最近在学python,研究了下,写了两个爬虫成功爬取了一些东西。有一个很黄很暴力,就不放出来了,还有一个比较绿色,简单,适合初学者学习,思路也比较清晰,也方便我以后再捡起来,注释写的很清楚,特把源码放到博客。有需要的朋友也可以学习下,探讨一下
# -*-coding:utf-8-*-
import requests
import os
from lxml import html
import xlwt
import sys
reload(sys)
sys.setdefaultencoding('utf8')
def get_url_content():
Allresponse=''
#因为网页不多,所以可以考虑吧10页的数据拼成一个content
#range(0,250,25)意思是从0开始,到250结束,每轮i+25
for i in range(0,250,25):
response =requests.get("https://movie.douban.com/top250?start="+bytes(i)+"&filter=",verify=False).content
Allresponse=Allresponse+response
dataList=[]
dataList= builder_divide(Allresponse)
return dataList
def builder_divide(content):
dataList=[]
#lxml把网页先解析到分析器中
selector=html.fromstring(content)
#先按li/div模块,把他截成250个div
for j in selector.xpath("//ol[@class='grid_view']/li/div[@class='item']"):
count=''
count =j.xpath("div[@class='pic']//em/text()")[0]
title=''
title=j.xpath("div[@class='info']//span[@class='title'][1]/text()")[0]
kindof=''
kindof=j.xpath("div[@class='info']//div[@class='bd']//p[@class][1]/text()")[0].strip()
score=''
score=j.xpath("div[@class='info']//div[@class='bd']//span[@class='rating_num']/text()")[0]
evaluate=''
evaluate=j.xpath("div[@class='info']//div[@class='star']/span[last()]/text()")[0]
detail=''
#其实应该对每一个j.xpath进行判断,因为有可能标签为空,[0]就报错了
#但是这里我是已经发现了只有inq有一个缺的,所以其他的没有做空值判断
if(len(j.xpath("div[@class='info']//span[@class='inq']/text()"))>0):
detail=j.xpath("div[@class='info']//span[@class='inq']/text()")[0]
#每一次循环,把需要的数据获取到以后,放到mix元组里面
mix=(count,title,kindof,score,evaluate,detail)
#每轮循环以后,把mix添加到数组里,后面可以用dataList[轮数][元组下标]取出对应的值
dataList.append(mix)
return dataList
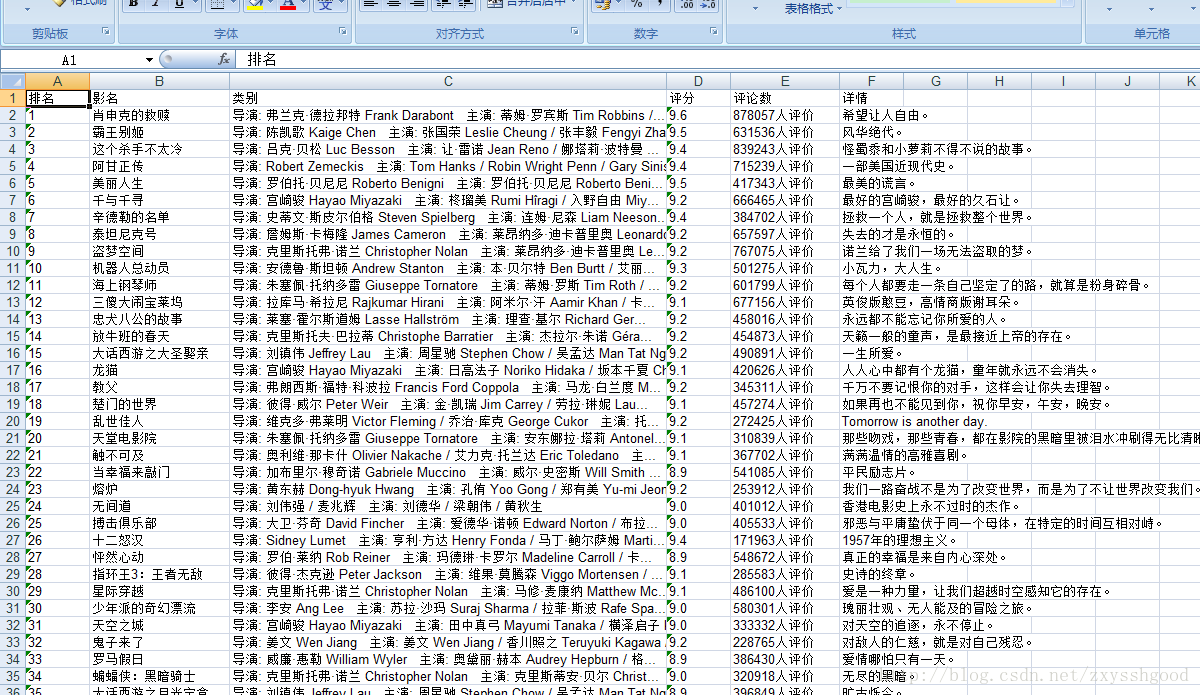
def save_core_data(dataList,filename):
#xlwt是一个扩展的负责写入xls的工具
book= xlwt.Workbook(encoding='utf-8',style_compression=0)
sheet=book.add_sheet("豆瓣最佳评分Top250",cell_overwrite_ok=True)
#可以用sheet.来空值格子的样式等,这里是想把特定几列拉大
sheet.col(1).width=256*20
sheet.col(2).width=800*20
sheet.col(4).width=200*20
col=("排名","影名","类别","评分","评论数","详情")
#第一行把字段名写入
for i in range(0,6):
sheet.write(0,i,col[i])
#循环列表,拿出元组,循环元组拿出需要的数据,并插入到xls中
for i in range(0,250):
for j in range(0,6):
#write(行(第一行是标题,所以+1),列,数据)
sheet.write(i+1,j,dataList[i][j])
j=j+1
#把缓存流写入,在某些编辑器下,filename为中文会乱码,
#用 ‘字符串’.decode('utf-8').encode(sys.getfilesystemencoding())解决
book.save(filename.decode('utf-8').encode(sys.getfilesystemencoding()))
#有些变量可以不用先置空在赋值,但为了便于理解,
#先置空未尝不是一种好事
datalist=[]
#调用程序返回列表
datalist=get_url_content()
#把列表传递给写入方法
save_core_data(datalist,"豆瓣好电影Top250.xls")