有一段时间没有写 Erlang 程序了,近日有个小伙伴要帮忙,给了我几个小练习,让我写写看。虽然写得有点慢,毕竟还是完成了。突发灵感,Erlang有没有什么“编程套路”呢?
初学 Erlang 者大部分都感叹“太逆天了”,个人认为,掌握Erlang 编程逻辑两个基本点就是模式匹配和递归思想。而递归思想在任何一种编程语言中都是存在的,也是解决问题最简便的思维方式。
就着这个练习,其实之前好像也有过一次接受过类似问题的求助,对照我的思考总结一下:
习题如下:
格式化元组:
输入:[{money,200},{goods,1001,1},{goods,71143,9},{money,150},{rmb,600},{goods,71143,1},{goods,1001,1},{card,3001,281479271678954},card,4001,281479271678955}]
输出:[{money,350},{goods,[{1001,2},{71143,10}]},{rmb,600},{card,[{3001,281479271678953},{4001,281479271678955}]}]
我的代码如下图(此程序没有对输入数据格式的检查):
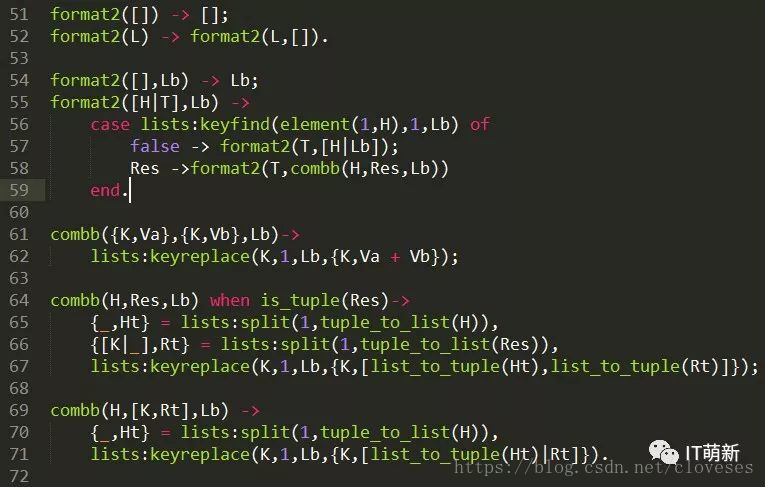
其基本思想是对要解决的问题进行分类,分别编写一个子句,每个子句中的函数头部括号中模式匹配部分(参数部分)就是描述解决复杂问题的一种情况的入口(当然,还可以辅之以保护式),而函数体则是解决这一种情况下的所有处理语句。这些处理语句又大致分为两类:
1.可以直接返回处理结果。这也是程序运行结束的情况,或者用递归的思想看就是退出递归的条件。
比如本例中的第51行代码:
format2([]) -> [];
当传入要格式化的列表为空时,直接返回空的列表。
再如第54行代码:
format2([],Lb) -> Lb;
元组列表中的元素全部处理完成后,直接返回结果列表。
而代码中61-71行中的combb函数则每个子句都是处理一类问题,并直接返回处理结果的情况。
2.需要递归处理,以获取最终结果。即经本轮处理后,要处理的问题减少了,但并没有获得最终结果,还是要经过多轮递归调用,将要处理的问题减少到0,即递归退出的条件,最终会返回结果。
本例代码中的combine函数(55-59)中的57、58行就是这种情况:从55行的模式匹配就可以看出,通过模式匹配逐个处理输入元组列表中的元组,只要没有处理完,在57、58行中就会进行递归调用(此处正好对应在结果列表中可以找到有对应Key和无对应Key的两种情况),每次递归调用就会处理掉所给列表中的一个元组,直到处理完成后会通过模式匹配方式调用第54行的子句并返回处理结果。
再看我解决这个问题的另一版本:

第30行就是上文中说的第一种情况,第32行就是递归调用;comba函数(35-44)子句中,前三个子句都是处理可直接返回结果的,第四个子句(44行)则是递归调用,尝试继续匹配。
还有一个套路补充下,就是通过增加函数的元数来接收处理结果。比如52行、58行、32行等。
最后,说明一下,写 Erlang 函数时还要注意模式匹配的顺序,不要让前面子句的模式匹配挡住了后面子句。原则就是先做特殊匹配,再做一般匹配。
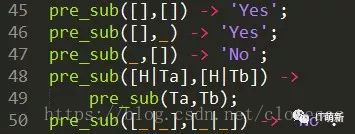
下面再来个粟子:
查询List1是为List2的前缀
先将问题分类:
1. 两个列表都为空,结果为是;
2. 前一个列表为空,后一个不为空,结果为是;
3. 前一列表不为空,后一个为空,结果为否;
4. 两个列表不为空,且第一个元素相同,需要继续查询(递归调用);
5. 两个列表不为空,且第一个元素不同,结果为否。
对照下面的程序是不是就一目了然了呢?
不当之处,敬请斧正。