Comments-Attached Chinese Microblog Sentiment Classification Based on Machine Learning Technology
Bo Yan, Bin Zhang, Hongyi Su, and Hong Zheng Key Lab of Intelligent Information Technology, Beijing Institute of Technology, Beijing, CN {yanbo,binz,henrysu,hongzheng}@bit.edu.cn
摘要:当今,随着社交网络的迅速发展,以社群为导向的网络情感分析技术在数据挖掘领域成为热门话题。由于其简洁和灵活的特点,微博对情感分析提出了新的挑战。本文根据朴素贝叶斯(NB)和支持向量机(SVM)提出了一个方法,将微博情感分为积极的和消极的。基于数据处理、情感词典构建,结合用户评论的要素,假定附带评论的微博情感分类有助于提高分类的准确性。本实验证明了该方法的有效性和语言表达方式对消极行为的促进作用。
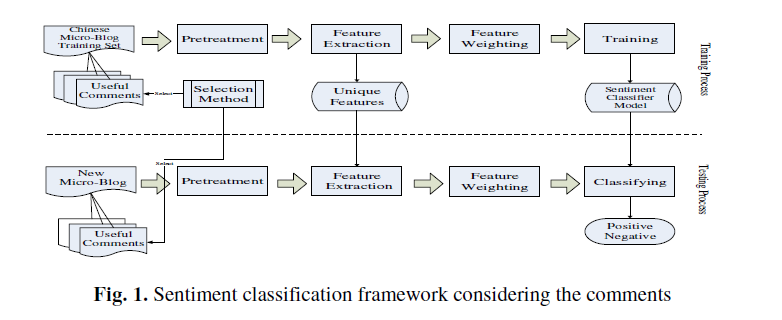
算法
输入:当前批次下带标签的训练集Tn;当前批次下无标签的测试集Un;当前批次下目标微博微博的评论集Cn;
输出:语义指向,O (Un);
要求:分类所用的分类器,Mnb or Msvm;
1.依据选择方法的帮助,从Cn中提取可靠的消极或积极的评论集Vn;
2. Vn = VTn cup VUn,对目标微博样本;
3.借助分级器在Tn ∪VTn上训练模型;
4.在Un ∪VUn中对测试样本进行分级;
5.返回语义指向O (Un)
最终:评估分级器的能力
微博评论选择因素
相关性:评论浏览量(越高关联性越大)
质量:点赞数越多可能有更高的质量,被大多数人同意
时间:评论越早发布,更容易吸引人的注意
通过HowNet来计算语义相关性
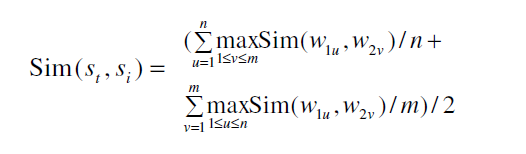
目标微博语句St中有n个单词:w11,w12…w1n,评论语句Si中m个单词:w21,w22…w2m。Sim(w1u,w2v)指两个句子中词与词之间的相关性。
评论的质量包括:评论的热度H、评论的质量Q以及评论的时间维度T。
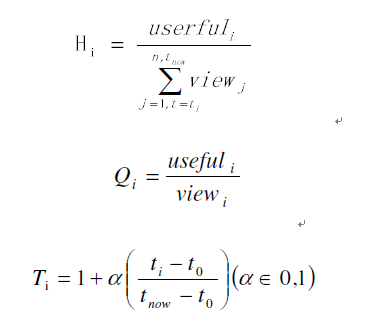
这三个指标代表了这些用户的评论在一定的时间被阅读到,并且在第一程度上公众觉得有用,可以客观地反应该微博的影响力。
在等式Hi和Qi中,userfuli代表了用户认为该评论有用,viewi表示这个评论被浏览的次数。在Ti中,ti表示评论发布的时间,t-now表示该评论被提取的时间,代表的是0-1的常数。
根据上述的各个指标,得出如下公式:
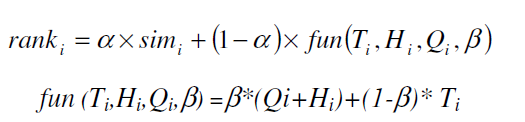
α和β代表0-1的常量,fun (Ti,Hi,Qi,β)代表评论i的质量。
3.2预处理工作
消除非正式语言
NLPIR进行中文分词
特征提取
TF(Term Frequency)和TF-IDF(Term Frequency-Inverse Document Frequency)

特征值权重计算
TF指代特征在文档中出现的次数,TF-IDF修正TF计算方法,使用下述公式将文本和特征结合起来考虑。
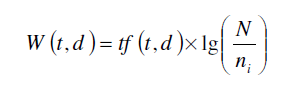
Ni代表文档中单词t的个数
3.3 机器学习方法
Support Vector Machine (SVM)
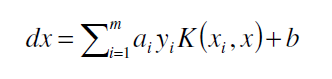
ai和b是由SVM学习算法获得,k (xi,x)代表了核心方法,映射样本到更高的维度当中。当xi中的相关数ai不为0时,样本成为“支持向量”。
LIBSVM被本文用作训练和测试SVM分类器的方法。
Naive Bayes(NB)
贝叶斯算法被用来预测未知的分类样本。在给定的条目y下,加入W1, W2… Wn的可能性如下:
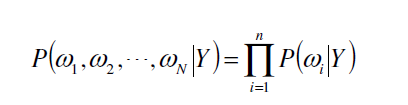
实验数据分析
4.1数据采集
热点话题,数据集包括4000微博,将其分为训练集和测试集。测试集包含3000条目标微博,有1429条积极的,有1571条消极的,测试1000条记录,578积极,422消极。
4.2评估指标
评估指标包含精确率(Precision), 召回率(Recall)和F1-Measure。
召回率是指正确分类的文本占条目下所有文本的比重,
精确率是指正确分类的文本占分配到条目下的比重;
F1-Measure来评估情感分类器的表现。
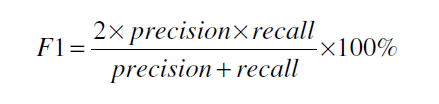
4.3实验过程
1.原始语料预处理:包含降低噪音,分词和在不同情况下(不同的分级器,特征和特征权重计算)的词性标注。基于以下实验结果选择更好地分类器和特征:文本被分成若干子句,并在测试数据中得到句子的极性。最终,微博最终极性(积极还是消极)是由句子的级值相加来获得的。
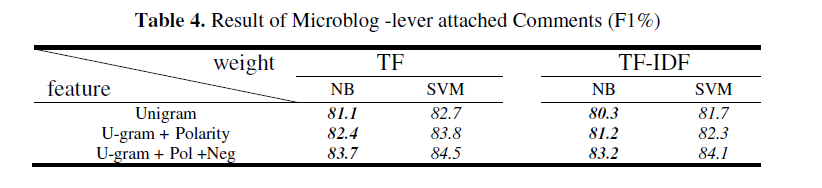
2.语料处理后,将用户评论附加至训练集和测试集当中,再次使用步骤1.
4.4实验结果
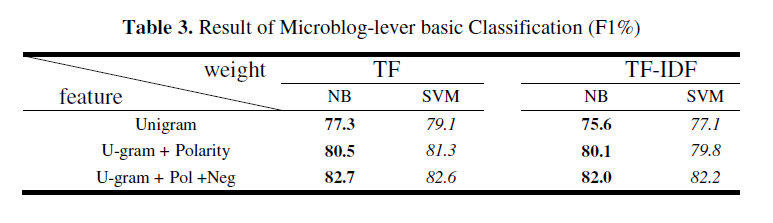
与基于主题的分类不同,情感的分类主要依赖于极性词,这对分类有一定的影响。另外,人们经常用带有极性的词语来表达消极情绪。这些实验结合了3种方法来表达情感特征:多元模型(U-gram),极性词(polarity words-Pol),消极词汇的否定标准(Privative stand for Negative words-Neg)。
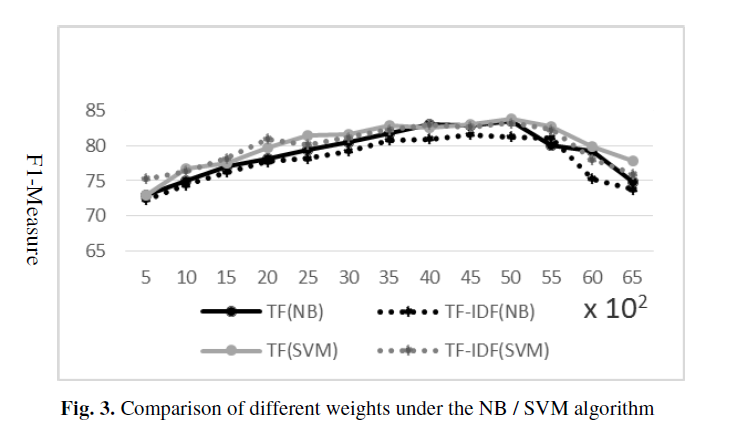
该实验比较了TF和TF-IDF的影响,两种在实验数据上计算权重的方法。还比较了NB和SVM的表现。

4.5实验结论
SVM较好于NB,在特征选取上,多元模型(U-gram)是最重要的特征。
单独使用多元模型的情况下,SVM分类器的综合评价指标(F1-measure)达到了82.7%,在添加情感极词和否定前缀后,这一指标增长了2%,达到了84.5%。
在特征值计算中,TF较好与TF-IDF,添加处理后的评论信息后,该论文提出方法的精确率达到了85.6%,综合评价指标达到了84.5%,是令人满意的结果。