Synthetic Data for Text Localisation in Natural Images是VGG实验室2016年CVPR的一篇论文。
这篇论文所做的主要贡献有两点:
1.将word人工的嵌入到自然图片中,人工生成带有文本的图片(synthText)。
2.提出一种FRCN的网络来检测文本。
本文主要针对第一点贡献进行详细讲解,是如何人工生成数据。
源代码:here
一.输入与输出
我们知道标签数据的获取是昂贵的,但是对于深度学习模型,大量的标签数据又是必须的。这个时候,人工合成符合自然条件的合理的数据是十分有价值的,因此本文的出发点就是因为这个。
1.输入(一张原始的自然图片):
通过Google Image Search获得

2.输出(带有文本的图片,并且知道其文本的具体位置(因为是自己人工生成的)):
其中文本和图片本身并没有任何关系,文本内容,通过20Newsgroups获得

二.语义(seg)与深度(depth)信息的获取
在原文中,首先需要对原始图片进行特征提取,提取其语义和深度信息。
提取脚本代码:here
1.语义信息
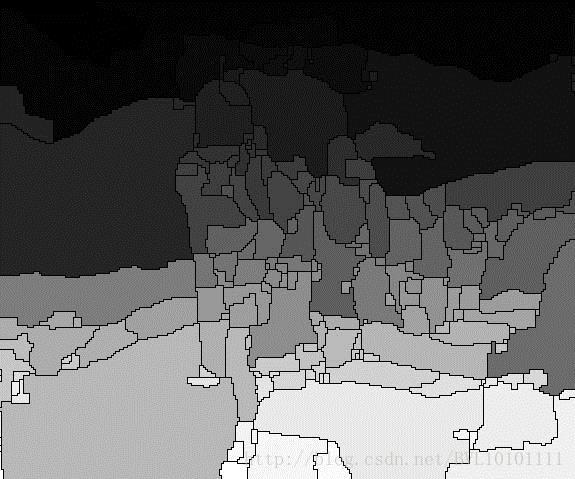
原文采用的方法是:gPb-UCM 来得到图片的语义信息,当然其他先进有效的方法均可。灰度图,仅1个channel。
2.深度信息

可以简单看成是图片里的物体距离相机的远近。灰度图,仅1一个channel
原文采用的是 CVPR 2015 的Deep convolutional neural fields for depth estimation from a single image 来提取深度信息。
此外原作者还推荐此方法来提取深度信息depth-from-single image ConvNets
三.候选region的选取
获得seg和depth后,需要根据seg和depth对seg中的每个区域进行过滤,选取合适的区域作为放word的候选区域
具体过程如下:
1.根据seg进行筛选
1)对图片的每个seg进行遍历,利用opencv的minAreaRect求得包住当前seg所有像素点的最小矩形。
2)根据矩形的宽和高,过滤掉宽高过小,面积过小,宽高比过小的矩形区域。
2.根据depth进行筛选
1) 对seg筛选后的区域,进行depth筛选,首先将depth的灰度图(1个channel)转化成xyz(3个channel)形式
2)遍历seg筛选后的所有seg,希望对每个seg拟合出一个较好的平面,具体来讲每次遍历进行3)、4)、5)、6)
3)对每个seg随机选取k个点和其附近的p个点(这p个也需要在当前seg中)(代码中选取100个点,并且每个点选4个附近点,则总共(4+1)*100=500个点)
4)遍历3)中随机选取的k个点,每次得到(p+1)(当前点和附近点),利用ransac算法对(p+1)个点拟合一个3-d平面,计算当前seg中所有点到此平面的距离,并统计算得的距离在一个阈值下的点个数,点数越多,说明当前的平面越能代表此seg。
5)选取在4)中,统计的点数最多top10个平面,对每个平面中所有在距离阈值之下的点进行ransac,拟合得到最后的10个平面,最后选seg中点到这10个平面最多的一个平面作为当前seg的平面。并获得平面的4个参数(a,b,c,d):表示(x,y,z)轴和偏移量
6)删除c过小,即投射角度过小的seg
四.对候选region进行图像变换
我们知道,原图中每个seg,都是以一定角度和方向在图片中成像的。因此为了之后方便将word填到图片的seg中去,需要将每个seg进行旋转变换,具体来说:
1)利用opencv的findContours 来获取每个seg的轮廓
2)将轮廓坐标转成3-d形式。并将坐标旋转,使得当前区域在视线的正前方。
3)将选旋转后的区域平铺到平面上,即只保留x,y维信息。
4)将平铺到平面的区域进行旋转,使得用minAreaRect包围的矩形的角度为0。
5)利用opencv的findHomography 对seg平面变换前后的矩阵,计算变换矩阵——单应矩阵(用来在平面上填写word之后的图片,复原的原图)
五.对变换后的region进行填word
获得变换后的region之后,就需要对region进行填word了,这里可以对每张图片生成不同的合成文本图片,也可以对每张图片多个region生成word,主要借助的是pygame,来进行填word。
具体来讲:
1)确定每张图片生成多少张合成图片,以及每张合成图片有几个合成文本区域
2)对于每次文本合成,随机选取1个region作为填word的region
3)随机选择一种字体font,和字体的弯曲程度利用pygame。
4)根据region的平均宽高,设置font的大小。
5) 随机从20Newsgroup中选择要合成的文本内容
6)利用pygame,创建一个surface,根据要填写的文本得到一个文本矩形,
7)利用render_to 方法,将本文放到surface平面上(先中间,后两边),最后对放上文本的surface平面,截取文本+pad。作为文本区域。
8)利用scipy.signal.fftconvolve,将文本区域和region进行快速傅里叶变换的碰撞检测。要是存在碰撞,则此region不合适,返回。
9)将碰撞检测后的文本区域通过第四节中第5)得到的单应矩阵变换成符合原图的角度
10)对文本区域,利用opencv的GaussianBlur进行高斯模糊处理。
11)为文本选择一种颜色(随机或者根据region对应的背景颜色选择)
12)将涂色好的文本区域放到原图片中,得到输出图片
六.总结
整体上讲,就是通过seg和depth筛选候选region,在随机生成本文字体和颜色,将其放置到对应的region中,并通过矩阵变换得到最后的含有文本的图片。
原作者写的算法,感觉略微拖沓复杂,并且因为大量的矩阵运算,效率并不高。