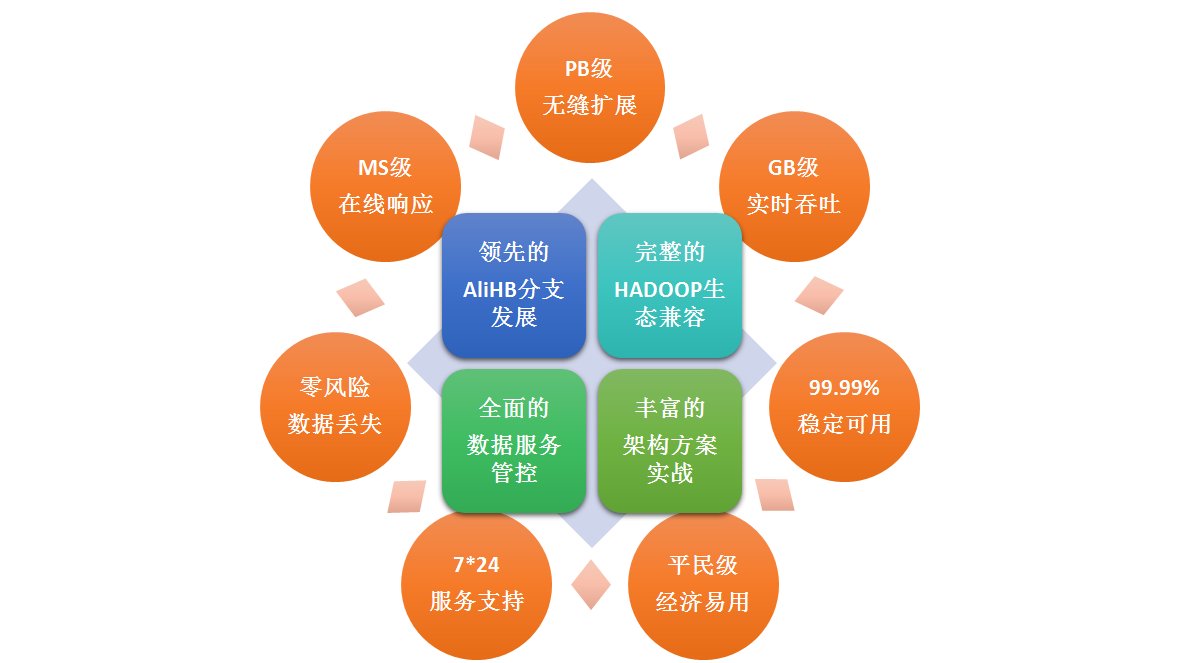
产品功能
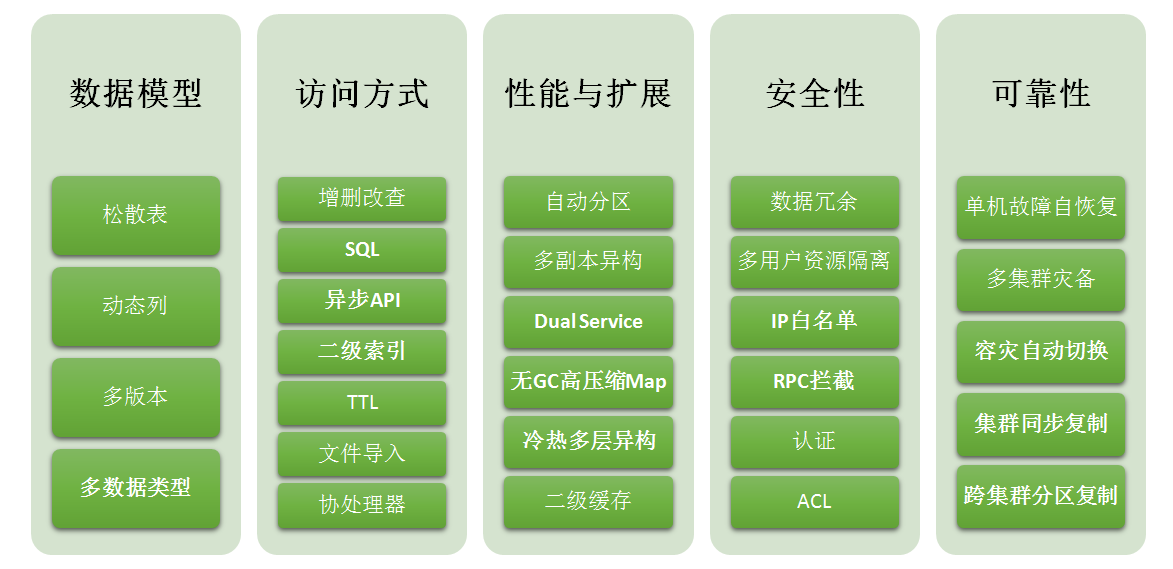
产品简介
概述
定位:面向大数据场景的高可靠、高性能、高伸缩的分布式结构化存储系统
HBase – Hadoop Database,是一个高可靠性、高性能、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
Ali-HBase,基于阿里巴巴/蚂蚁的环境和业务需求,对社区HBase进行深度定制与改进,从软件系统、解决方案、稳定护航、发展支撑等全方位提供一站式大数据基础存储服务。
它是以松散表的形式组织数据,提供实时更新、增量导入、随机查询、范围查询、多维删除能力,与实时计算、离线计算、流计算高度集成,高扩展、高可用、高可靠、高性能、高适应的在线分布式NoSQL数据库
基本架构
HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable利用 Chubby作为协同服务,HBase利用Zookeeper作为对应。

基本特点
- 数据模型
- 松散的表Schema,列的名字、数目、长度无需定义
- 数据类型:唯一支持字节数组(byte[])
- 支持多版本
- 支持多数据类型
- 访问方式
- 实时写入/更新/删除,支持批量、异步等方式
- 后台导入,直接生成存储格式的文件,十分高效
- 设置数据有效期,过期自动删除
- 指定主键(Row)的随机查询
- 有条件(为主键或列设定条件)的范围查询
- 协处理器 (类似于RDB中的触发器与存储过程)
- 事务:支持单行、同分区跨行的事务
- 索引:主键索引,支持局部二级索引
- 数据强一致性,强持久性
- 程序语言支持:原生客户端仅支持JAVA,C、PHP等可以通过代理方式访问(自带Thrift框架)
- 支持SQL
- 支持异步API
- 与JStorm/Galaxy集成,支持基于HBase的实时流计算
- 性能与扩展
- 水平扩展,支持千台物理机级规模
- 扩容无需数据迁移,即扩即用
- 大表自动分裂,支持分区在线合并
- 扩展能力依赖表分区,Row设计需要防热点
- 存储层采用LSM树,相比于B-Tree(读写对等),写能力>读能力
- 支持多副本异构介质存储
- 支持二级缓存
- 安全与稳定
- 存储层默认三副本,数据可靠性高
- 支持表快照,方便冷备
- 系统内部采用M-S架构
- Master支持热备,Master故障影响DDL,不影响DML
- Slave故障,影响可用性,部分数据区域的DML不可用,会自动恢复
- 支持双集群数据复制
- 支持用户认证与授权
- 支持集群一键切换和自动切换
- 支持单元化多地多集群部署
- 数据导入导出
- 跨系统,支持导入/导出CSV格式的数据
- 同系统,支持distcp直接拷贝底层存储文件,快速导入
- 使用sqoop,在HBase/mysql/orcale/hive等系统间相互迁移数据
- 与在云端集成,支持HBase与其他系统的数据全量/增量迁移
- 与TT和ODPS集成,支持HBase上的数据实时生产到TT,供其他订阅方消费,并支持同步到ODPS上,进行实时计算
- 运维与服务
- 完善的监控与报警
- 全链路请求追踪
- 7*24一站式服务
使用场景
- 结构化数据
- 场景描述:用户的前台数据实时读写HBase,如交易记录、评价记录、物流记录等
- 案例代表:支付宝消费记录、菜鸟物流详情
- 高吞吐写入
- 场景描述:日志、消息、监控、聊天等需要高吞吐实时写入的数据存取
- 案例代表:AliMonitor、集团TimeTunel、旺旺聊天
- 海量数据实时访问
- 场景描述:安全风控场景,在/离线写入大量用户行为数据,实时查询判断行为风险
- 案例代表:蚂蚁风控、集团安全
- 大数据实时计算
- 场景描述:数据BI、实时运营等场景,流计算、批量计算的结果实时回流到HBase,供在线访问
- 案例代表:媒体大屏、生意参谋、蚂蚁服务宝
Ali-HBase与社区HBase的关系与区别
- 社区HBase是一个开源软件,Ali-HBase是定制软件、解决方案、护航配套、服务支撑的集合
- 与阿里/蚂蚁的环境高度集成,享受一站式的数据场景服务,支撑这个服务的系统包括云平台(业务接入、资源管理、集群管控、数据运营)、监控报警、高可用切换、数据流动与计算支撑系统等,经过业务多年锤炼的配套体系,满足业务拎包入住
- Ali-HBase拥有的超越社区版本的独有能力
- 可用性:可达99.99%,全年不可用<1小时
- 完善的集群间异步复制,支持多单元、表级复制、延迟/拓扑可视等功能,更加地稳定、高效(性能提升1倍)
- 支持集群数据的同步复制
- 切换系统,支持一键切换、自动切换
- 深度优化的宕机恢复能力,快N倍
- 稳定性:多年沉淀,久经双11沙场
- 功能性:深耕需求,独特风景
- 二级索引
- 新缓存BucketCache,支持二级缓存
- 资源分组隔离,支持多租户
- 冷热分级存储
- 异步API,提高吞吐
- 内置计算,高效支持数据的聚合、校正、清洗
- 反向Scan
- OffsetScan,以支持分页
- 支持请求级超时
- 离散式TTL
- 支持SQL,数据类型、全局二级索引、热点消除等能力尽在SQL层
- 运维性:一切尽在掌握
- 核心模块和关键链路的完善监控
- 请求的全链路跟踪与调试
- 多级请求控制能力:限制、隔离、拒绝
- 对业务完全透明的数据搬迁
- 性能:深入场景的提升,优秀源于大体量的锤炼
- 多副本异构介质混合存储
- 内存自管理Map,深度优化GC
- 双集群双活架构,请求稳定性提升一个数量级
- Compaction算法的深度改进
- Small Scan
- C/S传输压缩,HLog压缩
- 前缀BloomFilter
- 上百个细节优化
- 灵活性:易流动,易计算
- 异构系统间的数据全量/增量/实时迁移
- 数据实时同步ODPS,定期计算
- JStorm/Galaxy,支持基于HBase的实时流计算
- 可用性:可达99.99%,全年不可用<1小时
产品优势
易用
- 无需部署与维护,直接使用数据服务
- 丰富监控与报表,轻松优化应用
- 专业团队提供支持
可扩展
- 弹性高效的水平扩展
稳定可靠
- 多副本的高可靠保障
- 支持冷备和热备
- 节点故障自动恢复
持续可用
- 主备架构
- 同城容灾
- 多地容灾
- 支持一键切换和自动切换
深入整合
- 与实时计算、离线计算、流计算高度整合
- 集成于在云端,支持异构系统间的数据迁移
成本
- 深入场景的性能优化
- 无需基础(网络、机器)和系统运维