背景
标题中的几个关键字在许多文章都会看到,但是我们并不知道它们是什么意思,下来一起来学习一下。
哈希表
参考谈谈哈希表,感谢原作者,侵删。
举一个例子:我们在程序里,要用一个数据结构去表示全班40名学生的姓名、学号、电话、家庭住址,可以用个Student对象来表示每个学生,然后以数组的形式组织全部Student,这样组织数据没有问题。当要对这个数据进行频繁移动、增减的时候,我们可以链表的组织形式以提高效率。当需要频繁查询的时候,我们会考虑用哈希表。
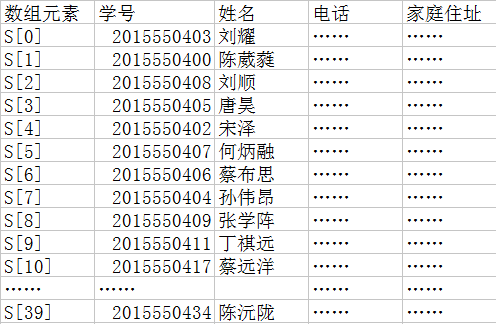
如果以数组形式组织,需要根据学号这个关键字(因为学号是唯一,所以为关键字)来查找记录时,需要一行行遍历整个数组,直到找到相等的学号。当有一个函数,传入关键字就能得到该关键字对应的记录的存储地址,那么这个数据的组织形式就可以成为哈希表,那个函数也成为哈希函数。
哈希函数存在意义
上面说到,要建立关键字与存储地址的关系,我们存的是数组,那么该地址先抽象为数组的下标(因为java不能直接控制存储地址,所以用了数组的下标),即关键字与数组下标的对应关系。
例子中,我们可以将关键字通过一定的数值转化,得到一个数组的下标,如:陈葳蕤(陈葳蕤)第一字的字母为c ASCII码为99,99对10取余为9,则陈葳蕤的记录在哈希表的中的下标为9。这个时候肯定有人说,班里如果有很多姓陈、姓崔的呢?最后会导致一部分记录的下表都为同一个数值。
解决办法是建一个元素为链表的数组,数组大小为哈希函数产生的哈希地址的区间(如我们定义哈希函数产生的下表区间为0~99,那么定义数组大小为100),每个数组元素初始都为空,所有关键字为同义词的记录保存在同一个链表里,但凡是哈希地址为i的记录都插在S[i]这个元素后面。最后会出现以下情况:
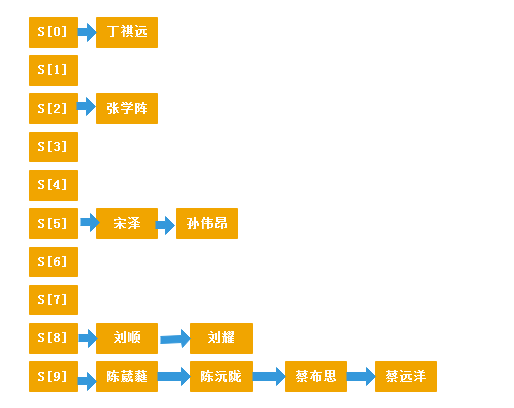
这就像我们去利用字典查找汉字,我们虽然能够利用汉字的首字母或者汉子的笔画去确定该汉字在字典中的页码,但是该页码中还存在其他的汉字,我们需要将查找的汉字和该页码中的汉字进行比较,直到找到我们要查找的汉字。在利用字典查找汉字的过程中,我们虽然仍然要去比较汉字,但相比与在所有页码中去一个个比较查询,这种先确定页码再去比较的方案已经能极大地提高我们查找的效率了。
一些哈希函数的实现方法
直接定址法:这个方法我们在上述例子中有用到过,取关键字的或关键的某一个线性函数值为哈希地址。即:Hash(key)=key或者Hash(key)=a*key+b。这种构造方法下由于地址集合和关键字集合大小一样,所以并不会有冲突的发生。但是这种方法并不常用。
除留余数法:这个方法我们在上述例子中也有用到过,取关键字被某一个不大于哈希表长m的数p除后所余得的数为哈希地址。即Hash(key)=key MOD p,p<=m(m为哈希表长)。这种方法比较简单也很常用。
数字分析法:就是取关键字的若干位数组成哈希地址。当然我们在取的时候要对位数进行分析,尽量减少冲突。
平方取中法:取关键字平方后的中间若干位组成哈希地址。相比于数字分析法优点在于一个数平方之后的中间的几位数和原来的数都有关,因此哈希地址是随机的。
可以看到:在哈希函数构造的时候都是使用的数字,但如果我们的关键字不为数字的时候,我们要先将关键字转化为数字,再用哈希函数得到哈希地址。如上述例子中我们利用学生姓名作为关键字,我们首先要得到学生姓名小写拼音的ASCII码,再用ASCII码作为哈希函数的自变量,从而得到哈希地址。
哈希表处理冲突的方法
之前讲过哈希表的冲突是不可避免的只能减少的,那么如何处理冲突也成了一个不可避免的问题。
什么是处理冲突呢?:由关键字得到的哈希地址上已经有记录存在了,那么“处理冲突”就是要为该关键字的记录找到一个“没有记录存在”的哈希地址。在处理冲突的过程中可能得到一个地址序列Hi(i=1,2,3,4,5,……)。我们在处理哈希冲突的时候可能得到的另一个哈希地址H1也是有记录的,我们要求下一个地址H2,如果H2依然冲突,则找H3,依次类推,直至Hi上没有记录为止。
(1)开放地址法:Hi=(Hash(key)+di)MOD m
其中:Hash(key)为哈希函数,di为增量序列,m为哈希表长。
1、di=1,2,3,4,5……,m-1时称线性探测再散列;
2、di=12,-12,22,-22……….,+k2,-k2(k<=m/2)称之为二次探测再散列。
3、di=伪随机数序列,称之为随机探测在散列。
(2)再哈希法:Hi=RHashi(key) i=0,1,2,3,4….,k. RHashi均是不同的哈希函数,就是说在同义词产生地址冲突的时候用另一个哈希函数去求得另一个哈希地址,一直到不再有冲突
(3)链地址法:链地址法我们在上述例子有用到过。
(4)建立公共溢出区:设哈希函数产生的哈希地址集为[0,m-1],则分配两个表:
一个基本表ElemType base_tbl[m];每个单元只能存放一个元素;
一个溢出表ElemType over_tbl[k];只要关键码对应的哈希地址在基本表上产生冲突,则所有这样的元素一律存入该表中。查找时,对给定值kx 通过哈希函数计算出哈希地址i,先与基本表的base_tbl[i]单元比较,若相等,查找成功;否则,再到溢出表中进行查找。
哈希表的查找
1、理想情况下我们根据关键字key,通过造表时候的哈希函数求得哈希地址,该表此位置上的记录的关键字与我们给定的关键字key相等,则查找成功。
2、但是如果有冲突,即该表此位置上的记录不是我们要查找的记录,则根据造表时候设定的冲突处理方法寻找“下一个地址”,一直到哈希表的某一个位置为“空”或者表中记录的关键字为我们给定的关键字key。
hashCode
hashCode是jdk根据对象的地址或者字符串或者数字算出来的int类型的数值,在 Java 应用程序执行期间,在对同一对象多次调用 hashCode 方法时,必须一致地返回相同的整数。对象的hashCode()方法定义不一定靠谱,也就是说两个对象相等,调用hashCode()返回的数值不一定相等;两个对象的hashCode()的数值相等,但两个对象用equals方法不一定相等。
HashMap的实现原理
- 利用key的hashCode重新hash计算出当前对象的元素在数组中的下标
- 存储时,如果出现hash值相同的key,此时有两种情况。(1)如果key相同,则覆盖原始值;(2)如果key不同(出现冲突),则将当前的key-value放入链表中
- 获取时,直接找到hash值对应的下标,在进一步判断key是否相同,从而找到对应值。
- 理解了以上过程就不难明白HashMap是如何解决hash冲突的问题,核心就是使用了数组的存储方式,然后将冲突的key的对象放入链表中,一旦发现冲突就在链表中做进一步的对比。
这个还是专门写篇文章来说说。