train loss与test loss结果分析
train loss 不断下降,test loss不断下降,说明网络仍在学习;
train loss 不断下降,test loss趋于不变,说明网络过拟合;
train loss 趋于不变,test loss不断下降,说明数据集100%有问题;
train loss 趋于不变,test loss趋于不变,说明学习遇到瓶颈,需要减小学习率或批量数目;
train loss 不断上升,test loss不断上升,说明网络结构设计不当,训练超参数设置不当,数据集经过清洗等问题。
实例
这段在使用caffe的时候遇到了两个问题都是在训练的过程中loss基本保持常数值,特此记录一下。
1.loss等于87.33不变
loss等于87.33这个问题是在对Inception-V3网络不管是fine-tuning还是train的时候遇到的,无论网络迭代多少次,网络的loss一直保持恒定。
查阅相关资料以后发现是由于loss的最大值由FLT_MIN计算得到,FLT_MIN是1.17549435e−38F1.17549435e−38F其对应的自然对数正好是-87.3356,这也就对应上了loss保持87.3356了。
这说明softmax在计算的过程中得到了概率值出现了零,由于softmax是用指数函数计算的,指数函数的值都是大于0的,所以应该是计算过程中出现了float溢出的异常,也就是出现了inf,nan等异常值导致softmax输出为0.
当softmax之前的feature值过大时,由于softmax先求指数,会超出float的数据范围,成为inf。inf与其他任何数值的和都是inf,softmax在做除法时任何正常范围的数值除以inf都会变成0.然后求loss就出现了87.3356的情况。
解决办法
由于softmax输入的feature由两部分计算得到:一部分是输入数据,另一部分是各层的权值等组成
减小初始化权重,以使得softmax的输入feature处于一个比较小的范围
降低学习率,这样可以减小权重的波动范围
如果有BN(batch normalization)层,finetune时最好不要冻结BN的参数,否则数据分布不一致时很容易使输出值变得很大(注意将batch_norm_param中的use_global_stats设置为false )。
观察数据中是否有异常样本或异常label导致数据读取异常
本文遇到的情况采用降低学习率的方法,learning rate设置为0.01或者原来loss的1/5或者1/10。
2.loss保持0.69左右
采用VGG-16在做一个二分类问题,所以计算loss时等价与下面的公式:
loss=−log(Pk==label)loss=−log(Pk==label)
当p=0.5时,loss正好为0.693147,也就是训练过程中,无论如何调节网络都不收敛。最初的网络配置文件卷积层的参数如下所示:
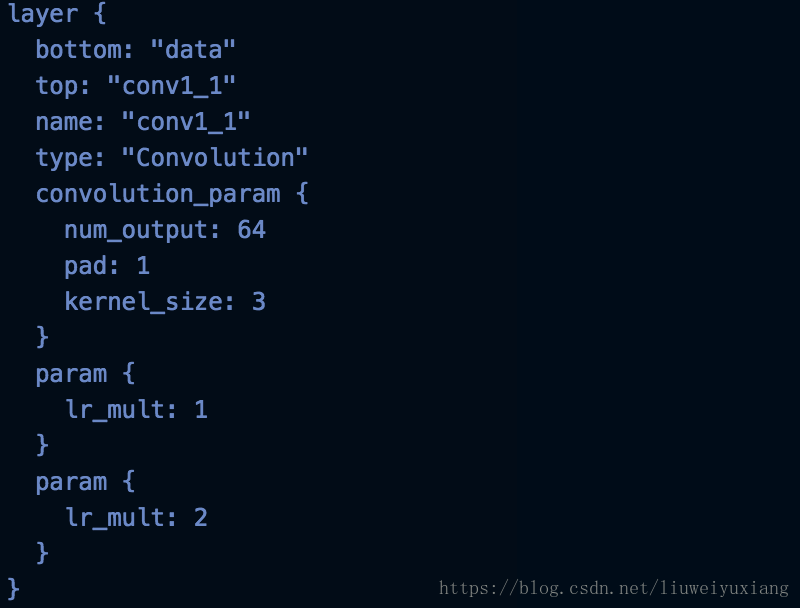
从VGG-16训练好的模型进行fine-tuning也不发生改变,当在网络中加入初始化参数和decay_mult以后再次训练网络开始收敛。

但是具体是什么原因造成的,暂时还没有找到,难道是初始化参数的问题还是?
总结
loss一直不下降的原因有很多,可以从头到尾滤一遍: 1)数据的输入是否正常,data和label是否一致。 2)网络架构的选择,一般是越深越好,也分数据集。 并且用不用在大数据集上pre-train的参数也很重要的 3)loss 公式对不对。
相关博客推荐
Loss和神经网络训练介绍的比较完整,有1.梯度检验2.训练前检查,3.训练中监控4.首层可视化5.模型融合和优化等等等
Facenet即triplet network模型训练,loss不收敛的问题?
原文链接:训练loss不下降原因集合