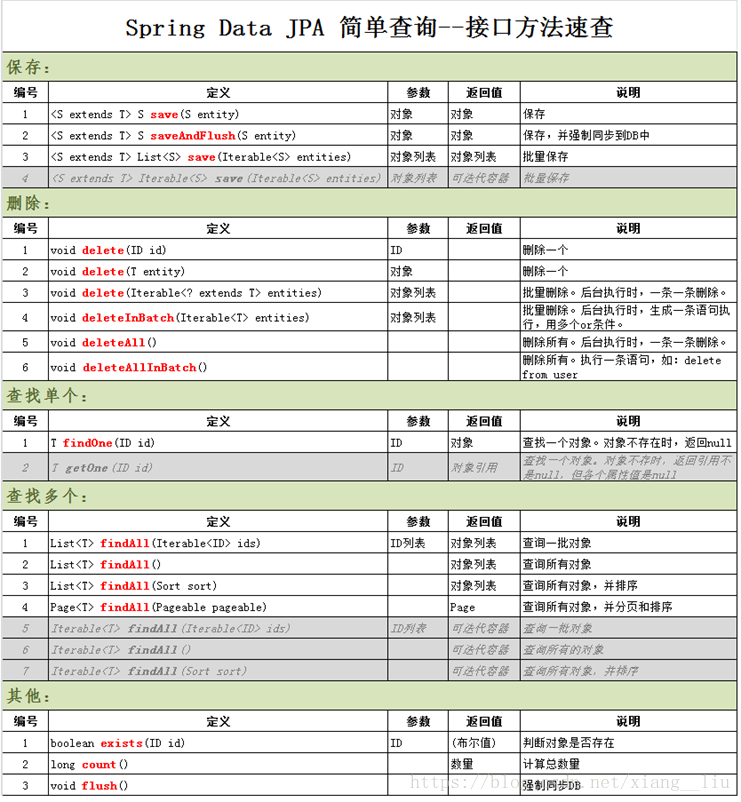
1.1 简单查询--接口方法
1.2 五个接口详解
1.2.1 CrudRepository接口
其中T是要操作的实体类,ID是实体类主键的类型。该接口提供了11个常用操作方法。
@NoRepositoryBean
publicinterface CrudRepository<T, ID extendsSerializable> extends Repository<T, ID> {
<S extends T> S save(S entity);//保存
<S extends T> Iterable<S> save(Iterable<S> entities);//批量保存
T findOne(ID id);//根据id 查询一个对象。返回对象本身,当对象不存在时,返回null
Iterable<T> findAll();//查询所有的对象
Iterable<T> findAll(Iterable<ID> ids);//根据id列表查询所有的对象
boolean exists(ID id);//根据id 判断对象是否存在
long count();//计算对象的总个数
void delete(ID id);//根据id 删除
void delete(T entity);//删除一个对象
void delete(Iterable<? extendsT> entities);//批量删除,集合对象(后台执行时,一条一条删除)
void deleteAll();//删除所有(后台执行时,一条一条删除)
}
1.2.2 PagingAndSortingRepository接口
该接口继承了CrudRepository接口,提供了两个方法,实现了分页和排序的功能了。
@NoRepositoryBean
publicinterface PagingAndSortingRepository<T, ID extends Serializable> extendsCrudRepository<T, ID> {
Iterable<T> findAll(Sort sort);// 仅排序
Page<T>findAll(Pageable pageable);// 分页和排序
}
1.2.3 JpaRepository接口
该接口继承了PagingAndSortingRepository接口。
同时也继承QueryByExampleExecutor接口,这是个用“实例”进行查询的接口,后续再写文章详细说明。
@NoRepositoryBean
publicinterface JpaRepository<T, ID extendsSerializable>
extends PagingAndSortingRepository<T, ID>,QueryByExampleExecutor<T> {
List<T>findAll(); //查询所有对象,返回List
List<T>findAll(Sort sort); //查询所有对象,并排序,返回List
List<T>findAll(Iterable<ID> ids); //根据id列表查询所有的对象,返回List
void flush(); //强制缓存与数据库同步
<S extends T> List<S> save(Iterable<S> entities); //批量保存,并返回对象List
<S extends T> S saveAndFlush(S entity);//保存并强制同步数据库
void deleteInBatch(Iterable<T> entities);//批量删除集合对象(后台执行时,生成一条语句执行,用多个or条件)
void deleteAllInBatch();//删除所有(执行一条语句,如:delete from user)
T getOne(ID id); //根据id 查询一个对象,返回对象的引用(区别于findOne)。当对象不存时,返回引用不是null,但各个属性值是null
@Override
<S extends T> List<S> findAll(Example<S> example); //根据实例查询
@Override
<S extends T> List<S> findAll(Example<S> example, Sort sort);//根据实例查询,并排序。
}
几点说明:
(1)几个查询、及批量保存方法,和 CrudRepository 接口相比,返回的是 List,使用起来更方便。
(2)增加了InBatch 删除,实际执行时,后台生成一条sql语句,效率更高些。相比较而言,CrudRepository 接口的删除方法,都是一条一条删除的,即便是 deleteAll 也是一条一条删除的。
(3)增加了 getOne()方法,切记,该方法返回的是对象引用,当查询的对象不存在时,它的值不是Null。
1.2.4 JpaSpecificationExecutor接口
该接口提供了对JPA Criteria查询(动态查询)的支持。这个接口很有用,具体不粘源码了。
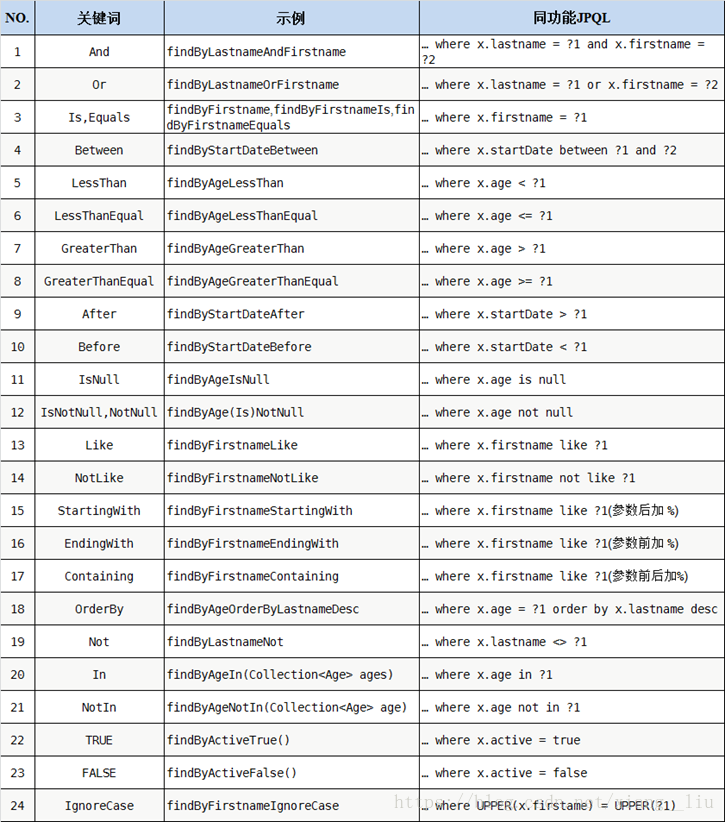
1.3 方法定义规则
符号 |
含义 |
And |
并且 |
Or |
或 |
Is,Equals |
等于 |
Between |
两者之间 |
LessThan |
小于 |
LessThanEqual |
小于等于 |
GreaterThan |
大于 |
GreaterThanEqual |
大于等于 |
After |
之后(时间)> |
Before |
之前(时间)< |
IsNull |
等于Null |
IsNotNull,NotNull |
不等于Null |
Like |
模糊查询。查询件中需要自己加% |
NotLike |
不在模糊范围内。查询件中需要自己加% |
StartingWith |
以某开头 |
EndingWith |
以某结束 |
Containing |
包含某 |
OrderBy |
排序 |
Not |
不等于 |
In |
某范围内 |
NotIn |
某范围外 |
TRUE |
真 |
FALSE |
假 |
IgnoreCase |
忽略大小写 |
1.4 解析方法名--规则说明
1.4.1 规则描述
按照Spring data定义的规则,查询方法以find|read|get开头(比如 find、findBy、read、readBy、get、getBy),涉及条件查询时,条件的属性用条件关键字连接,要注意的是:条件属性首字母需大写。框架在进行方法名解析时,会先把方法名多余的前缀截取掉,然后对剩下部分进行解析。
如果方法的最后一个参数是 Sort 或者 Pageable 类型,也会提取相关的信息,以便按规则进行排序或者分页查询。
1.4.2 举例说明
比如 findByUserAddressZip()。框架在解析该方法时,首先剔除findBy,然后对剩下的属性进行解析,详细规则如下(此处假设该方法针对的域对象为AccountInfo类型):
1. 先判断userAddressZip (根据 POJO 规范,首字母变为小写,下同)是否为AccountInfo 的一个属性,如果是,则表示根据该属性进行查询;如果没有该属性,继续第二步;
2. 从右往左截取第一个大写字母开头的字符串(此处为 Zip),然后检查剩下的字符串是否为AccountInfo的一个属性,如果是,则表示根据该属性进行查询;如果没有该属性,则重复第二步,继续从右往左截取;最后假设user 为AccountInfo 的一个属性;
3. 接着处理剩下部分(AddressZip ),先判断 user 所对应的类型是否有addressZip 属性,如果有,则表示该方法最终是根据 " AccountInfo.user.addressZip" 的取值进行查询;否则继续按照步骤 2 的规则从右往左截取,最终表示根据 " AccountInfo.user.address.zip" 的值进行查询。
可能会存在一种特殊情况,比如 AccountInfo包含一个 user 的属性,也有一个 userAddress 属性,此时会存在混淆。读者可以明确在属性之间加上 "_" 以显式表达意图,比如 "findByUser_AddressZip()" 或者"findByUserAddress_Zip()"。(强烈建议:无论是否存在混淆,都要在不同类层级之间加上"_" ,增加代码可读性)
1.4.3 一些情况
1. 当查询条件为null时
举例说明如下:
实体定义:对于一个客户实体Cus,包含有name和sex,均是String类型。
查询方法定义:List<Cus>findByNameAndSex(String name,String sex);
使用时:dao.findByNameAndSex(null,"男");
后台生成sql片断:where(cus0_.name is null) and cus0_.sex=?
结论:当查询时传值是null时,数据库中只有该字段是null的记录才符合条件,并不是说忽略这个条件。也就是说,这种查询方式,只适合于明确查询条件必须传的业务,对于动态查询(条件多少是动态的,例如一般的查询列表,由最终用户使用时决定输入那些查询条件),这种简单查询是不能满足要求的。
2. 排序
List<Cus>findBySexOrderByName(String sex); //名称正序(正序时,推荐此方式,简单)
List<Cus>findBySexOrderByNameAsc(String sex); //名称正序(效果同上)
List<Cus>findBySexOrderByNameDesc(String sex); //名称倒序
3. 结果限制
/**
* 根据父ID,得到排序号最大的bo。
* 用于预计算新资源的排序号。
*/
Resource findFirstByFather_idOrderByOrderNumDesc(Long fatherId);
User findFirstByOrderByLastnameAsc();
User findTopByOrderByAgeDesc();
Page<User> queryFirst10ByLastname(String lastname,Pageable pageable);
Slice<User> findTop3ByLastname(String lastname,Pageable pageable);
List<User> findFirst10ByLastname(String lastname,Sort sort);
List<User> findTop10ByLastname(String lastname,Pageable pageable);
4. 计数
Long countByLastname(String lastname);
5. 删除
voiddeleteByProject_Id(Long id);
voiddeleteByProject_Cus_id(Long id);
http://www.cnblogs.com/rulian/p/6434631.html