我单位的小姐姐 也满逗的 每次测试微信公众号 总会报错。如下图:
java.sql.SQLException: Incorrect string value: ‘\xF0\x9F\x91\xA7’ for colum n ‘nickname’ at row 1
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:1073)
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:3593)
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:3525)
at com.mysql.jdbc.MysqlIO.sendCommand(MysqlIO.java:1986)
at com.mysql.jdbc.MysqlIO.sqlQueryDirect(MysqlIO.java:2140)
at com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:2620)
at com.mysql.jdbc.StatementImpl.executeUpdate(StatementImpl.java:1662)
at com.mysql.jdbc.StatementImpl.executeUpdate(StatementImpl.java:1581)
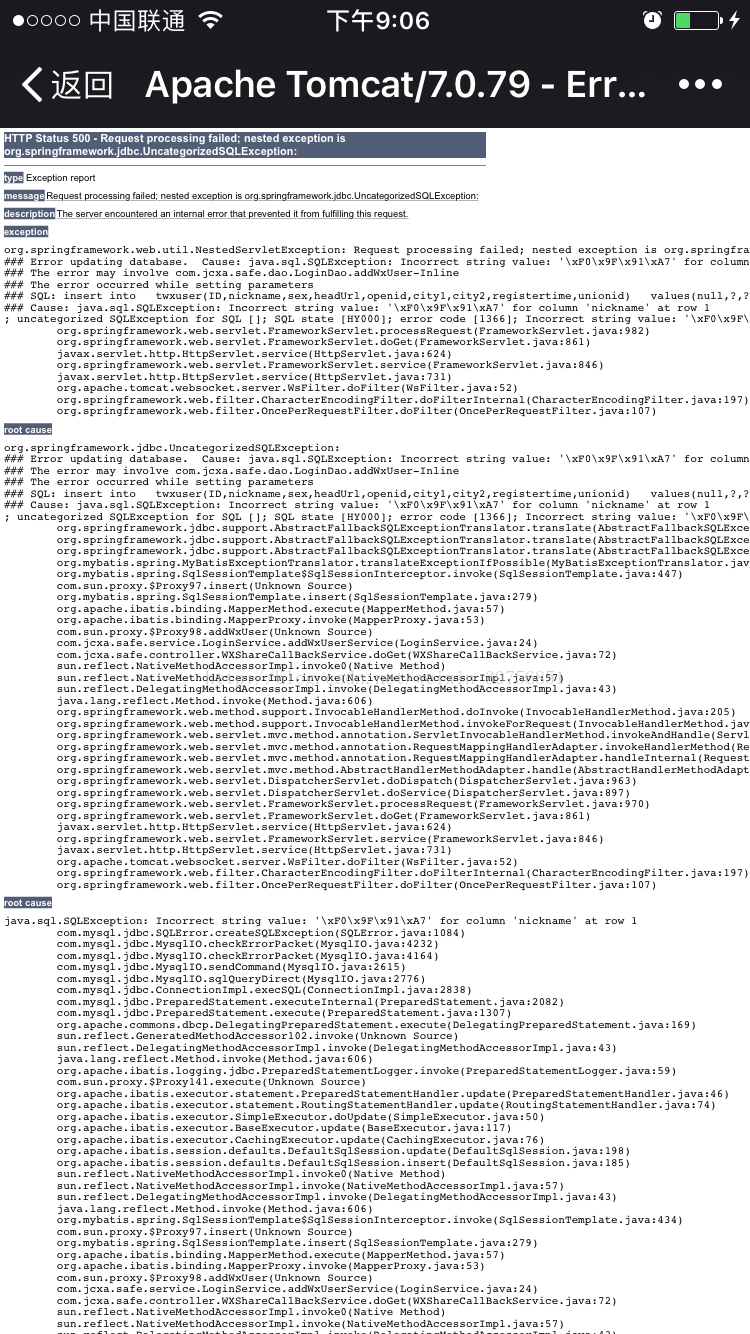
这个就很尴尬 所有人都可以正常登陆 唯独她不可以 慢慢排查发现是因为昵称中带有emoji 图片 额 好吧 来解决
经过百度 试了各种办法 只有这个挺可靠
mysql表字段定义为utf8mb4
`third_name` varchar(255) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '用户第三方账号昵称',
注意改成了“utf8mb4”,不再是utf8,主要是支持的字节数不同。
但是我试过发现也不OK 所以索性就写了一个工具类 用来过滤名字
package com.utils;
import org.apache.commons.lang.StringUtils;
/**过滤emoji工具*/
public class NickNameFilter {
/**检测是否有emoji字符
* 有的话抛出
* */
public static boolean containsEmoji(String source) {
if (StringUtils.isBlank(source)) {
return false;
}
int len = source.length();
for (int i = 0; i < len; i++) {
char codePoint = source.charAt(i);
if (isEmojiCharacter(codePoint)) {
//do nothing,判断到了这里表明,确认有表情字符
return true;
}
}
return false;
}
private static boolean isEmojiCharacter(char codePoint) {
return (codePoint == 0x0) ||
(codePoint == 0x9) ||
(codePoint == 0xA) ||
(codePoint == 0xD) ||
((codePoint >= 0x20) && (codePoint <= 0xD7FF)) ||
((codePoint >= 0xE000) && (codePoint <= 0xFFFD)) ||
((codePoint >= 0x10000) && (codePoint <= 0x10FFFF));
}
/**
* 过滤emoji 或者 其他非文字类型的字符
*
* @param source
* @return
*/
public static String filterEmoji(String source) {
source = source.replaceAll("[\\ud800\\udc00-\\udbff\\udfff\\ud800-\\udfff]", "*");
if (!containsEmoji(source)) {
return source;//如果不包含,直接返回
}
//到这里铁定包含
StringBuilder buf = null;
int len = source.length();
for (int i = 0; i < len; i++) {
char codePoint = source.charAt(i);
if (isEmojiCharacter(codePoint)) {
if (buf == null) {
buf = new StringBuilder(source.length());
}
buf.append(codePoint);
} else {
buf.append("*");
}
}
if (buf == null) {
return source;//如果没有找到 emoji表情,则返回源字符串
} else {
if (buf.length() == len) {//这里的意义在于尽可能少的toString,因为会重新生成字符串
buf = null;
return source;
} else {
return buf.toString();
}
}
}
}
就可以了