机器学习训练营——机器学习爱好者的自由交流空间(qq 群号:696721295)
集成方法(Ensemble methods)的目标是,组合多个基础估计量的预测结果,以此改善单个估计量预测的通用性和稳健性。集成方法通常分为两大类:
平均的方法:独立地构建多个估计量,然后平均它们的预测。一般来说,组合的估计量要优于任何一个基础估计量,这是因为它的方差减小了。例如,
Bagging methods.boosting方法:为了减少组合估计量的偏差,按顺序构建基础估计量,目的是为了组合几个弱估计量成一个强有力的集成方法。例如,
AdaBoost.
Bagging 元估计量
在集成方法里,bagging方法组成了一类算法,它在原始的训练数据集的随机子集上创建一个黑箱(black-box)估计量的多个实例,然后聚集这些实例的预测为一个最终的预测。这类方法主要是为了减少一个基础估计量的方差(比如说,决策树)。通过在构建过程里引入随机化,然后再集成。在很多情况下,bagging方法只是改善一个模型,而不必修正基础算法。bagging方法可以有效地减少过度拟合,因此它对于复杂模型表现出色。Bagging方法有很多分支,它们的主要区别在对训练集的随机子集抽取上。
当随机子集作为样本的随机子样本被抽取时,这类算法称Pasting.
当样本有放回抽取时,这类算法称Bagging.
当随机子集作为特征的随机子集被抽取时,这类算法称Random Subspaces.
当基础估计量构建在样本和特征的双重子集时,这类算法称Random Patches.
在scikit-learn里,bagging法实现类BaggingClassifier, 输入用户自定义的基础估计量,由参数指定随机子集的抽取方式。特别的,max_samples and max_features 控制子集的大小(根据样本和特征),而bootstrap and bootstrap_features控制样本和特征是否有放回抽取。当使用一个可利用样本的子集时,设置oob_score=True, 通用准确率(generalization accuracy)可以使用out-of-bag样本估计。下面的例子演示怎么样实例化一个bagging集成KNeighborsClassifier. 每一个基础估计量构建在50%的随机样本和50%的随机特征上。
from sklearn.ensemble import BaggingClassifier
from sklearn.neighbors import KNeighborsClassifier
bagging = BaggingClassifier(KNeighborsClassifier(),
max_samples=0.5, max_features=0.5)随机树森林
sklearn.ensemble模块包括两个基于随机决策树的平均算法:随机森林算法和Extra-Trees方法。这两种算法都是针对树设计的扰动+组合技术。这意味着,通过在分类器构造过程中引入随机化,产生多样的分类器集。然后,平均这些分类器的预测而得到最后的集成预测。像其它分类器一样,随机森林分类器也必须输入两个数组:大小[n_samples, n_features]的X, 装载训练样本;长度为[n_samples]的Y, 装载训练样本的类标签。
from sklearn.ensemble import RandomForestClassifier
X = [[0, 0], [1, 1]]
Y = [0, 1]
clf = RandomForestClassifier(n_estimators=10)
clf = clf.fit(X, Y)随机森林
在随机森林里,集成的每棵树都构建于一个训练集的有放回抽样的样本,即,一个bootstrap样本。另外,在建树期间分割一个节点时,被选择的分割不再是对于所有特征是最好的分割,而是对一个特征的随机子集最好的分割。随机化的结果,森林通常会稍微增加分类的偏差。但是,由于平均的作用,方差也减小了。两相比较,产生总体上较好的模型。与原始文献提出的随机森林比较,scikit-learn通过平均概率预测组合分类器,而不是根据每个分类器的投票结果。
极端随机树
ExtraTreesClassifier and ExtraTreesRegressor类执行极端随机树(extremely randomized trees). 就像随机森林,一个候选特征的随机子集被使用,但极端随机树并不像随机森林那样寻找最有区别性的阈值,而是对每一个候选特征随机抽取阈值,选择最好的阈值作为分割的规则。这样通常会使模型方差减小的程度更大,付出的代价是稍微增加了预测偏差。


参数
这些方法使用的主要参数是n_estimators and max_features, n_estimators确定森林里树的棵数,越大越好,但也增加了计算时间。另外也要注意,如果超过树的棵数预设值,结果不会更好。max_features确定分割一个节点时,特征的随机子集大小。它的值越小,方差减小的越大,但也增加了预测偏差。从经验上看,对于回归问题,好的默认值是ax_features=n_features. 对于分类任务,好的默认值是max_features=sqrt(n_features). 当设置max_depth=None, min_samples_split=2, 经常会得到好的结果。请牢记:尽管这些参数值通常并不是最优的,可能导致模型消耗大量内存。最好的参数值应该总是经过交叉验证的。还有要注意的是,在随机森林里,默认使用的是bootstrap样本(bootstrap=True), extra-trees默认策略是使用整个数据集(bootstrap=False).
特征重要性评价
对于用作树的决策节点的特征,使用特征的相对秩(即深度)评价该特征对于目标变量的预测性的相对重要程度。树顶的特征贡献最终的预测决策。它们贡献的样本的期望比例,能被用来作为特征相对重要性的估计。下面的例子显示了在人脸识别中,每一个像素(特征)的相对重要性的彩色编码表示。

实际上,这些估计存储在拟合模型的feature_importances_属性里。它是一个形如(n_features,)的数组,值是正的,加和等于1。值越大,特征越重要。
AdaBoost
模块sklearn.ensemble包括主流的boosting算法AdaBoost. 该算法的核心原理是,在反复修改的数据上拟合一个弱学习器序列,这里的”弱学习器”,是指表现略好于随机猜测的模型,例如,小的决策树。然后,所有的预测通过一个加权投票组合,产生最终的预测。在每一步所谓的boosting迭代的数据修改,指的是应用权
到每一个训练样本。这些权初始都设置为
, 以便第一步简单地在原始数据上训练一个弱学习器。对随后的依次迭代,样本权逐个修改,学习算法被重新应用到重加权的数据上。在给定的步,那些被上一步的boosting模型错误预测的例子的权值增加,而正确预测的例子权值减小。随着迭代进行,难于预测的例子受到不断增长的影响。因此,随后的每一个弱学习器被迫专注于之前被错误预测的例子上。AdaBoost能够用于分类和回归的问题。
使用方法
下面的例子演示怎样拟合一个100个弱学习器的AdaBoost分类器。
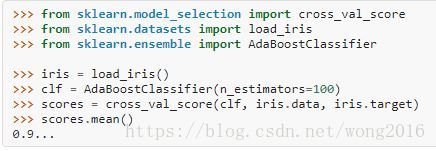
弱学习器数受参数n_estimators控制。learning_rate参数控制弱学习器在最终组合里的贡献。不同的弱学习器能够通过参数base_estimator指定。主要的参数是n_estimators和基础估计量复杂度,例如,深度参数max_depth, 决策树的叶子节点最少样本数min_samples_leaf.
Gradient Tree Boosting
Gradient Tree Boosting 或 Gradient Boosted Regression Trees (GBRT) 将boosting推广到任何不同的损失函数。GBRT是一个用于分类和回归问题的准确、高效、现成的程序。Gradient Tree Boosting模型也被广泛使用在网页搜索排秩和生态学。
GBRT的优势是:
混合型数据的自然处理;
预测力强;
对于输出空间的异常点是健壮的。
GBRT的不足是:
可测量性,由于顺序的boosting特性,GBRT很难并行执行。
分类
GradientBoostingClassifier 支持二类或多类的分类问题。下面的例子显示怎样拟合一个100棵树的gradient boosting分类器。
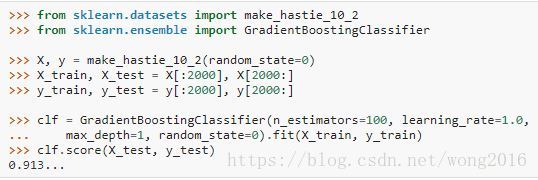
弱学习器的数量受参数n_estimators控制;每棵树的大小或者由参数max_depth设置树深,或者通过参数max_leaf_nodes设置叶子节点数。learning_rate是一个(0, 1]内的超参数,控制过度拟合的程度。
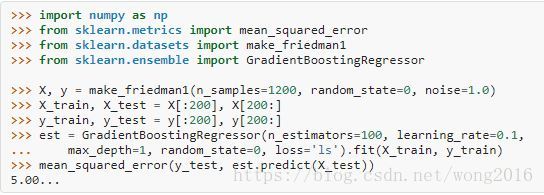
回归
GradientBoostingRegressor支持不同的回归损失函数,由参数loss指定。默认的损失函数是最小二乘ls.
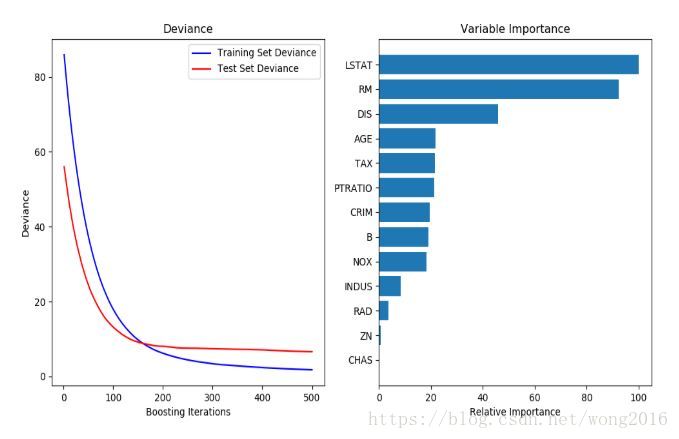
下图显示的是应用500个基础学习器的GradientBoostingRegressor到Boston房价数据集上的回归结果。左图显示的是每一步迭代的训练和检验误差,训练误差存储在模型的train_score_属性里,检验误差由staged_predict方法获得,该方法返回一个生成器,产生每一步的预测。这种图能被用来确定最优的树棵数。右图显示由feature_importances_属性得到的特征重要性。
拟合额外的弱学习器
GradientBoostingRegressor and GradientBoostingClassifier都支持warm_start=True, 它允许增加更多的估计量到已经拟合的模型里。

控制树深
基于基础学习器的回归树大小定义了变量的相互作用水平。通常,有两种方式控制每棵回归树的大小。
如果指定max_depth=h, 那么将训练深度 的完全二叉树。这种树至多有 个叶子节点, 个分割节点。
你也可以通过参数max_leaf_nodes指定叶子节点数,控制树大小。在这种情况下,使用best-first建树,具有最高不纯度改善的节点将被优先分割。一棵max_leaf_nodes=k的树,有k-1个分割节点。
我们发现,max_leaf_nodes=k与max_depth=k-1得到的结果差不多,但是max_leaf_nodes=k的训练速度快而训练误差稍高。
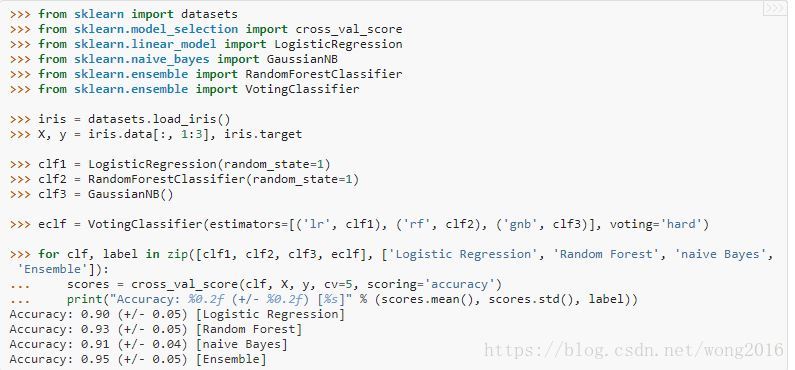
投票分类器
VotingClassifier的思想是,组合概念上不同的机器学习分类器,使用大多数投票或平均预测概率预测类标签。对于表现同样出色的模型集,为了抵消它们各自的弱点,使用这样的分类器是有效的。
大多数类标签
在大多数投票机制里,对于一个特定样本的预测类标签,是各个分类器预测的类标签中占大多数的那个类标签。举个例子,如果一个给定样本的预测是:
classifier 1 -> class 1
classifier 2 -> class 1
classifier 3 -> class 2
根据大多数类标签,投票分类器将样本分到类1.
用法
下面的例子显示怎样拟合大多数规则分类器。
加权平均概率
相比较大多数投票(hard voting), soft voting返回具有最大预测概率和的类标签。特定的权由参数weights分派给每一个分类器。当提供权的时候,每个分类器预测的类概率被收集,乘以分类器的权,再平均。最终的类标签由具有最高平均概率的类标签决定。举个例子,假设我们有3个分类器和一个3-类的分类问题。我们给所有分类器分派等值的权: . 一个样本的加权平均概率计算如下:

这里,预测类标签是2,因为它有最高的平均概率。
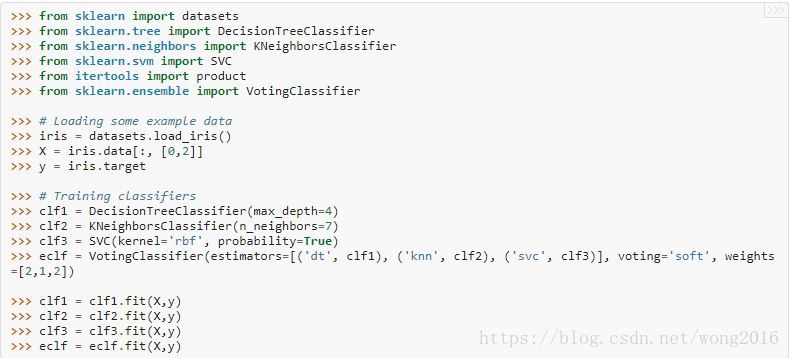
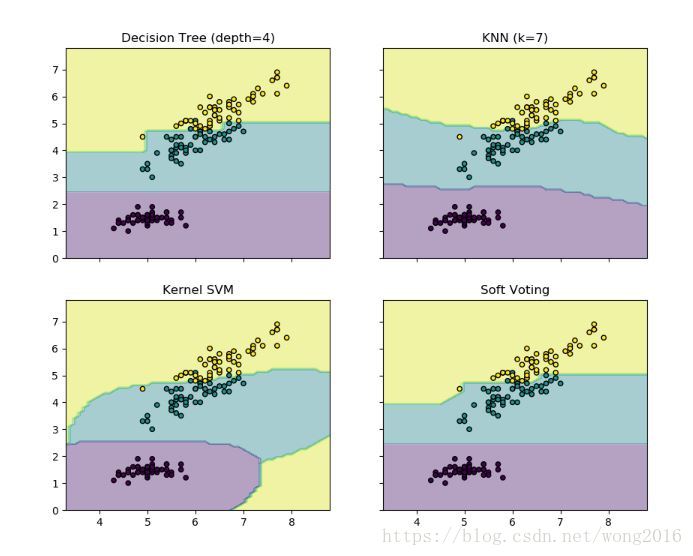
下面的例子演示,当使用加权平均概率,分类器分别使用线性支持向量机、决策树、k-近邻时,
决策区域是如何改变的。
阅读更多精彩内容,请关注微信公众号:统计学习与大数据