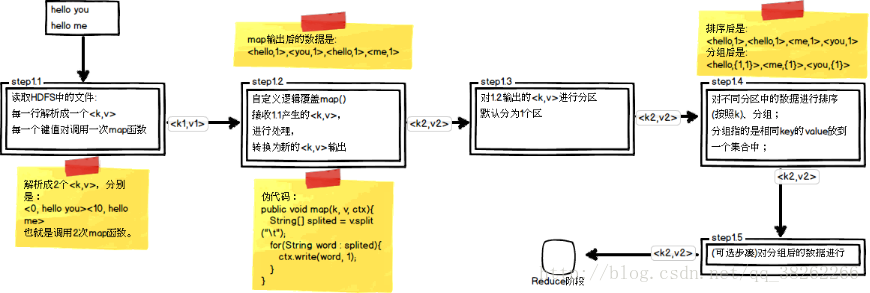
Step1.4第四步中需要对不同分区中的数据进行排序和分组,默认情况按照key进行排序和分组二次排序
在map阶段
1.使用job.setInputFormatClass定义的InputFormat将输入的数据集分割成小数据块
调用自定义Map的map方法,将一个个<LongWritable, Text>对输入给Map的map方法。
输出应该符合自定义Map中定义的输出<IntPair, IntWritable>。
最终生成一个List<IntPair, IntWritable>。
2.在map阶段的最后,会先调用job.setPartitionerClass对这个List进行分区,每个分区映射到一个reducer,
每个分区内又调用job.setSortComparatorClass设置的key比较函数类排序,是一个二次排序。
如果没有通过job.setSortComparatorClass设置key比较函数类,则使用key的实现的compareTo方法。
使用IntPair实现的compareTo方法。
在reduce阶段
1.reducer接收到所有映射到这个reducer的map输出后,也是会调用job.setSortComparatorClass
设置的key比较函数类对所有数据对排序
2.然后开始构造一个key对应的value迭代器,使用job.setGroupingComparatorClass设置的分组函数类
只要这个比较器比较的两个key相同,他们就属于同一个组,它们的value放在一个value迭代器
3.最后进入Reducer的reduce方法,reduce方法的输入是所有的(key和它的value迭代器)实现目标:
任务:
数据文件中,如果按照第一列升序排列,
当第一列相同时,第二列升序排列
如果当第一列相同时,求出第二列的最小值
1、p.dat文件内容:
xm@master:~$ hadoop fs -text /a/p.dat
2 2
1 2
3 3
3 2
3 1
1 3
1 1
2 3
2 1
2、输出结果:
1 1
1 2
1 3
2 1
2 2
2 3
3 1
3 2
3 3
任务分析:封装一个自定义类型作为key的新类型:将第一列与第二列都作为key
任务实现方法:
WritableComparable接口
定义:
public interface WritableComparable<T> extends Writable, Comparable<T> {}
自定义类型MyNewKey实现了WritableComparable的接口,
该接口中有一个compareTo()方法,当对key进行比较时会调用该方法,
而我们将其改为了我们自己定义的比较规则,从而实现我们想要的效果。实现代码:
//MyNewKey.java:
package mr;
import java.io .DataInput;
import java.io .DataOutput;
import java.io .IOException;
import org.apache.hadoop.io .WritableComparable;
public class MyNewKey implements WritableComparable <MyNewKey>{
Long fistname;
Long secondname;
public MyNewKey() {
}
public MyNewKey(Long fist, Long second) {
fistname = fist;
secondname = second;
}
public Long getFistname() {
return fistname;
}
public Long getSecondname() {
return secondname;
}
//反序列化,从流中的二进制转换成IntPair
@Override
public void readFields(DataInput in) throws IOException {
// TODO Auto-generated method stub
fistname = in.readLong();
secondname = in.readLong();
}
//序列化,将IntPair转化成使用流传送的二进制
@Override
public void write(DataOutput out) throws IOException {
// TODO Auto-generated method stub
out.writeLong(fistname);
out.writeLong(secondname);
}
@Override
public int compareTo(MyNewKey another) {
// TODO Auto-generated method stub
long min = fistname - another.fistname;
if(min !=0 ) {
return (int)min;
} else {
return (int)(secondname - another.secondname);
}
}
}
//MyText.java:
package mr;
import java.io .IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io .LongWritable;
import org.apache.hadoop.io .NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MyTest2 {
static String INPUT_PATH = "hdfs://master:9000/a/p.dat";
static String OUTPUT_PATH = "hdfs://master:9000/output";
static class MyMapper extends Mapper<Object, Object, MyNewKey, NullWritable>{
NullWritable out_value = NullWritable.get();
protected void map(Object key, Object value, Context context)
throws IOException, InterruptedException {
String[] arr = value.toString().split(" ", 2);
MyNewKey newkey = new MyNewKey(Long.parseLong(arr[0]), Long.parseLong(arr[1]));
context.write(newkey, out_value);
}
}
static class MyReduce extends Reducer<MyNewKey, NullWritable, LongWritable, LongWritable> {
LongWritable tokenkey = new LongWritable();
LongWritable tokenvalue = new LongWritable();
protected void reduce(MyNewKey key, Iterable<NullWritable> values, Context context)
throws java.io .IOException, java.lang.InterruptedException {
tokenkey.set(key.getFistname());
tokenvalue.set(key.getSecondname());
context.write(tokenkey, tokenvalue);
}
}
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
System.setProperty("hadoop.home.dir", "E:/Eclipse/eclipse/hadoop2.6_Win_x64-master");
Path outputpath = new Path(OUTPUT_PATH);
Configuration conf = new Configuration();
FileSystem fs = outputpath.getFileSystem(conf);
if(fs.exists(outputpath)){
fs.delete(outputpath,true);
}
conf.set("fs.default.name ", "hdfs://master:9000/");
Job job = Job.getInstance(conf);
FileInputFormat.setInputPaths(job, INPUT_PATH);
FileOutputFormat.setOutputPath(job, outputpath);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReduce.class);
job.setMapOutputKeyClass(MyNewKey.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(LongWritable.class);
job.waitForCompletion(true);
}
}
实现目标:
任务:
求出第一列相同时第二列的最小值
1、p.dat文件内容:
xm@master:~$ hadoop fs -text /a/p.dat
2 2
1 2
3 3
3 2
3 1
1 3
1 1
2 3
2 1
2、输出结果:
1 1
2 1
3 1
任务实现流程分析:
自定义分组:
为了针对新的key类型作分组,我们也需要自定义一下分组规则:
private static class MyGroupingComparator implements RawComparator<MyNewKey> {
/*
* 基本分组规则:按第一列firstNum进行分组
*/
@Override
public int compare(MyNewKey key1, MyNewKey key2) {
return (int) (key1.firstNum - key2.firstNum);
}
/*
* @param b1 表示第一个参与比较的字节数组
*
* @param s1 表示第一个参与比较的字节数组的起始位置
*
* @param l1 表示第一个参与比较的字节数组的偏移量
*
* @param b2 表示第二个参与比较的字节数组
*
* @param s2 表示第二个参与比较的字节数组的起始位置
*
* @param l2 表示第二个参与比较的字节数组的偏移量
*/
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
return WritableComparator.compareBytes(b1, s1, 8, b2, s2, 8);
}
}
1.MyGroupingComparator实现这两个接口
RawComparator中的compare()方法是基于字节的比较
Comparator中的compare()方法是基于对象的比较
由于在MyNewKey中有两个long类型,每个long类型又占8个字节。
这里因为比较的是第一列数字,所以读取的偏移量为8字节。
2.添加对分组规则的设置:
// 设置自定义分组规则
job.setGroupingComparatorClass(MyGroupingComparator.class);
任务实现:
与上面排序不同的是,我们又写了一个类MyGroupingComparator实现接口方法,然后job中设置自定义分组规则即可。//MyGroupingComparator.java:
package sort;
import org.apache.hadoop.io.RawComparator;
import org.apache.hadoop.io.WritableComparator;
public class MyGroupingComparator implements RawComparator<MyNewKey>{
//一个字节一个字节的比,直到找到一个不相同的字节,然后比这个字节的大小作为两个字节流的大小比较结果。
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
// TODO Auto-generated method stub
return WritableComparator.compareBytes(b1, s1, 8, b2, s2, 8);
}
//只要first相同就属于同一个组
@Override
public int compare(MyNewKey key1, MyNewKey key2) {
// TODO Auto-generated method stub
return (int) (key1.getFistname() - key2.getFistname());
}
}
job设置自定义分组规则:
job.setGroupingComparatorClass(MyGroupingComparator.class);
一般方法:
package sort;
import java.io .IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io .LongWritable;
import org.apache.hadoop.io .NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Text_simple {
static String INPUT_PATH = "hdfs://master:9000/a/p.dat";
static String OUTPUT_PATH = "hdfs://master:9000/output";
static class MyMapper extends Mapper<Object, Object, IntWritable, IntWritable>{
IntWritable out_key = new IntWritable();
IntWritable out_value = new IntWritable();
protected void map(Object key, Object value, Context context)throws IOException, InterruptedException {
String[] arr = value.toString().split(" ", 2);
int a = Integer.parseInt(arr[0]);
int b = Integer.parseInt(arr[1]);
context.write(new IntWritable(a),new IntWritable(b));
}
}
static class MyReduce extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable> {
IntWritable tokenkey = new IntWritable();
IntWritable tokenvalue = new IntWritable();
int a = Integer.MAX_VALUE;
protected void reduce(IntWritable key, Iterable<IntWritable> values, Context context)throws IOException, java.lang.InterruptedException {
for(IntWritable c:values){
if(c.get()<a){
a = c.get();
}
}
context.write(key, new IntWritable(a));
}
}
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
System.setProperty("hadoop.home.dir", "E:/Eclipse/eclipse/hadoop2.6_Win_x64-master");
Path outputpath = new Path(OUTPUT_PATH);
Configuration conf = new Configuration();
FileSystem fs = outputpath.getFileSystem(conf);
if(fs.exists(outputpath)){
fs.delete(outputpath,true);
}
conf.set("fs.default.name ", "hdfs://master:9000/");
Job job = Job.getInstance(conf);
FileInputFormat.setInputPaths(job, INPUT_PATH);
FileOutputFormat.setOutputPath(job, outputpath);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReduce.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
job.waitForCompletion(true);
}
}