KVM的优化
1.1 cpu的优化
- inter的cpu的运行级别,(Ring2和Ring1暂时没什么用)Ring3为用户态,Ring0为内核态
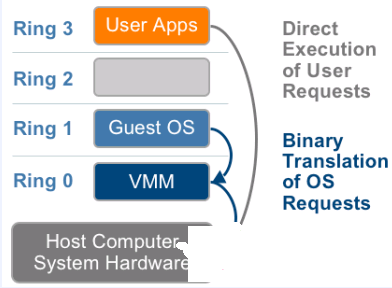
Ring3的用户态是没有权限管理硬件的,需要切换到内核态Ring0,这样的切换(系统调用)称之为上下文切换,物理机到虚拟机多次的上下文切换,势必会导致性能出现问题。
对于全虚拟化,inter实现了技术VT-x,在cpu硬件上实现了加速转换,CentOS7默认是不需要开启的
- cpu的缓存绑定cpu的优化
[root@linux-node1 qemu]# lscpu|grep cache L1d cache: 32K L1i cache: 32K L2 cache: 256K L3 cache: 6144K
L1是静态缓存,造价高,L2,L3是动态缓存,通过脉冲的方式写入0和1,造价较低。cache解决了cpu处理快,内存处理慢的问题,类似于memcaced和数据库。如果cpu调度器把进程随便调度到其他cpu上,而不是当前L1,L2,L3的缓存cpu上,缓存就不生效了,就会产生miss,为了减少cache miss,需要把KVM进程绑定到固定的cpu上,可以使用taskset把某一个进程绑定(cpu亲和力绑定,可以提高20%的性能)在某一个cpu上,例如:taskset -cp 1 25718(1指的是cpu1,也可以绑定到多个cpu上,25718是指的pid).
cpu绑定的优点:提高性能,20%以上
cpu绑定的缺点:不方便迁移,灵活性差
1.2 内存优化
内存寻址:宿主机虚拟内存 -> 宿主机物理内存
虚拟机的虚拟内存 -> 虚拟机的物理内存
为了实现客户机物理地址到主机物理地址的地址翻译,VMM为每个虚拟机动态维护了一张从客户机物理地址到宿主机物理地址的映射关系表。客户机OS所维护的页表只是负责传统的客户机虚拟地址到客户机物理地址的转换。如果MMU直接装在客户机操作系统所维护的页表进行内存访问,硬件则无法实现地址翻译。
影子页表是一个有效的解决办法。一份影子页表与一份客户机操作系统的页表相对应,作用是实现从客户虚拟机地址到宿主机物理地址的直接翻译。这样,客户机所能看到和操作的都是虚拟MMU,而真正载入到MMU的是影子页表。如下图:

由于客户机维护的页表真正体现在影子页表上,因此,客户机对客户机页表的操作实质上反映到影子页表中,并且由VMM控制,因此,影子页表中,对于页表页的访问权限是只读的。一旦客户机对客户机页表进行修改,则产生页面异常,由VMM处理。
Inter在最新的Core I7系列处理器上集成了EPT技术(对应AMD的为RVI技术),以硬件辅助的方式完成客户物理内存到机器物理内存的转换,完成内存虚拟化,并以有效的方式弥补了影子页表的缺陷,该技术默认是开启的
EPT异常处理流程
在客户机物理地址到宿主机物理地址转换的过程中,由于缺页、写权限不足等原因也会导致客户机退出,产生 EPT 异常。对于 EPT 缺页异常,KVM 首先根据引起异常的客户机物理地址,映射到对应的宿主机虚拟地址,然后为此虚拟地址分配新的物理页,最后 KVM 再更新 EPT 页表,建立起引起异常的客户机物理地址到宿主机物理地址之间的映射。对 EPT 写权限引起的异常,KVM 则通过更新相应的 EPT 页表来解决。
EPT 页表相对于前述的影子页表,其实现方式大大简化。而且,由于客户机内部的缺页异常也不会致使客户机退出,因此提高了客户机运行的性能。此外,KVM 只需为每个客户机维护一套 EPT 页表,也大大减少了内存的额外开销。