第一个deployDescriptors()是根据描述文件部署,第二个deployWARs()当然就是部署一个WAR类型的压缩包,第三个deployDirectories()是部署一个目录。
这第二个很好理解,第一和第三个有什么区别呢?假设我们使用的都是默认配置,那么在%CATALINA_HOME%/conf/Catalina/localhost目录下会有若干个xml文件,部署的时候就是根据这个描述文件来的。这个描述文件应该是应用的名字.xml这样的形式。这个xml文件应该是放在应用的META-INF目录下。当处理目录应用的时候如果检查到主目录下有META-INF并且里面有以应用的名字.xml的文件,就会将这个文件放到/conf/Catalina/localhost目录下,呵呵,其实这个过程我并没有调试过,只是猜测的。这三个方法的处理过程大致是比较相似的,所以以第一个,根据描述文件部署来说明。
当执行deployDescriptors()后,会将/conf/Catalina/localhost目录下的描述文件都列出来,然后一一遍历,当找到一个xml文件后,就认为它是一个上下文,会将这个上下文加到主机上,所以HostConfig会调用StandardHost#addChild(),这样又会调用ContainerBase#addChildInternal(),最后将StandardContext增加到主机上,之后就会调用StandardContext#start()。
StandardContext执行过程如下:
1.init(),这会将一个TldConfig监听器增加到自己身上,不用说这个是用来解析TLD文件用的。
2.setResources(),这个用来配置配置缓存参数和Context参数
3.setLoader() 找到和自己相关的loader,这里就是WebappLoader
4.postWorkDirectory() 这是用来设置工作目录work的路径的
5.调用ExtensionValidator#validateApplication(),它用来验证META-INF目录下的MANIFEST.MF ,这个文件有对jar的描述,用来对它做验证。
6.启动WebappLoader#start()它的执行过程如下:
1)init()注册MBean
2)createClassLoader() 创建WebappClassLoader
3)setRepositories() 获取应用的所有资源信息,增加到classloader上
4)setClassPath() 创建ApplicationContext,然后将classpath设置到ApplicationContext上
以上执行完后,会触发一个事件监听,调用ContextConfig#start(),这会调用自身的defaultWebConfig(),它会解析默认的conf/web.xml,这里先说明一下,每个在配置文件中定义的Servlet都会对应一个包装,如果是InvoktionServlet,就是那种不需要配置定义就可以被调用的,可能对应的不是一个包装,另外jsp文件对应的是JspServlet,默认的web.xml文件里有DefaultServlet和JspServlet,所以会创建两个包装类,ContextConfig会调用StandardContext#addChild(),它会继续调用ContainerBase#addChildInternal(),然后启动这个子容器,也就是StandardWrapper#start()。 ContextConfig会继续执行自己的applicationWebConfig(),这是解析将应用本身的web.xml,由于这个文件中可能也定义了若干servlet,所以和处理defaultWebConfig()一样,最终也会使得ContainerBase调用StandardWrapper,将这个子容器加入。
ContextConfig会继续执行两个方法validateSecurityRoles()和authenticatorConfig()这是解析安全认证相关的。
7.以上执行完了会回到StandardContext,它会触发一个事件监听,这会调用到TldConfig#execute(),做一些tld解析的工作。
8.接着StandardContext执行listenerStart(),它将所有定义的Listener加入到map中,同时会调用自定义ServletContextListener的
contextInitialized()方法
9.调用filterStart(),这会创建ApplicationFilterConfig
10.调用loadOnStartup(),如果有servlet需要启动就运行的话,就会调用StandardWrapper#load(),它会用WebappClassLoader
去装载指定的Servlet,当装载完后就执行它的init()方法
这些过后deployDescriptors()方法终于就执行完了
再来看看deployWARs(),它会遍历指定目录下的所有war,然后将这个war包给解压,解压完了之后的执行过程和deployDescriptors()几乎差不多了,这里就省略了。
最后看看deployDirectories(),它遍历指定目录下的所有目录,就是那些非描述应用,非war的应用,比如DOC,ROOT这样的应用,我们平常部署一个应用也是属于这种应用,它的部署过程也是和deployDescriptors()差不多的
这样三个部署就执行完了,现在看看三种部署在启动的时候有什么区别
启动Tomcat的时候可以看到目录,描述文件,WAR部署的区别:
2011-8-30 18:23:09 org.apache.catalina.startup.HostConfig deployDescriptor
信息: Deploying configuration descriptor manager.xml
2011-8-30 18:23:09 org.apache.catalina.startup.HostConfig deployDescriptor
信息: Deploying configuration descriptor test.xml
2011-8-30 18:23:09 org.apache.catalina.startup.HostConfig deployWAR
信息: Deploying web application archive struts2-blank.war
2011-8-30 18:23:10 com.opensymphony.xwork2.util.logging.jdk.JdkLogger info
信息: Parsing configuration file [struts-default.xml]
2011-8-30 18:23:11 com.opensymphony.xwork2.util.logging.jdk.JdkLogger info
信息: Unable to locate configuration files of the name struts-plugin.xml, skippi
ng
2011-8-30 18:23:11 com.opensymphony.xwork2.util.logging.jdk.JdkLogger info
信息: Parsing configuration file [struts-plugin.xml]
2011-8-30 18:23:11 com.opensymphony.xwork2.util.logging.jdk.JdkLogger info
信息: Parsing configuration file [struts.xml]
2011-8-30 18:23:11 org.apache.catalina.startup.HostConfig deployDirectory
信息: Deploying web application directory docs
2011-8-30 18:23:11 org.apache.catalina.startup.HostConfig deployDirectory
信息: Deploying web application directory examples
2011-8-30 18:23:11 org.apache.catalina.startup.HostConfig deployDirectory
信息: Deploying web application directory ROOT
启动过程的前两部分介绍完了,第三部分是最简单的启动线程池和连接器
下面是启动线程池和连接器的时序图:
调用过程从StandardService开始,之前已经启动过了容器,下面就是线程池,因为线程池可能有多个,所以是循环启动,先是调用StandardThreadExecutor#start(),这是默认的线程池实现,它分别创建了TaskQueue和ThreadPoolExecutor,在创建ThreadPoolExecutor 的时候用TaskQueue作为参数,TaskQueue继承了LinkedBlockingQueue,所以Tomcat的线程池实际上使用的是JDK的线程池。线程池是如何跟连接器管理的呢?JioEndpoint有这么一段:
/**
* External Executor based thread pool.
*/
protected Executor executor = null;
public void setExecutor( Executor executor) { this.executor = executor; }
public Executor getExecutor() { return executor; }
所以应该通过配置文件创建连接器的时候设置上的,这一点就不用我们关心了。
假设我们配置了BIO,NIO,AJP三种连接器,他们的启动过程很类似,都是由StandardService调用Connector#start(),由Connector负责启动一个具体的连接器,
1.如果是BIO就调用Http11Protocol#start(),再由它调用JIoEndpoint#start(),由它创建并启动接收线程
2.如果是NIO就调用Http11NioProtocol#start()。,再由它调用NioEndpoint#start(),并创建启动Poller和接收线程
3.如果是AJP就调用JkCoyoteHandler#start(),再调用JkMain#start(),JkMain会分别调用HandlerRequest和ChannelSocket的
init(),ChannelSocket#init()里会创建ServerSocket并调用accept(),同时创建ThreadPool。
经过漫长的等待,Tomcat就启动完成了,启动的时候会注册一大堆MBean,注册MBean使用了apache的commons-modeler这个工具,解析xml使用的是digester这个工具。从启动过程来看连接器和线程池启动都不复杂,最复杂的就是容器,其中部署又是容器中最复杂的。