Anchor策略:
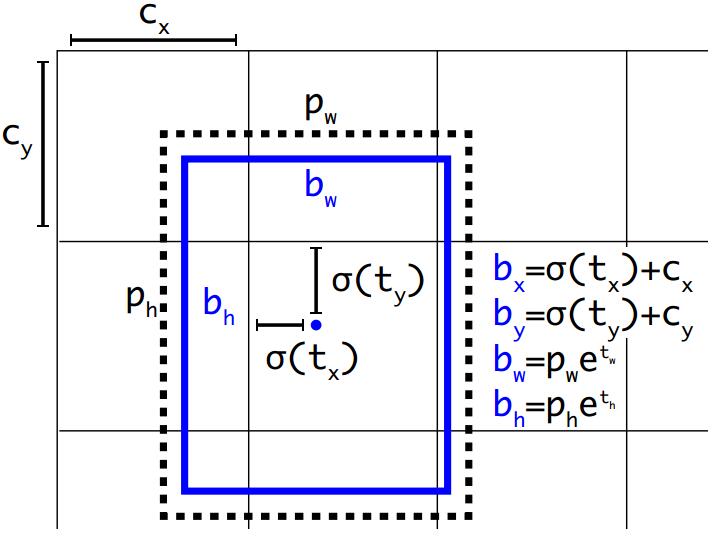
yolov3延续了yolov2的anchor策略,基本没有变化。
边框的表示方式通过框的中心坐标bx,by,和框的宽bw,高bh这4个变量来表示。实际预测的值为tx,ty,tw,th。
由tx,ty,tw,th得到bx,by,bw,bh的详细公式如上图,其中,
cx,cy为框的中心坐标所在的grid cell 距离左上角第一个grid cell的cell个数。
tx,ty为预测的边框的中心点坐标。
σ()函数为logistic函数,将坐标归一化到0-1之间。最终得到的bx,by为归一化后的相对于grid cell的值
tw,th为预测的边框的宽,高。
pw,ph为anchor的宽,高。实际在使用中,作者为了将bw,bh也归一化到0-1,实际程序中的 pw,ph为anchor的宽,高和featuremap的宽,高的比值。最终得到的bw,bh为归一化后相对于anchor的值
σ(t0)表示预测的边框的置信度,为预测的边框的概率和预测的边框与ground truth的IOU值的乘积。
这里有别于faster系列,yolov3只为ground truth 匹配一个最优的边界框。
分类损失函数:
yolov3中将yolov2中多分类损失函数softmax cross-entropy loss 换为2分类损失函数binary cross-entropy loss 。因为当图片中存在物体相互遮挡的情形时,一个box可能属于好几个物体,而不是单单的属于这个不属于那个,这时使用2分类的损失函数就更有优势。
多尺度预测:
Yolov3采用了类似SSD的mul-scales策略,使用3个scale(13*13,26*26,52*52)的feature map进行预测。
有别于yolov2,这里作者将每个grid cell预测的边框数从yolov2的5个减为yolov3的3个。最终输出的tensor维度为N × N × [3 ∗ (4 + 1 + 80)] 。其中N为feature map的长宽,3表示3个预测的边框,4表示边框的tx,ty,tw,th,1表示预测的边框的置信度,80表示分类的类别数。
和yolov2一样,anchor的大小作者还是使用kmeans聚类得出。在coco数据集上的9个anchor大小分别为:(10× 13); (16× 30); (33× 23); (30× 61); (62× 45); (59×119); (116 × 90); (156 × 198); (373 × 326)
使用多尺度融合的策略,使得yolov3的召回率和准确性都有大的提升。
Backbone骨架:
和yolov2的19层的骨架(Darknet-19 )不同,yolov3中,作者提出了53层的骨架(Darknet-53 ),并且借鉴了ResNet的shortcut结构。
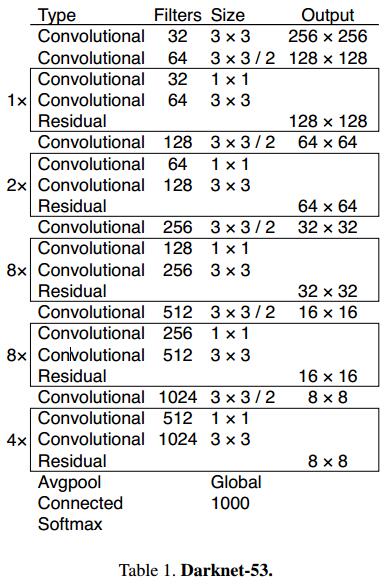
上图为论文中的网络结构,但是卷积层只有52层,和作者实际的程序还是有点出入。为此,自己根据作者的程序撸了一个,主干网络还是52层。
yolov3-tiny:
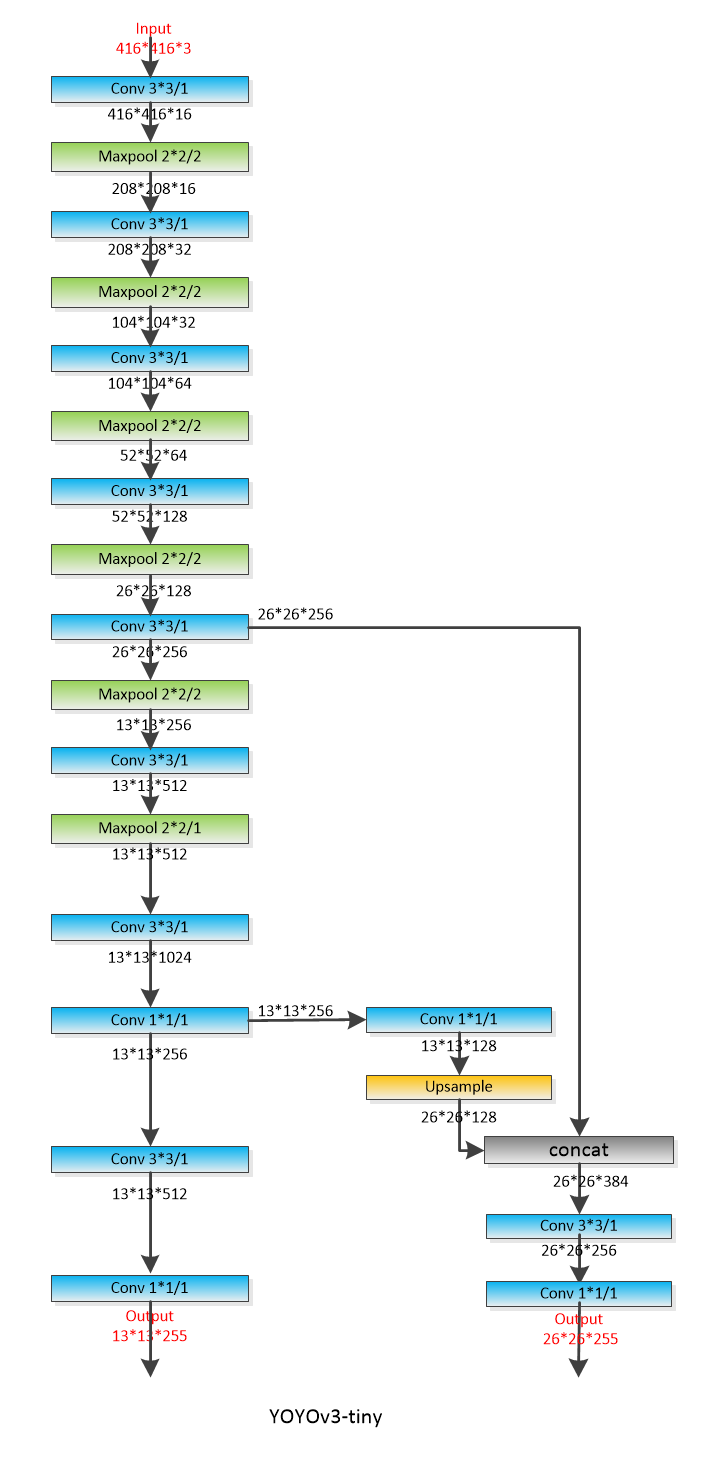
yolov3:

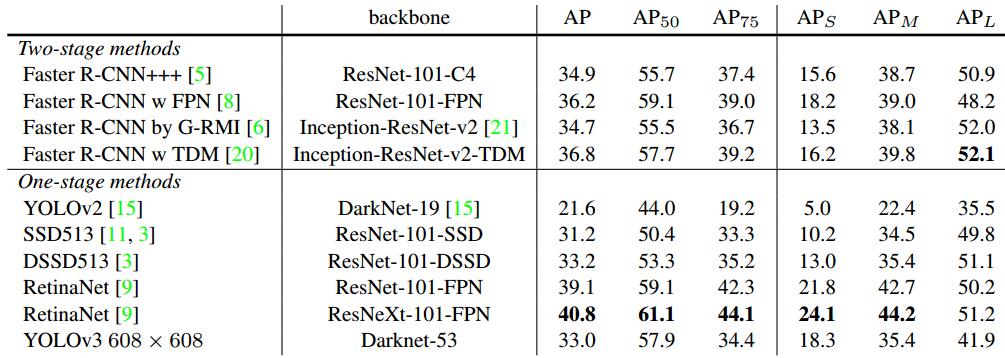
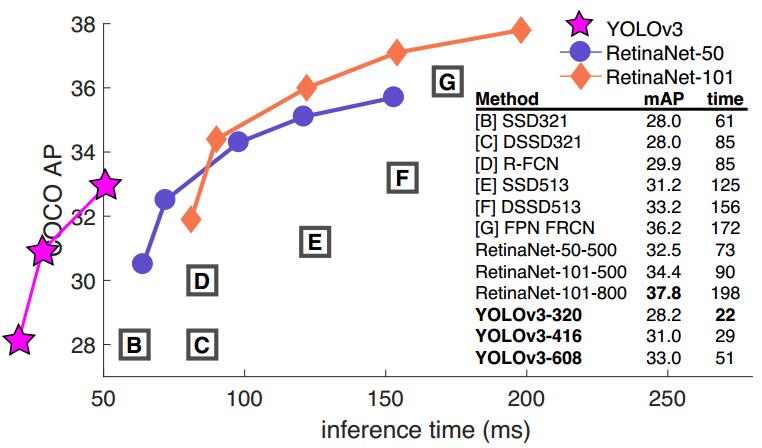
精度vs速度:
Yolov3的精度和速度都达到的空前的高快。
在分类任务中,以darknet-53的骨架网络,速度是ResNet-152的2倍,精度也基本相当。
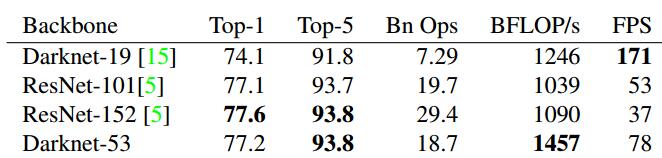
在检测任务中,当IOU标准定为0.5时,只比RetinaNet低3.2%个点。在IOU标准定为0.75时,比RetinaNet低9.7%个点。其实这个问题也是yolo一直存在的一个问题,在相对比较小的检测物体上,会存在检测框不是很准的想象。速度方面比RetinaNet快出3倍多。
RUN:(测试显卡为P40)
git clone https://github.com/pjreddie/darknet
cd darknet
Make -j32
wget https://pjreddie.com/media/files/yolov3.weights
wget https://pjreddie.com/media/files/yolov3-tiny.weights
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg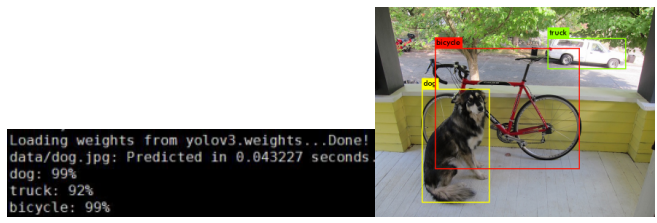
./darknet detect cfg/yolov3-tiny.cfg yolov3-tiny.weights data/dog.jpg
References:
https://pjreddie.com/darknet/yolo/
https://github.com/pjreddie/darknet